
接上篇《构建一个完整的数据仓库(十一)doris的索引》。在前面我们在介绍doris的时候,主要使用的是insert into给大家做数据导入的演示,但是我们也说过,doris在真实的环境中,我们不会直接使用insert导入,因为这样效率是非常低下的。今天这篇文章我们就来介绍下如何把数据导入到doris里面。
一、insert into的方式
insert into的方式我们已经介绍过了,分两种,一种是直接insert into数据到表里面,例如:
insert into user values(1,'张三',0.27,'2022-04-20 14:30:00')
还有一种方式是:
insert into user2 select userid,username from user1;
第二种insert into的方式是生产中经常使用的。这里是从其他源表里面查询出来数据,把对应的数据导入到新表里面。这里不能完全理解user2shi源表的子集,因为查询源表的时候,可能我们会使用join这些操作。建议熟悉多操作一下这种插入方式即可。
二、Stream load
stream load 这种方式在生产上也使用的比较多,这里主要是在本地或者其他可以访问的地方存在一个数据集,一般我们以csv格式为主,然后通过命令,或者ui的方式把这些数据通过 http 把数据注入到对应的表里面去。下面来演示一下.
1)创建一张student表
CREATE TABLE `student` ( `id` bigint(20) NULL COMMENT "id", `name` varchar(20) NULL COMMENT "姓名", `age` TINYINT NULL COMMENT "年龄", `class` varchar(20) NULL COMMENT "班级" ) ENGINE=OLAP DUPLICATE KEY(`id`,`name`,`age`,`class`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" )
然后我们在本地创建一个text,然后加一些数据,文件扩展名是txt的
1,张三,15,k2班 2,李四,16,K3班 3,王五,9,M2班
然后我们使用命令的方式导入数据
curl --location-trusted -u root -T /root/aaa/student1.txt -H "label:stu1" -H "column_separator:," http://192.168.31.30:38030/api/test1/student/_stream_load
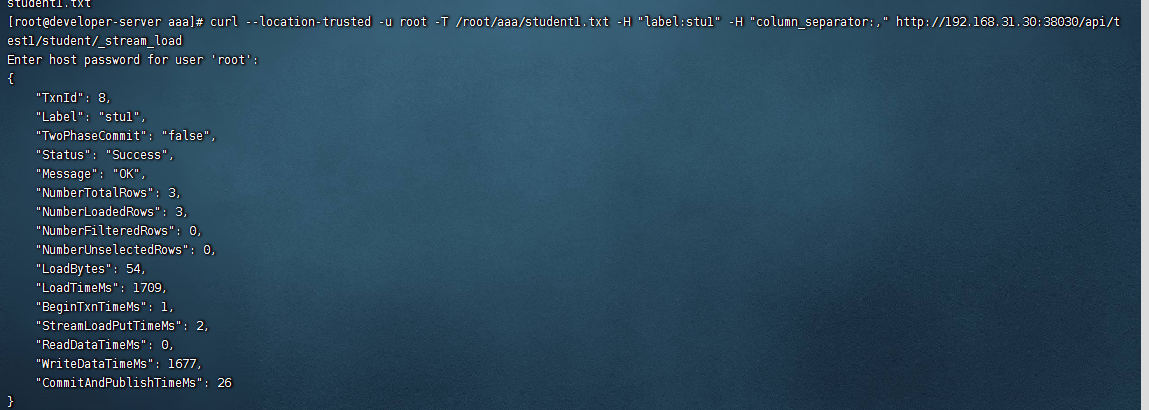
看到了吧,导入成功了,此时我么去查询一下。
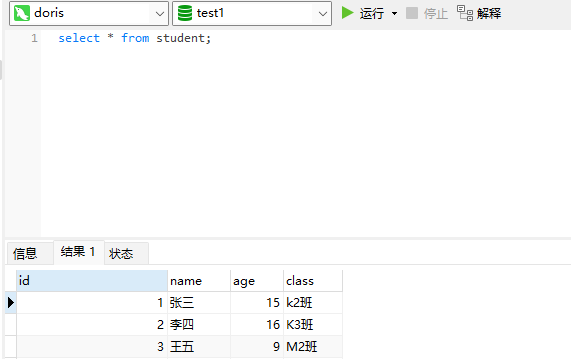
导入成功了,当然我们也可以直接在页面上进行导入,访问:http://192.168.31.30:38030/Playground
