
前面《数据湖系列(八)Apache Hudi源码编译》我们已经编译了相关的hudi版本。这里的编译主要是为了匹配相关的hadoop、hive、flink、spark等组件的版本,如果我们的这些组件使用的是原始的hudi源码的版本,那么是不需要进行编译的,直接使用即可。
在实际的使用中,hudi由于主要是依赖于hadoop,所以这里我们只需要有一个hdfs的环境即可,这里我们已经把环境安装好了,示例图如下:
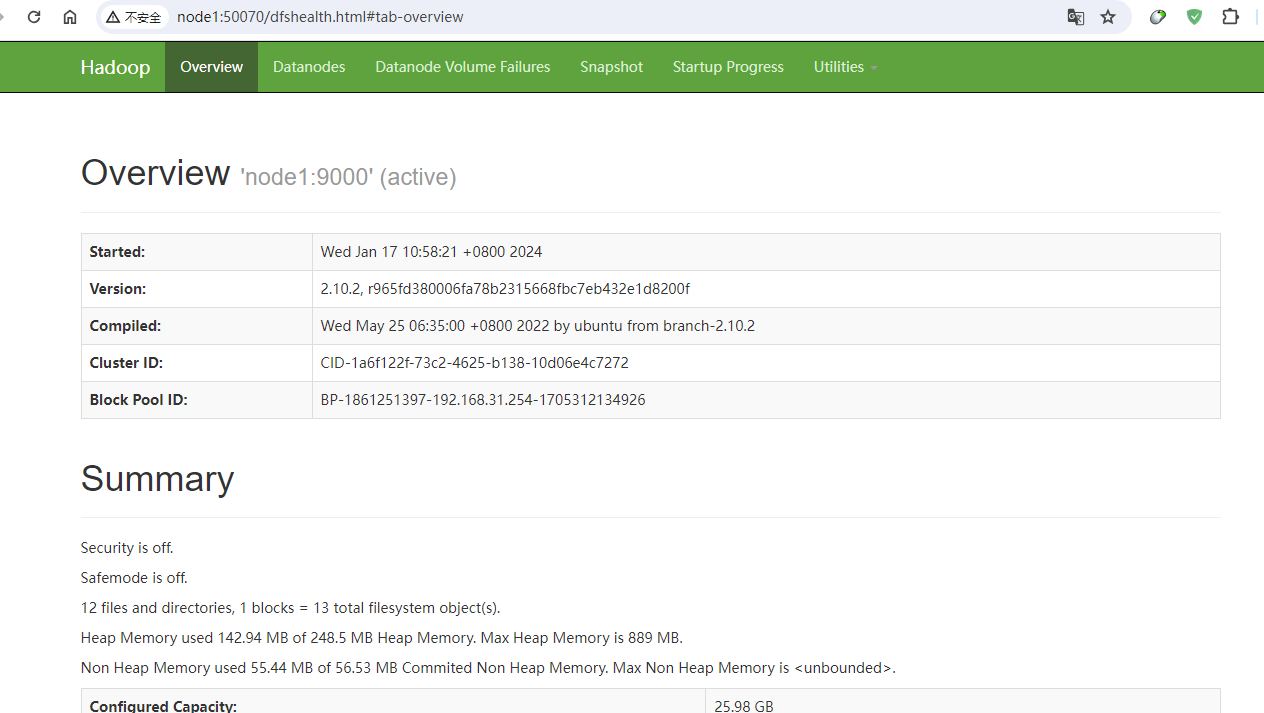
接着我们开始来演示如何使用spark程序向hudi中插入数据。示例如下:
1)创建maven项目,并且引入pom依赖:
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
<version>4.4.4</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
<exclusions>
<exclusion>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpcore</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!--连接Hive 需要的包,同时,读取Hudi parquet格式数据,也需要用到这个包中的parqurt相关类 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hudi</groupId>
<artifactId>hudi-spark-bundle_2.12</artifactId>
