
我们在前面介绍了spark相关的基础知识,这篇文章我们介绍下spark的集群安装,先把spark跑起来看一下是一个什么内容,然后再继续接着其他知识点讲解。
一、准备3台服务器
这里我们准备3台服务器做测试节点,分别是:
| 序号 | ip | 操作系统 | 角色 |
| 1 | 10.206.0.17 | centos 7.9 | node1(master) |
| 2 | 10.206.0.15 | centos 7.9 | node2(worker) |
| 3 | 10.206.0.9 | centos 7.9 | node3(worker) |
大家再测试的时候也可以多准备几台服务器。
二、在服务器上安装jdk
这里我们安装的jdk版本是1.8,jdk1.8可以在官网进行下载,也可以在这里下载。 jdk1.8下载
2.1、把jdk上传到服务器的/usr/local目录下
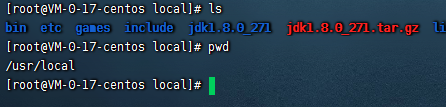
2.2、把jdk1.8解压出来
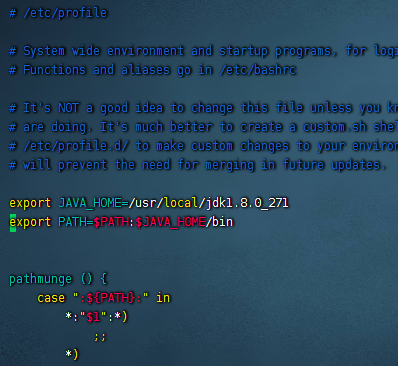
2.3、配置/etc/profile
export JAVA_HOME=/usr/local/jdk1.8.0_271 export PATH=$PATH:$JAVA_HOME/bin
2.4、执行下profile文件
. /etc/profile
2.5、测试下jdk是否正确安装
jps
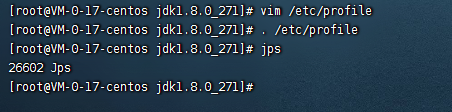
可以看到jps被正确安装了。
2.6、在另外两台机器上重复上面的步骤安装jdk并且测试
三、为服务器配置host文件
3.1、配置服务器的host文件
vim /etc/hosts
然后把以下的内容复制到hosts文件中,并且保存起来
10.206.0.17 node1 10.206.0.15 node2 10.206.0.9 node3
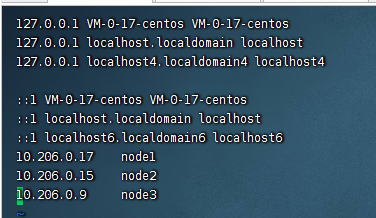