然后在左侧选择对应的表,然后选择dataimport
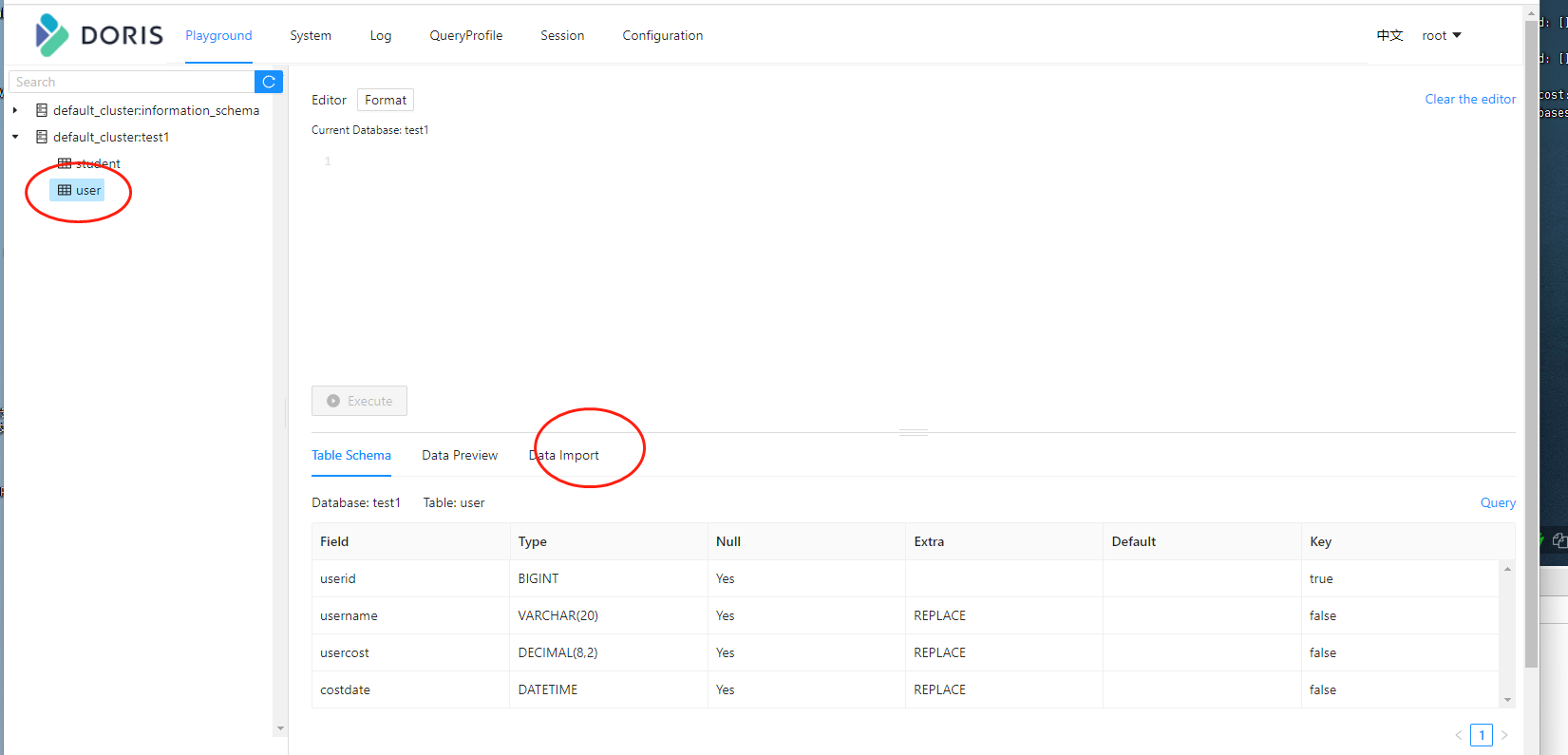
然后点击下一步,选择分割符为”,”,上传文件。
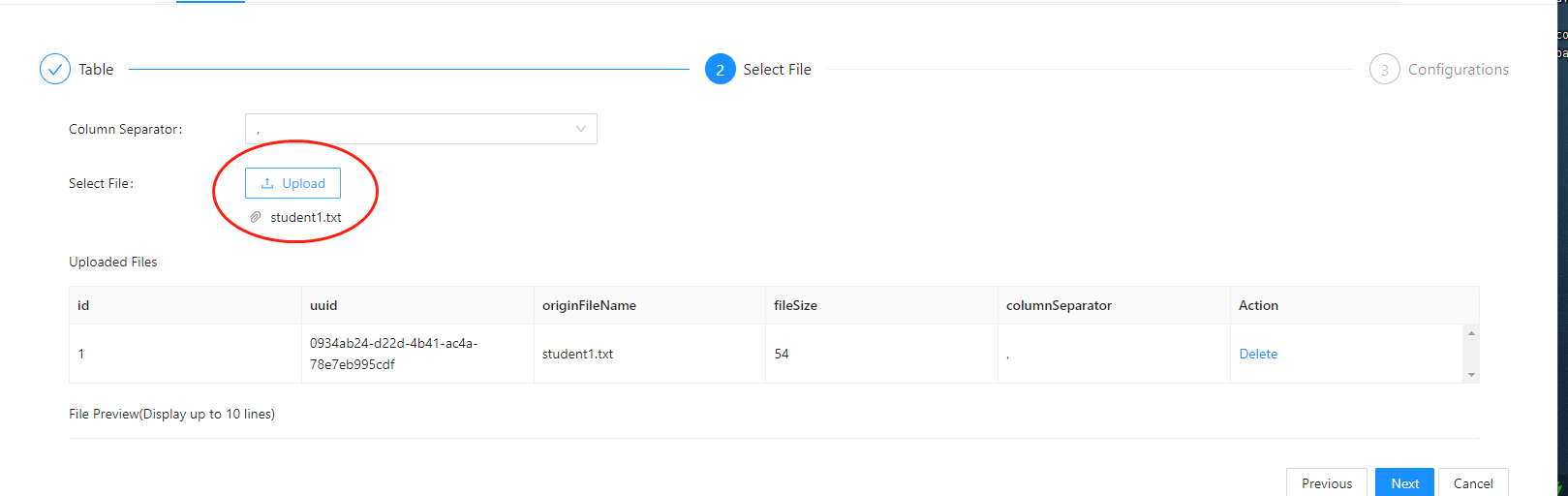
然后继续点下一步
label随便写,然后点import

这里会提示导入成功
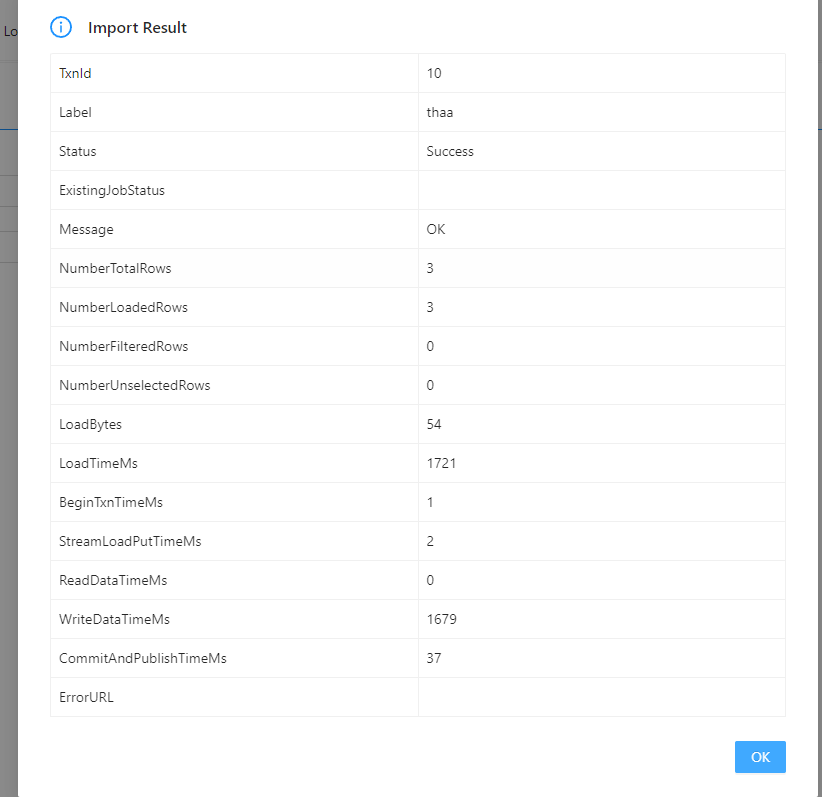
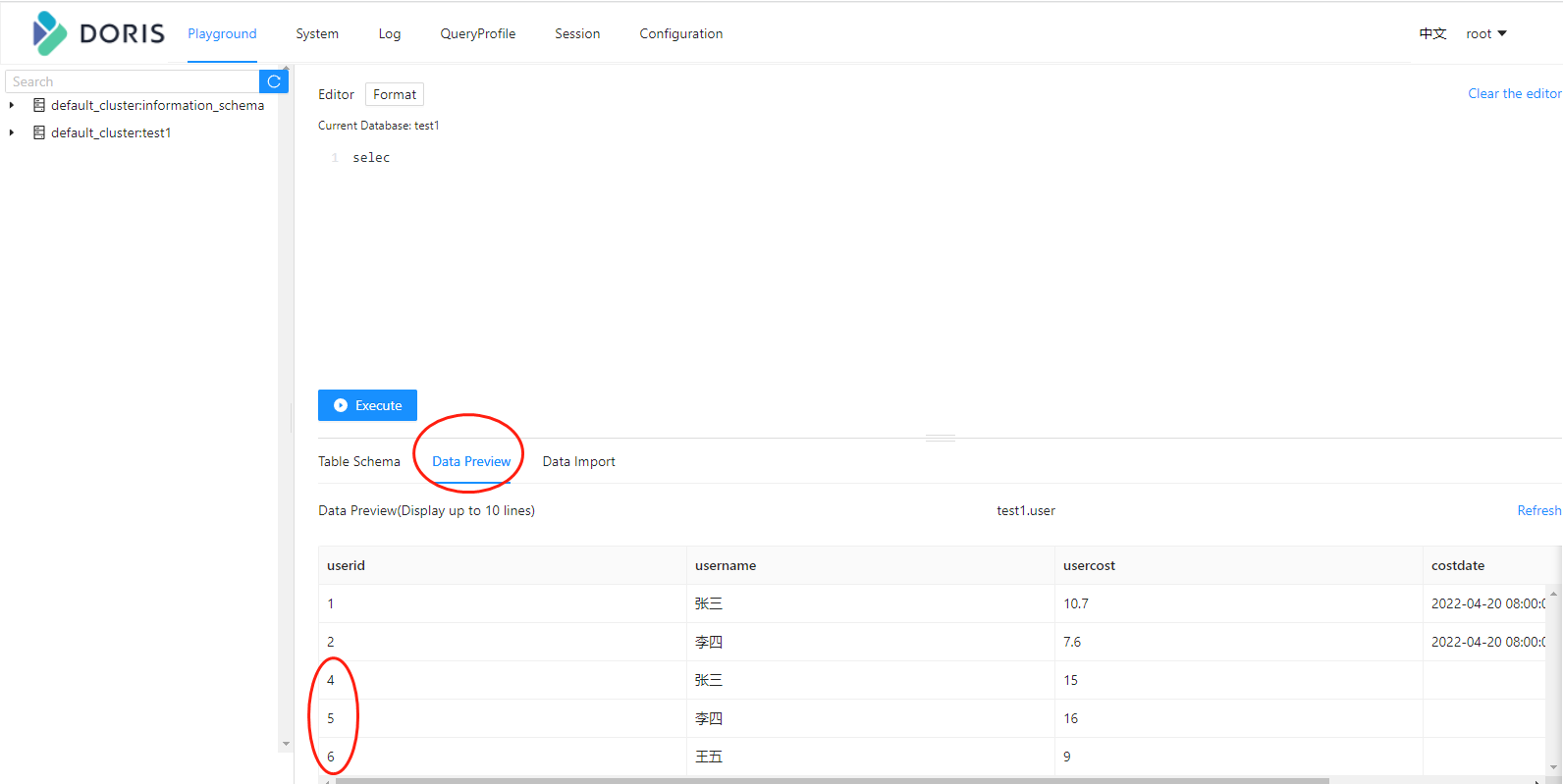
然后去查询结果就可以了
三、kafka订阅导入数据
首先在我们的环境里面没有kafka,所以我们临时使用docker安装一个kafka
docker pull zookeeper docker pull bitnami/kafka docker run --name zookeeper -p 2181:2181 -itd --restart=always --privileged=true wurstmeister/zookeeper docker run --name kafka -p 9092:9092 -itd --restart=always --privileged=true -e KAFKA_BROKER_ID=0 -e KAFKA_ZOOKEEPER_CONNECT=192.168.31.30:2181 -e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://127.0.0.1:9092 -e KAFKA_LISTENERS=PLAINTEXT://127.0.0.1:9092 wurstmeister/kafka
然后我们创建一张student的表
CREATE TABLE `student` ( `id` bigint(20) NULL COMMENT "id", `name` varchar(20) NULL COMMENT "姓名", `age` TINYINT NULL COMMENT "年龄", `class` varchar(20) NULL COMMENT "班级" ) ENGINE=OLAP DUPLICATE KEY(`id`,`name`,`age`,`class`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" )
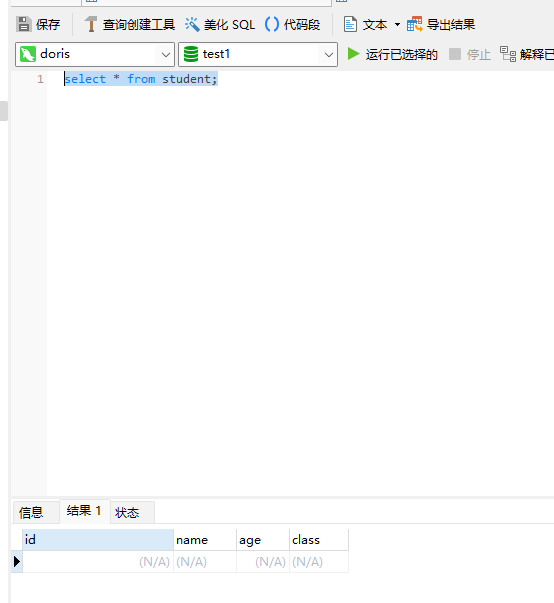
然后我们查询一下,保证当前student没有数据
然后我们创建一个ROUTINE
CREATE ROUTINE LOAD test1.studenttxtjob ON student COLUMNS TERMINATED BY "," PROPERTIES ( "max_batch_interval" = "20", "max_batch_rows" = "300000", "max_batch_size" = "209715200" ) FROM KAFKA ( "kafka_broker_list" = "192.168.31.30:9092", "kafka_topic" = "student1", "property.group.id" = "student1", "property.client.id" = "student1", "property.kafka_default_offsets" = "OFFSET_BEGINNING" );
然后使用
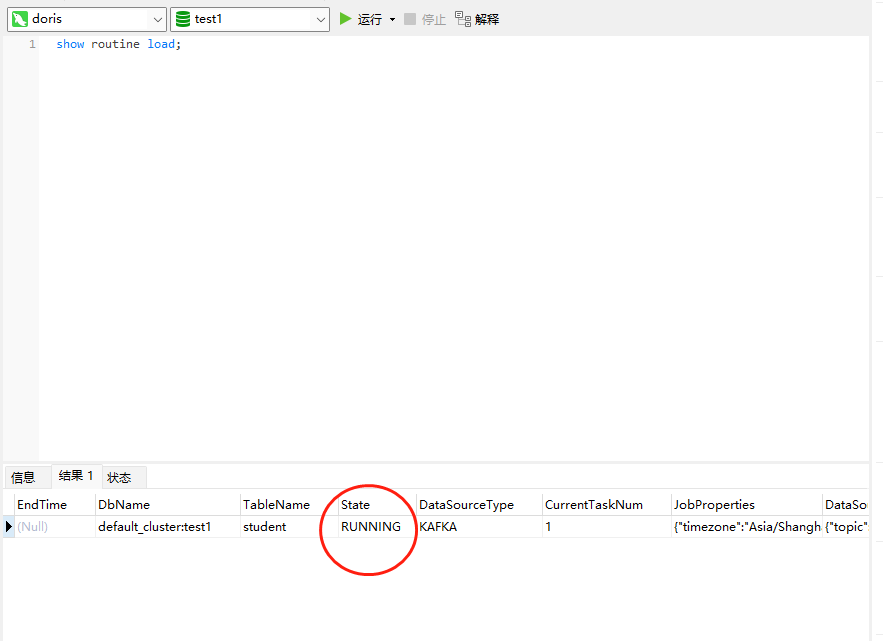
show routine load;
可以看到我们的routine load是running的状态,代表成功了。
然后我们在docker的kafka里面发送数据。
docker exec -it kafka bash kafka-console-producer.sh --broker-list 127.0.0.1:9092 --topic student1 4,张三,15,k1班
再去查询数据
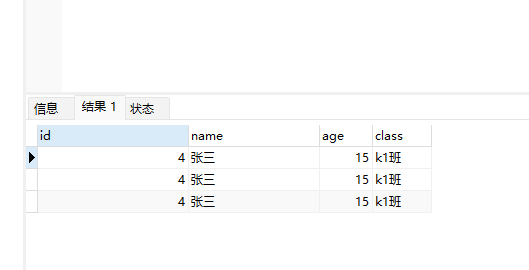
数据都进来了。
好了,我们今天就介绍这三种导入数据的方式,接下来下一篇我们介绍更多的数据导入方式。








还没有评论,来说两句吧...