
上文《数据湖系列(九)使用spark程序向Apache Hudi插入数据》我们已经实现了使用spark程序向hudi写入数据了,本文的话我们来演示下从hudi中读取相关的数据。所以示例如下:
1)准备maven项目
这里我们还是使用上文的maven项目,包含里面的依赖等,示例如下:
2)创建读取hudi类
这里我们创建一个读取hudi的类,名称为FindHudi。里面具体的实现代码如下:
val session: SparkSession = SparkSession.builder()
//使用本地模型跑测试
.master("local")
//job名称
.appName("FindHudi")
//设置spark的序列化,这一步很重要,不然要报错
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//加载hudi仓库的表数据
val frame: DataFrame = session.read.format("hudi").load("/hudi_data/users")
//创建临时视图
frame.createTempView("users")
//查询结果
val result = session.sql(
"""
| select id,name from users
""".stripMargin)
//在控制台显示结果
result.show(true)3)运行测试
接着我们来运行测试一下,看下控制台是否会输出查询的users表结果,示例如下:
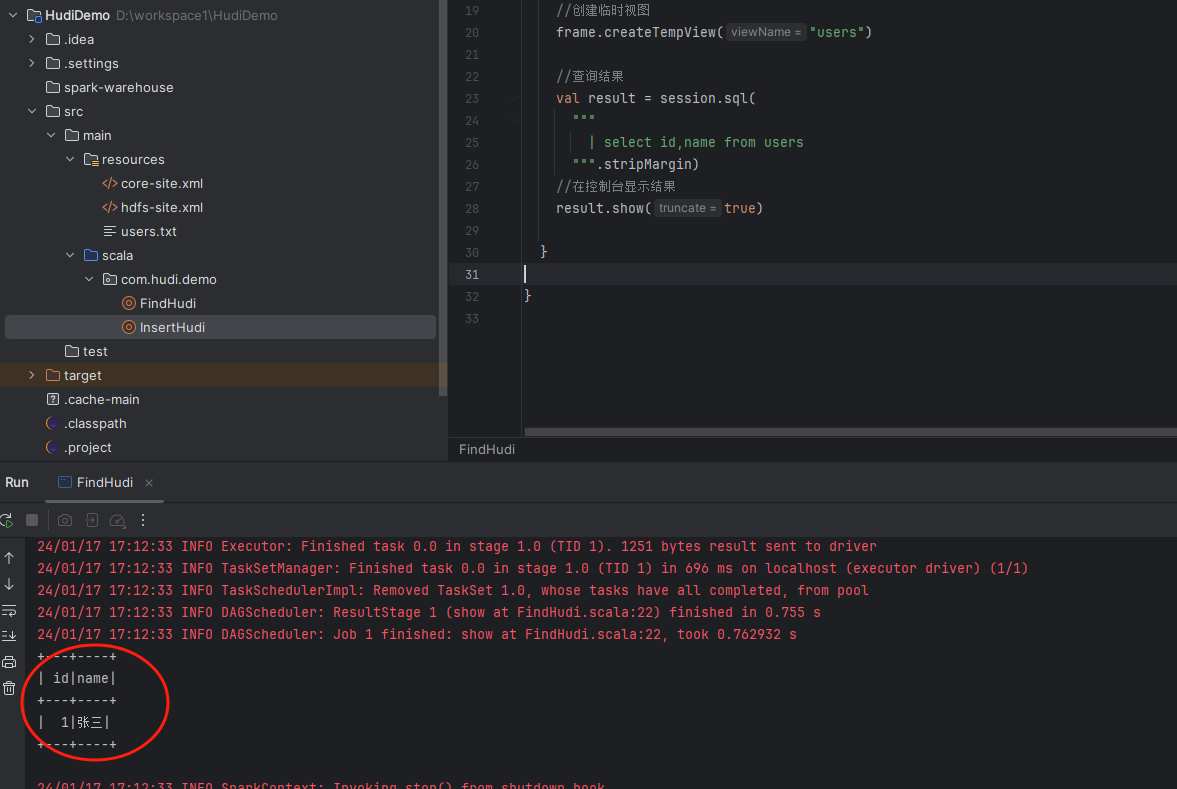
可以看到没有任何问题。
备注:
1、这里我们查询Hudi的数据主要步骤如下: 1)创建sparksession 2)加载hudi表目录(hdfs的目录) 3)创建临时视图 4)编写sql查询临时视图 5)显示结果。 2、切记进行config配置的时候需要实现序列化的配置。 3、sql里面我们可以编写成select *,这样子可以显示更多的字段信息,多余的字段信息相当于是元数据。
以上就是我们使用spark读取hudi的数据案例,最后按照惯例,附上本案例的源码,登陆后即可下载。








还没有评论,来说两句吧...