<version>0.14.1</version>
</dependency>
</dependencies>2)创建源目录
这里我们要创建两个源目录,分别是:src/main/scala,src/main/resources。
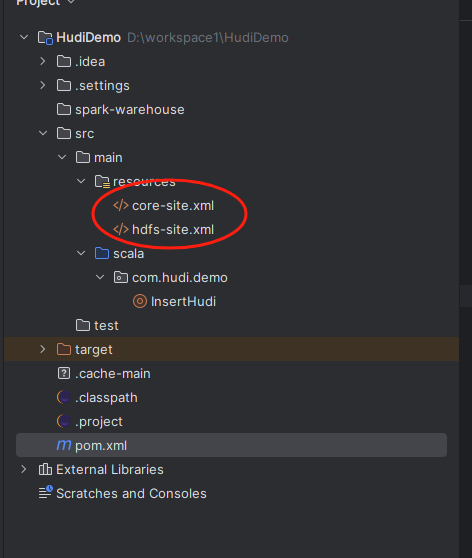
3)引入hadoop配置
接着我们把线上环境的hadoop集群配置文件的core-site.xml和hdfs-site.xml文件拷贝到src/main/resources文件夹下,示例图如下:
4)编写spark插入hudi的示例代码:
//创建spark json,使用本地模式进行存储
val session: SparkSession = SparkSession.builder()
//本地模式运行
.master("local")
//job名称
.appName("InsertHudi")
//设置spark的序列化
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取json文件,创建DataFrame,这里的users.txt文件存放在src/main/resources里面的
val insertDF = session.read.json("file:///D:\\aaaa\\users.txt")
//将结果保存到hudi中
insertDF.write.format("org.apache.hudi") //或者直接写hudi
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "id")