3.2、测试下是否配置成功
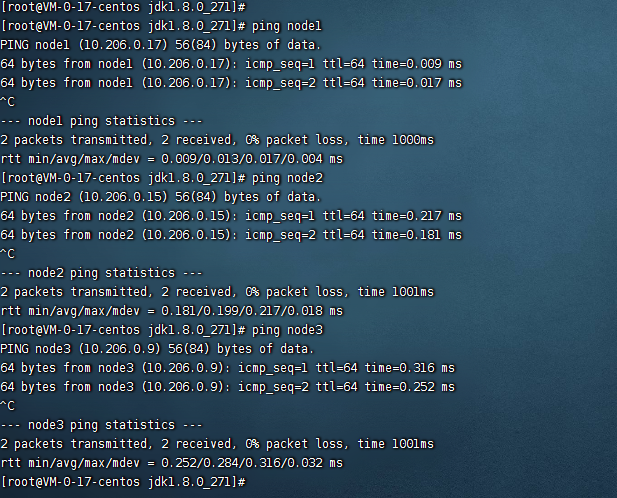
3.3、在另外两台服务器上重复上面的操作配置host并且进行测试
3.4、修改下服务器的hostname
1)在node1上执行命令
hostname node1
2)在node2上执行命令
hostname node2
3)在node3上执行命令
hostname node3
备注:这里我们需要把hostname配置成和host一样的,因此在spark启动的时候它会去连接hostname对应的ip,如果没修改的话,他就会链接不上,如下图:
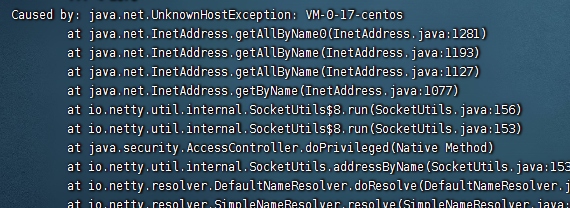
像这种就两种解决办法,第一种就是这里设置hostname,第二种就是继续在host文件里面添加主机名和ip的对应。我们提倡使用第一种。
还有就是修改了hostname之后,当前session窗口的hostname不会马上变化,可以我们断开链接,再重新链接一次即可。
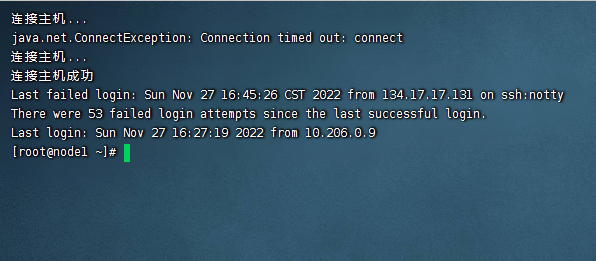
重新链接就可以看到hostname被修改过来了。
四、下载spark安装包
这里我们从官网下载spark的安装包即可,官网的下载页面是:https://spark.apache.org/downloads.html。这里我们下载的是目前最新版本3.3.1,下载完后,上传并解压到服务器上,这里我们spark路径是:/home/pubserver/spark-3.3.1-bin-hadoop3
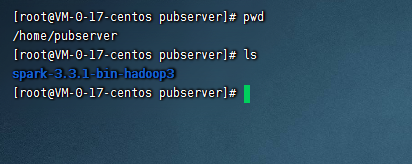
五、配置spark
5.1、修改template文件
在${spark_home}/conf目录下默认所有的文件都带有.template字符,

这里我们修改2个文件,分别是spark-env.sh.template和workers.template文件,重新复制一份,把.template字符删除掉。

