
在前面我们介绍了Delta Lake的安装,这篇文章我们介绍下数据湖的操作API,即ACID。
一、写入数据到Delta Lake
把数据写入到Delta Lake中很简单,因为Delta Lake强依赖spark,同时在spark2.x版本之后,我们操作的对象主要是dataframe,我们在前面spark系列里面介绍了dataframe可以直接看作是一张内存表,那么把数据写入到Delta Lake中,其实就是把dataframe写入到Delta Lake中,下面示范一下:
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
val session = SparkSession.builder().appName("DeltaLakeDemo")
.master("local[1]")
.config(new SparkConf()).getOrCreate();
val data = session.range(0, 5)
data.write.format("delta").save("file:///D:\\lake")是不是很简单,文件格式为delta,保存到某个指定目录里面去。
二、从Delta lake中查询数据
查询数据也很简单,我们写入进去的是dataframe,那么查询出来的也是dataframe,因此代码如下:
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
val session = SparkSession.builder().appName("DeltaLakeDemo")
.master("local[1]")
.config(new SparkConf()).getOrCreate();
val df = session.read.format("delta").load("file:///D:\\lake")
df.show()运行下看下效果:
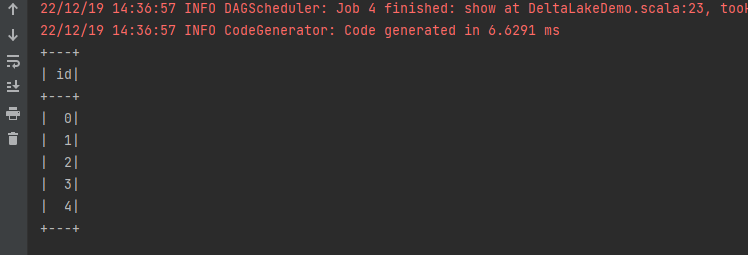
可以看到把数据查询出来了。
三、更新数据到Delta Lake中
这里的更新数据和操作nosql数据库是一样的,分为两种情况,第一种是完全覆盖掉,第二种是带条件更新,下面分别演示一下:
3.1、直接覆盖掉原始数据
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
val session = SparkSession.builder().appName("DeltaLakeDemo")
.master("local[1]")
.config(new SparkConf()).getOrCreate();
val data = session.range(6, 10)
data.write.format("delta").mode("overwrite").save("file:///D:\\lake")
val df = session.read.format("delta").load("file:///D:\\lake")
df.show()运行看下结果:
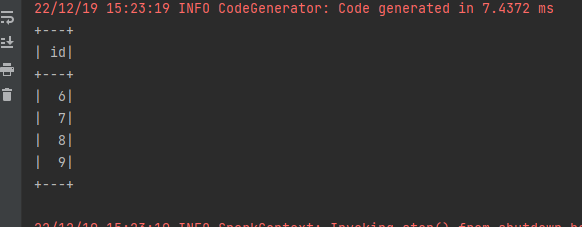
全是新的数据,没有老的数据了。
3.2、使用条件不覆盖更新数据
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
val conf = new SparkConf()
conf.set("spark.sql.extensions","io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog","org.apache.spark.sql.delta.catalog.DeltaCatalog")
val session = SparkSession.builder().appName("DeltaLakeDemo")
.master("local[1]")
.config(conf)
.getOrCreate();
//如果需要使用条件更新Delta Lake的数据,需要先把表读出来,做成一个table对象,再使用table对象进行更新
val table = DeltaTable.forPath("file:///D:\\lake")
table.update(condition = expr("id % 2 ==0"), set = Map("id" -> expr("id+10")))
//读取结果
val df = session.read.format("delta").load("file:///D:\\lake")
df.show()再执行下看下效果:
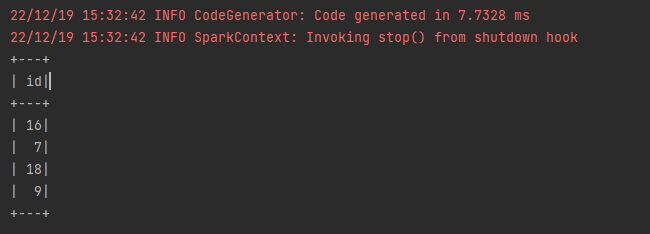
数据实现了有条件更新,而且结果也是我们期望的。
四、删除数据
删除数据主要还是通过条件进行删除
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
val conf = new SparkConf()
conf.set("spark.sql.extensions","io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog","org.apache.spark.sql.delta.catalog.DeltaCatalog")
val session = SparkSession.builder().appName("DeltaLakeDemo")
.master("local[1]")
.config(conf)
.getOrCreate();
//如果需要使用条件更新Delta Lake的数据,需要先把表读出来,做成一个table对象,再使用table对象进行更新
val table = DeltaTable.forPath("file:///D:\\lake")
table.delete(condition = expr("id % 2 ==0"))
//读取结果
val df = session.read.format("delta").load("file:///D:\\lake")
df.show()五、合并数据
这里还提供合并的功能,相当于union的操作,示例如下:
//在windows环境下需要设置hadoop的环境变量,不然运行程序的时候会报错
System.setProperty("hadoop.home.dir", "D:\\hadoop-common-2.2.0-bin-master");
val conf = new SparkConf()
conf.set("spark.sql.extensions","io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog","org.apache.spark.sql.delta.catalog.DeltaCatalog")
val session = SparkSession.builder().appName("DeltaLakeDemo")
.master("local[1]")
.config(conf)
.getOrCreate();
var testdata = Seq((1,"张三"),(7,"李四"),(9,"王五"),(10,"赵六"))
import session.implicits._
val testDF = testdata.toDF("id","name")
//如果需要使用条件更新Delta Lake的数据,需要先把表读出来,做成一个table对象,再使用table对象进行更新
val table = DeltaTable.forPath("file:///D:\\lake")
//老数据和新数据的合并,匹配条件是两边的id相等
table.as("oldData").merge(testDF.as("newData"),"oldData.id = newData.id")
//如果匹配的话,则合并一起
.whenMatched.update(Map("id" -> col("newData.id")))
//如果不匹配的话,则插入新数据,也可以根据自己的业务点进行转换
.whenNotMatched.insert(Map("id" ->col("newData.id")))
.execute()
//读取结果
val df = session.read.format("delta").load("file:///D:\\lake")
df.show()备注:
1、以上我们演示了如何对数据湖Delta Lake进行ACID的操作。
2、不管是使用spark-shell还是scala或者java变成,一定要记得设置conf,这是以下两个参数:
val conf = new SparkConf()
conf.set("spark.sql.extensions","io.delta.sql.DeltaSparkSessionExtension")
conf.set("spark.sql.catalog.spark_catalog","org.apache.spark.sql.delta.catalog.DeltaCatalog")如果不设置的话,可能存在文件格式读取不匹配,从而导致程序报错。








还没有评论,来说两句吧...