
在IT界学习一个技术,编写的第一个应用程序就是HelloWord,因此在这里,我们使用scala编写以第一个spark应用程序:helloword。
备注:
这里我们主要演示使用scala编写一个spark的wordcount程序。直接开始
一、创建一个maven项目,并且引入maven依赖
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.13</artifactId> <version>3.3.1</version> </dependency>
二、准备一个text文档,用于统计单词数量
Studying a subject that you feel pointless is never a fun or easy task. If you're study history, asking yourself the question "why is history important" is a very good first step. History is an essential part of human civilization. You will find something here that will arouse your interest, or get you thinking about the significance of history.

三、创建一个SparkWordCount的scala object主类
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
//这里主要是声明spark的配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("SparkWordCount")
//把配置信息注入到sparkcontext里面来。
val sc: SparkContext = new SparkContext(sparkConf)
//读取本地的文件
var textFile = sc.textFile("C:\\Users\\Administrator\\Desktop\\fsdownload\\aaa.txt")
var counts = textFile.flatMap(line => line.split(" ")) //这里主要是把英文单词按照空格进行切分,属于一对多的action,即一条英文可以分成多个单词
.map(word => (word, 1)) //这里是把每一个单词都计数为1
.reduceByKey(_ + _) //最后根据单词进行聚合,然后把单词的计数进行相加。
//打印出最后的统计结果。
counts.collect().foreach(println)
}
}然后执行一下,即可看到统计结果
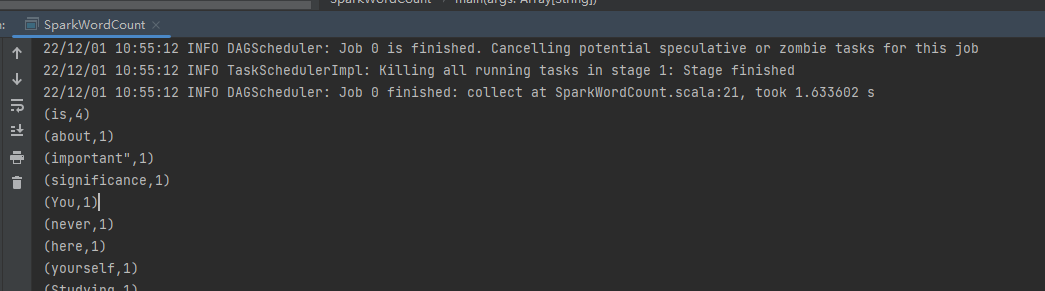
以上就是一个非常简单的使用scala编写spark的wordcount的案例。
最后附上源码,登录后即可下载。








还没有评论,来说两句吧...