5.2、修改spark-env.sh文件
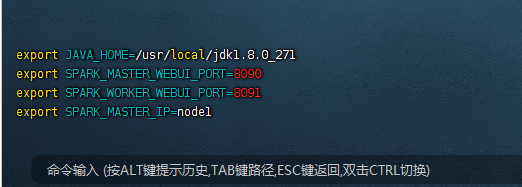
这个文件主要是添加java_home,并且把spark相关的配置都配置到这里面,具体的内容是:
export JAVA_HOME=/usr/local/jdk1.8.0_271 export SPARK_MASTER_WEBUI_PORT=8090 export SPARK_WORKER_WEBUI_PORT=8091 export SPARK_MASTER_IP=node1
5.3、修改workers文件
主要在这里添加slave节点,这里我们的slave节点是node2和node3
node2 node3
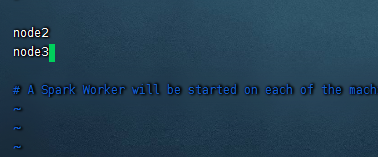
备注:这里记得把原来自带的localhost给删除掉。
5.4、把整个spark的文件夹复制到node2和node3节点。
scp -r spark-3.3.1-bin-hadoop3 node2:/home/pubserver/ scp -r spark-3.3.1-bin-hadoop3 node3:/home/pubserver/
六、配置ssh免密码登录
这里我们需要配置ssh免密码登录,这3台机器两两之间进行ssh不用输入密码
6.1、生成本机的公钥
ssh-keygen
这里使用了上面的命令之后,一路回车即可
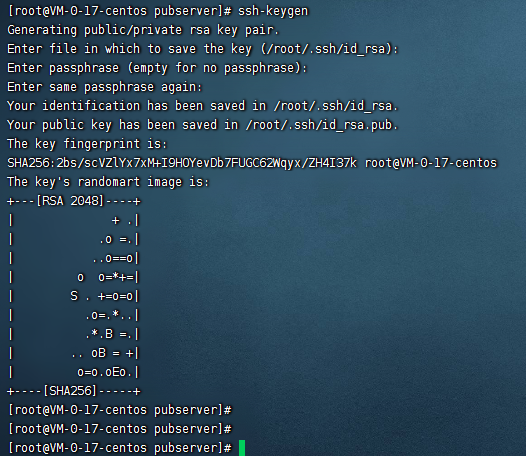
使用上面的命令之后,就会在当前用户的目录下的.ssh目录下生成一个id_rsa.pub文件
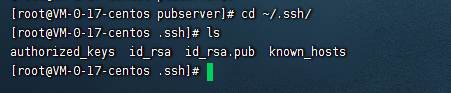
这就是我们想要的公钥文件。
6.2、把这个公钥文件复制给其他的机器
ssh-copy-id -i ~/.ssh/id_rsa.pub root@node2 ssh-copy-id -i ~/.ssh/id_rsa.pub root@node3
