
在上一篇文章《CDC工具Canal的安装并且使用JAVA客户端读取数据变更》我们介绍了搭建canal服务端,然后使用java程序监听数据的变化。在使用java客户端监听的时候,在大数据了的场景下这个就不合适了,因为并发增大不起来,就会造成数据延迟,所以一般我们在使用kafka的时候,都会把canal的数据发送到消息队列里面去,这样的话,可以增大并发量,避免数据的堆积。
目前canal支持的消息中间件有:
1、kafka 2、rocketMQ 3、rabbitMQ 4、pulsarMQ
大家根据实际情况使用就是了,这里我们演示对接kafka,那么我们就需要修改canal服务端的配置文件。
修改的第一个配置文件是:${canal}/conf/canal.properties
这个配置文件里面我们修改的第一值是:
canal.serverMode = kafka
这个参数我们把他修改为kafka,然后往下拖可以看到有kafka的配置
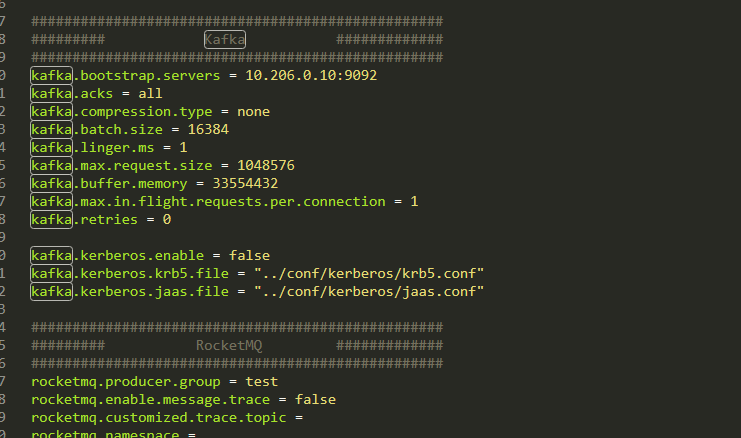
canal现在使用的是mq的connector,所以我们model修改为什么,那么就在下面的mq里面填写对应的信息即可,除了地址,这里几乎都是保持默认的信息。
修改的第二个配置文件是:${canal}/conf/example/instance.properties
这个文件我们要修改什么呢?其实主要就是修改下发送到mq的哪一个topic,修改内容是:
canal.mq.topic=test
这个test就是我们需要发送到kafka的test主题里面。其他的配置就是canal安装里面配置的mysql的信息,我们暂时不用动他。
然后在服务端重新启动下canal。${canal}/bin/stop.sh和${canal}/bin/startup.sh
然后我们再进入到mysql里面去更改数据。然后就可以从kafka的test主题里面看到更改的内容了。

上面一个完整的canal消息发送到kafka就配置完了。
但是我们如果熟悉kafka的人其实都知道,kafka这边是乱序的,在多线程解析的时候就会出现数据错误(由于sql的执行前后顺序问题)。那么正对消息队列的顺序性我们如何处理呢?主要有以下几种方式:
1、如果数据库的操作不是很频繁,那么我们在kafka里面使用单分区即可。 2、如果数据库的操作很频繁,那么我们可以每一张表做一个分区,根据路由做分区即可。
针对上面第一个方式的话,我们演示的就是这个示例。
针对上面第二种方式的话,我们需要在instance.properties配置文件里面配置如下参数:
canal.mq.partitionHash=mydatabase.mytable
如果是多个的话,则使用逗号分割即可。下图是原示例数据,看到里面的逗号了吗?就是这个逗号分割。
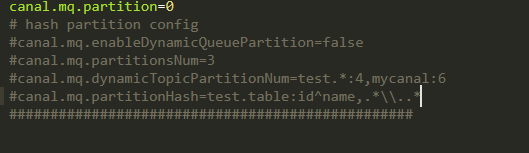
散列规则是:
散列规则定义 库名.表名: 唯一主键,多个表之间用逗号分隔 canal.mq.partitionHash=test.lyf_canal_test:id








还没有评论,来说两句吧...