
在前面我们介绍了直接在物理机上安装spark集群,详见《Spark学习(十)Spark集群安装》,在生产环境中我们肯定是必须使用这种方式安装。这篇文章我们介绍使用docker的方式安装一个spark集群,这样可以在测试环境中很方便的使用。
备注:这里我们主要依赖的是bitnami/spark:3这个镜像。整个集群的节点信息如下:
| 序号 | 节点 | 映射端口 |
| 1 | master | 8080和4040 |
| 2 | worker1 | 8081 |
| 3 | worker2 | 8082 |
下面直接开始。
一、在服务器上安装docker
这里不再介绍了,可以参考:《centos7.x 如何在线安装docker?》和 《centos7.x 如何离线安装docker?》。
二、在服务器上安装docker-compose
这里也在前面的文章介绍过,可以参考:《docker-compose安装工具》。
三、拉取镜像
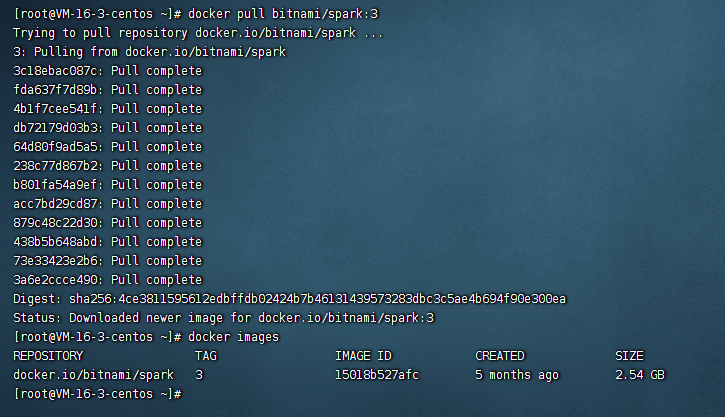
docker pull bitnami/spark:3
使用上面的命令拉取spark的镜像。
四、创建一个spark的docker-compose文件
创建docker-compose文件
把下面的内容粘贴到docker-compose.yml文件里面去:
version: '3' services: spark: image: docker.io/bitnami/spark:3 hostname: master environment: - SPARK_MODE=master - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - /home/pubserver/spark/commondata:/opt/share ports: - '8080:8080' - '4040:4040' networks: sparknet: ipv4_address: 172.22.0.100 extra_hosts: - "master:172.22.0.100" - "worker1:172.22.0.101" - "worker2:172.22.0.102" spark-worker-1: image: docker.io/bitnami/spark:3 hostname: worker1 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://master:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - /home/pubserver/spark/commondata:/opt/share ports: - '8081:8081' networks: sparknet: ipv4_address: 172.22.0.101 extra_hosts: - "master:172.22.0.100" - "worker1:172.22.0.101" - "worker2:172.22.0.102" spark-worker-2: image: docker.io/bitnami/spark:3 hostname: worker2 environment: - SPARK_MODE=worker - SPARK_MASTER_URL=spark://master:7077 - SPARK_WORKER_MEMORY=1G - SPARK_WORKER_CORES=1 - SPARK_RPC_AUTHENTICATION_ENABLED=no - SPARK_RPC_ENCRYPTION_ENABLED=no - SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no - SPARK_SSL_ENABLED=no volumes: - /home/pubserver/spark/commondata:/opt/share ports: - '8082:8081' networks: sparknet: ipv4_address: 172.22.0.102 extra_hosts: - "master:172.22.0.100" - "worker1:172.22.0.101" - "worker2:172.22.0.102" networks: sparknet: driver: bridge ipam: config: - subnet: "172.22.0.0/24"
五、启动spark的docker-compose
docker-compose up -d
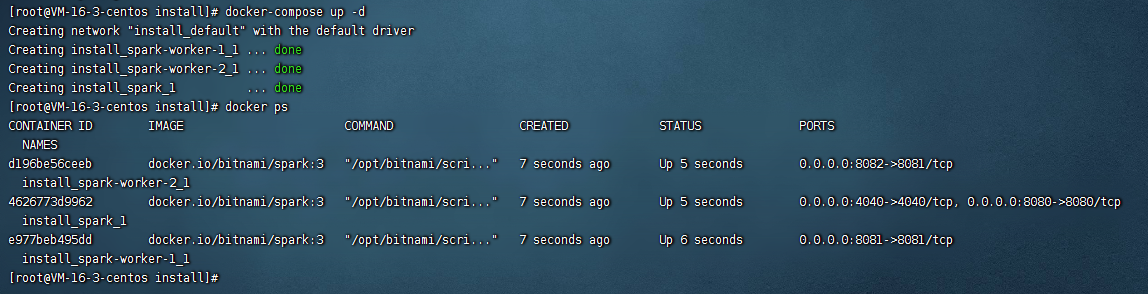
可以看到spark被启动起来了。
六、测试访问
6.1、首先我们访问spark的masterui节点,地址是:http://${host}:8080
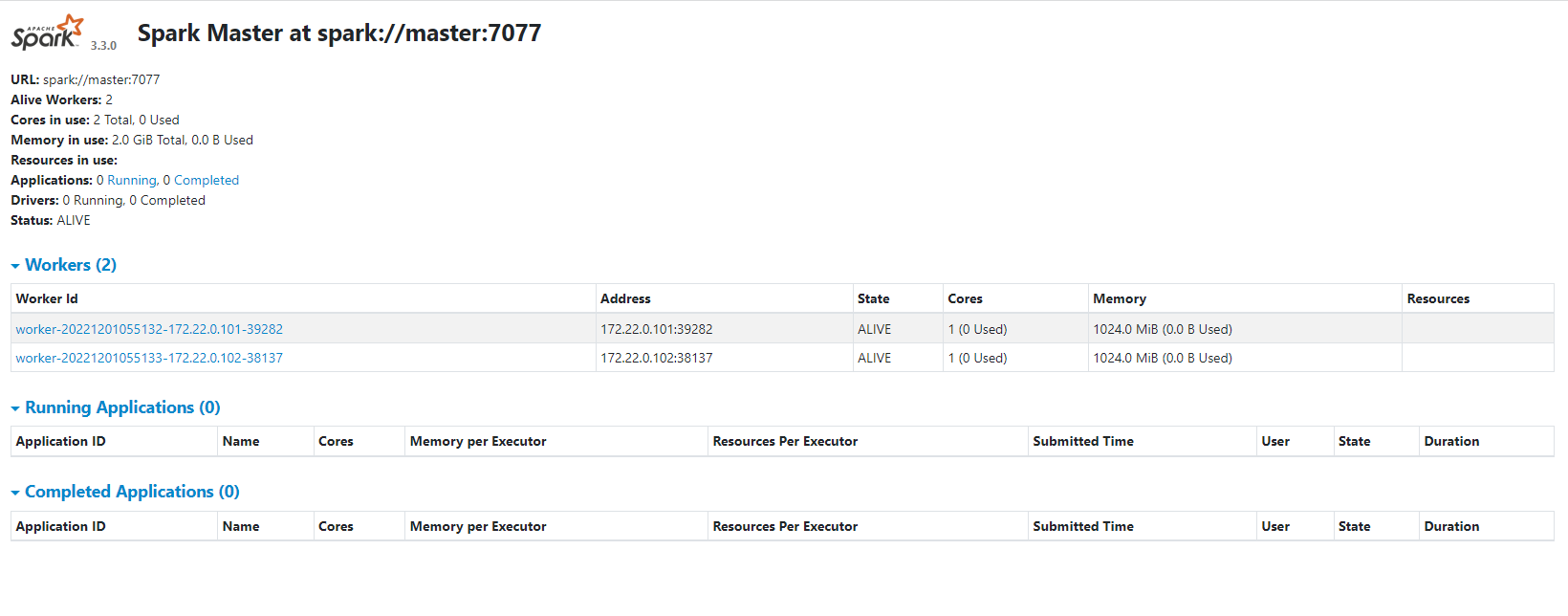
可以看到spark被启动起来了,1个master,2个worker角色。
6.2、再看看spark的worker1的ui,地址是:http://${host}:8081
6.3、再看看worker2的ui界面,地址是:http://${host}:8082
到此为止,我们使用docker的方式安装spark standalone的集群已经完成了。
备注:
1、如果要结合hadoop使用的话,那么我们查看hadoop的版本信息可以使用如下的命令:
1、进入到docker容器中: docker exec -it install_spark_1 bash 2、进入到spark的bin目录: cd /opt/bitnami/spark/bin 3、执行 ./pyspark 4、执行获取hadoop版本的命令: sc._gateway.jvm.org.apache.hadoop.util.VersionInfo.getVersion()
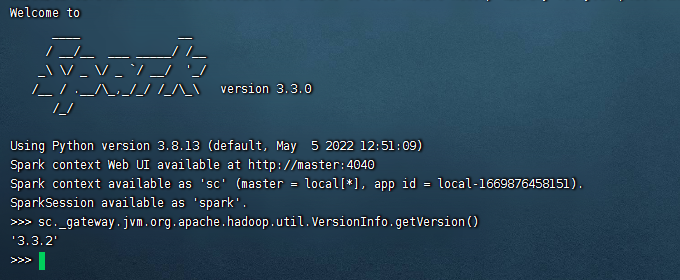
至此hadoop的版本号就获取回来了。








还没有评论,来说两句吧...