使用上面的命令,把公钥配置到其他机器上,配置完毕后我们测试一下
ssh node2 ssh node3
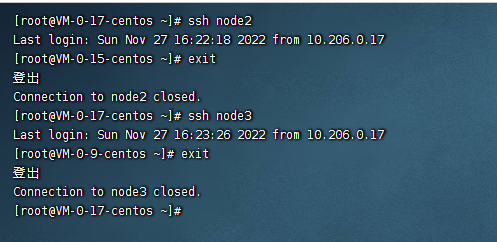
此时我们可以看到ssh免密码配置好了。
6.3、在node2上重复操作6.1和6.2的步骤
6.4、在node3上重复操作6.1和6.2的步骤
此时我们3台服务器两两之间就可以实现免密码登录了。
七、启动spark集群
7.1、进入到${spark_home}目录下
cd /home/pubserver/spark-3.3.1-bin-hadoop3/sbin/ ./start-all.sh

此时我们就把spark集群启动起来了。
7.2、验证集群
在上面我们规划的是node1是master角色,node2和node3是work角色,所以node1上执行jps应该有一个进程叫做master,node2和node3上执行jps应该有一个进程叫做worker。下面验证下
首先node1
可以看到node1上是有master进程的。
接着node2
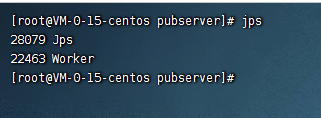
可以看到node2上是有worker进程的。
最后node3
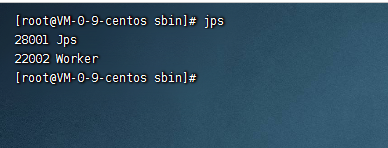
可以看到node3上是有worker进程的。
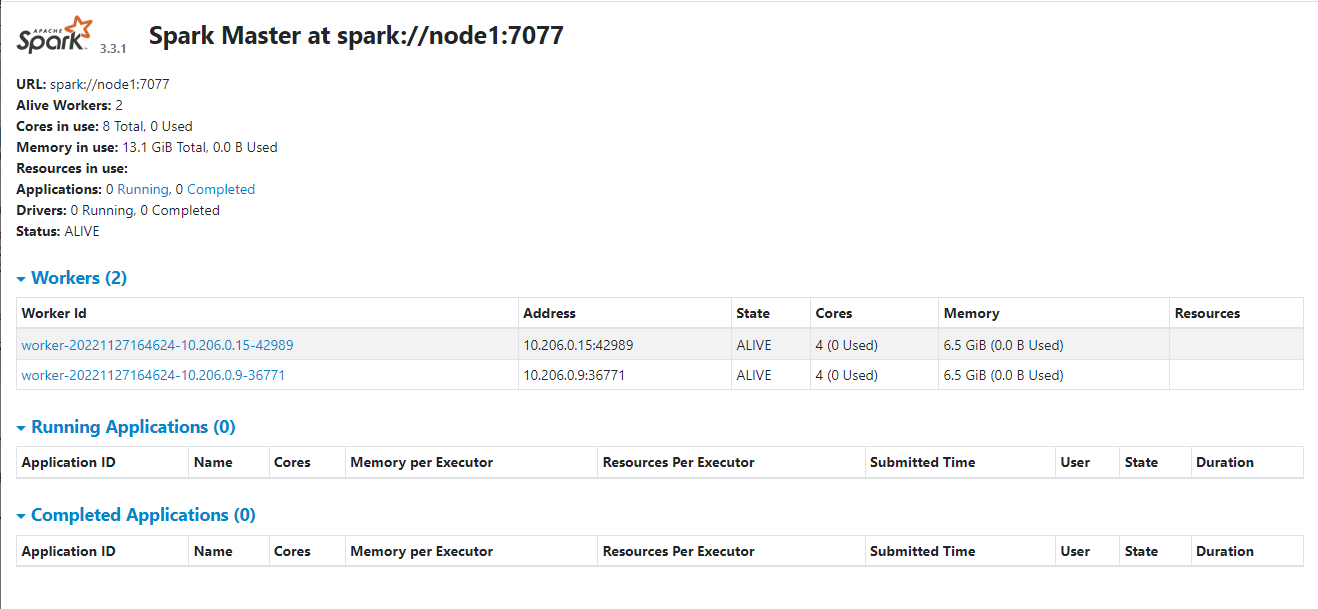
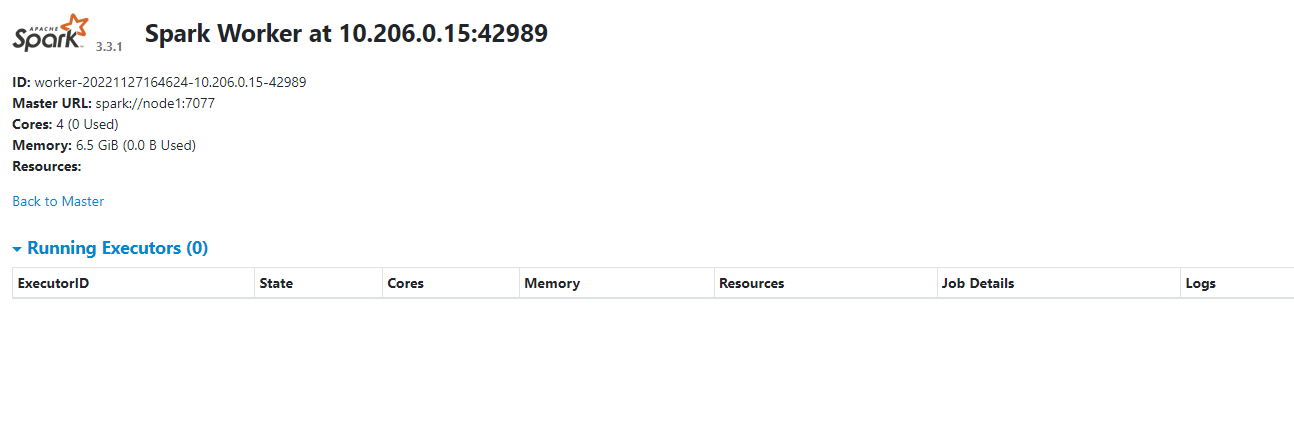
八、查看spark的webui
spark安装完了之后,我们的master会有webUI地址和端口,worker也会有webUI地址和端口。这个端口是在前面的spark-env.sh文件里面配置的。
master的UI是:http://${ip}:8090
worker的UI是:http://${ip}:8091








还没有评论,来说两句吧...