//设置写并行度设置,默认1500
.option("hoodie.insert.shuffle.parallelism", "1")
//设置update并行度设置,默认1500
.option("hoodie.upsert.shuffle.parallelism", "1")
//设置表名
.option(HoodieWriteConfig.TABLE_NAME, "users")
.mode(SaveMode.Overwrite)
//存储到hdfs上的路径,这里需要把hdfs的core和hdfs-site配置文件放在src/main/resources目录下。
.save("/hudi_data/users")5)测试运行spark代码,示例图如下:
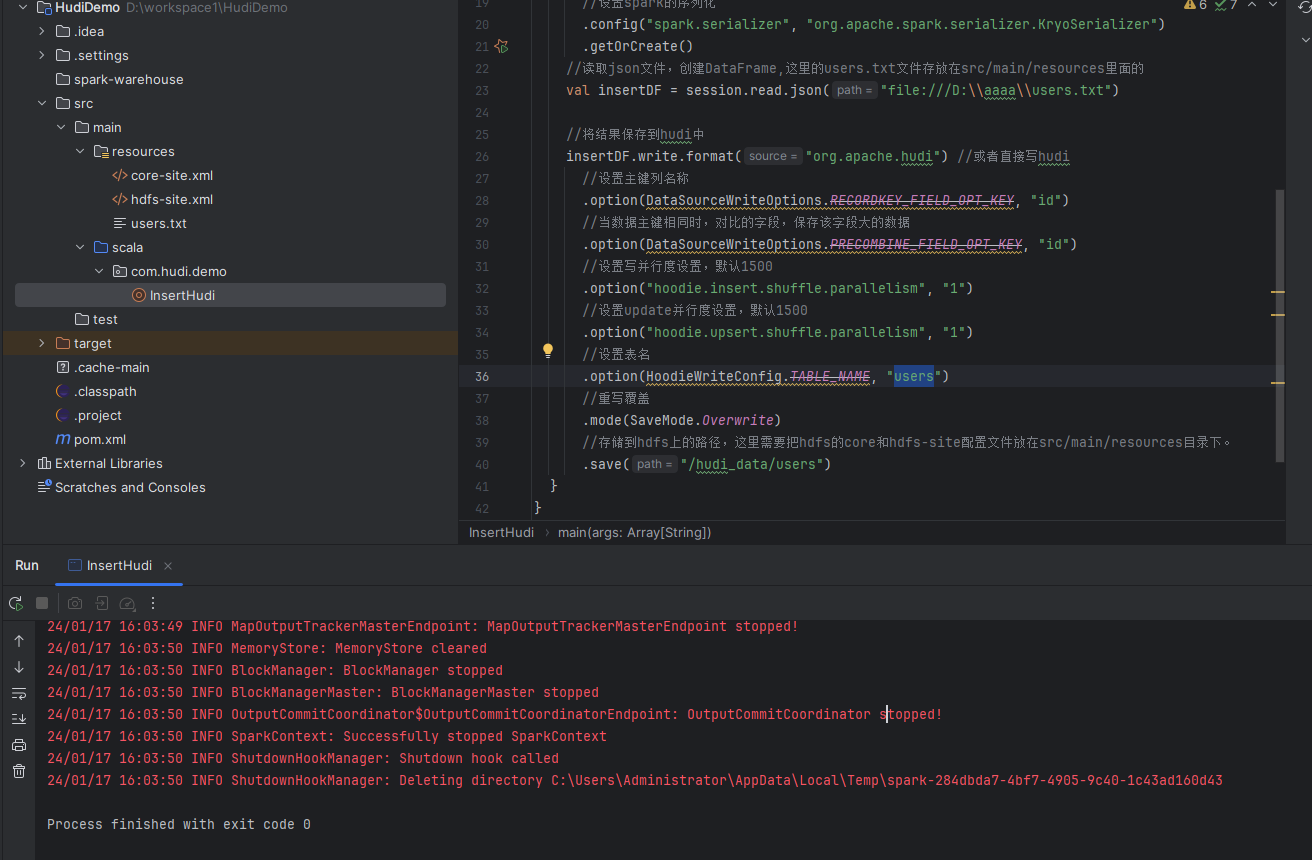
此时我们在去hdfs上查看/hudi_data/users的文件夹,示例图如下:
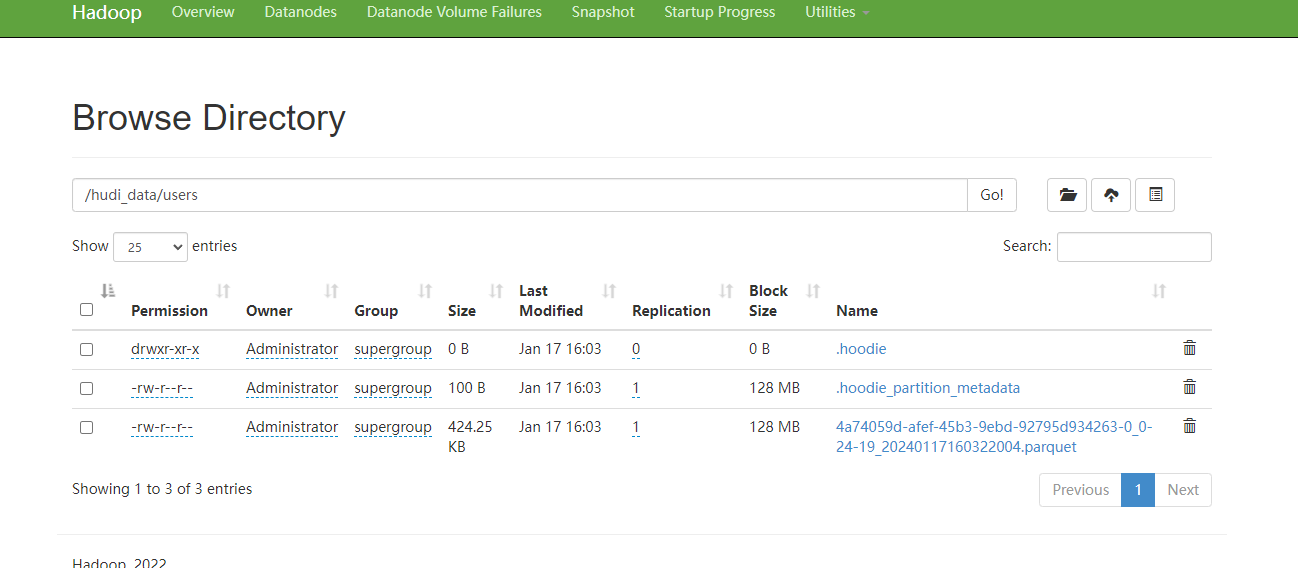
可以看到数据已经写入到hdfs上了。
备注:
1、hudi只是一个数据湖框架,真实的数据还是存储在hdfs上的。 2、写入hudi的时候,我们要尽量把原始数据做成对应的json数据结构,这样子相当于以json的key组合成hudi的表。 3、这里我们的spark程序是在本地执行的,如果有兴趣的话,可以把当前的spark程序打包后放到spark集群中执行查看对应的效果。
以上就是关于使用spark把数据写入hudi的案例,最后按照惯例,附上本案例的源码,登陆后即可下载。








还没有评论,来说两句吧...