
在前面我们介绍了使用scala开发一个spark的wordcount程序,当时读取的是本地,最后结果是打印出来,现在我们把这个文件上传到hdfs上,然后通过hdfs进行读写文件。(写这篇文章主要是为了写下一篇spark的应用程序提交)。
一、首先准备一个hadoop环境
这里我们搭建一个单机的hadoop环境即可,这里我们使用的版本号是:3.3.2

二、把aaa.txt文件上传到hdfs系统中
./hadoop fs -put fs -put /mnt/aaa.txt /sources/aaa.txt

三、验证文件是否被上传上去了
在使用hadoop3.x的版本里面,我们查看hdfs的文件地址是:http://${host}:9870(在hadoop2.x的版本里面的地址是:http://${host}:50070)
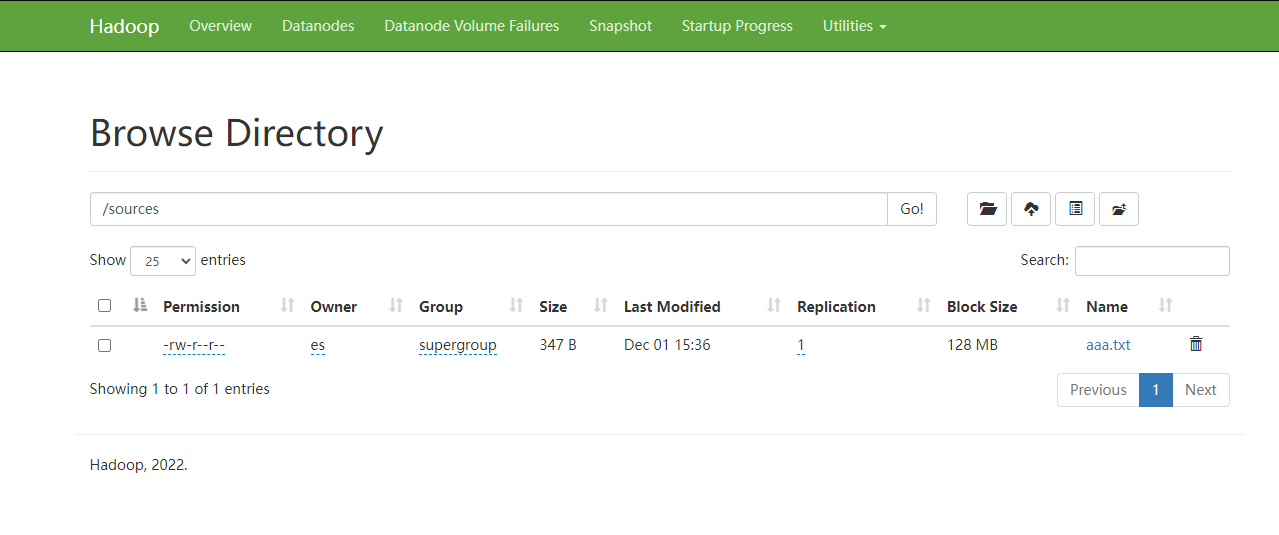
这里文件已经被上传了。
四、修改spark的wordcount程序
这里我们把刚才写的spark的wordcount程序修改下,读取文件从hdfs上读取,写入文件写入到hdfs上。
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
//这里主要是声明spark的配置信息
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("SparkWordCount")
//把配置信息注入到sparkcontext里面来。
val sc: SparkContext = new SparkContext(sparkConf)
//读取本地的文件
var textFile = sc.textFile("hdfs://43.153.211.182:59000/sources/aaa.txt")
var counts = textFile.flatMap(line => line.split(" ")) //这里主要是把英文单词按照空格进行切分,属于一对多的action,即一条英文可以分成多个单词
.map(word => (word, 1)) //这里是把每一个单词都计数为1
.reduceByKey(_ + _) //最后根据单词进行聚合,然后把单词的计数进行相加。
//打印出最后的统计结果。
counts.collect().foreach(println)
counts.saveAsTextFile("hdfs://43.153.211.182:59000/sparkwordcount")
}
}五、运行新的wordcount程序
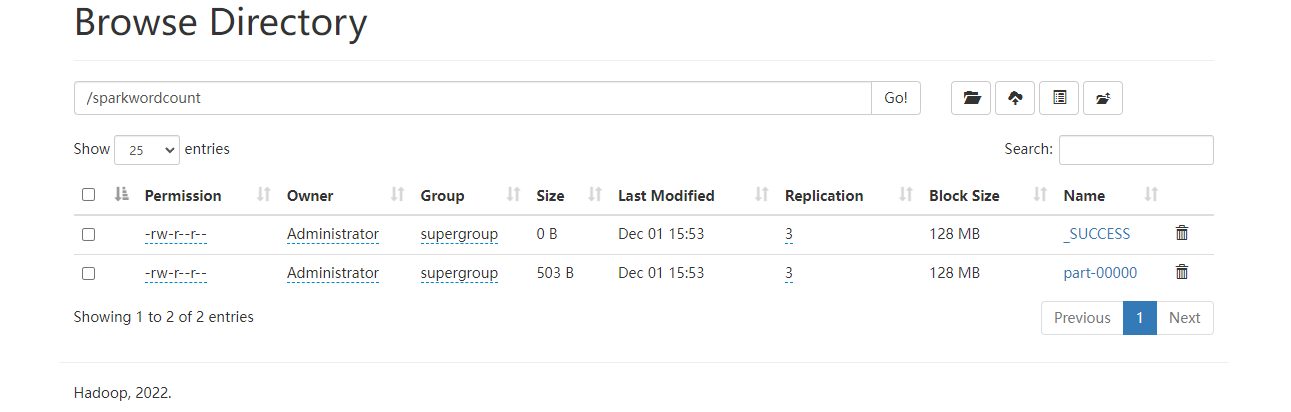
从这里可以看到已经把结果写入到了hdfs系统上。查看一下结果,这里的结果主要是在part-xxx的文件里面。
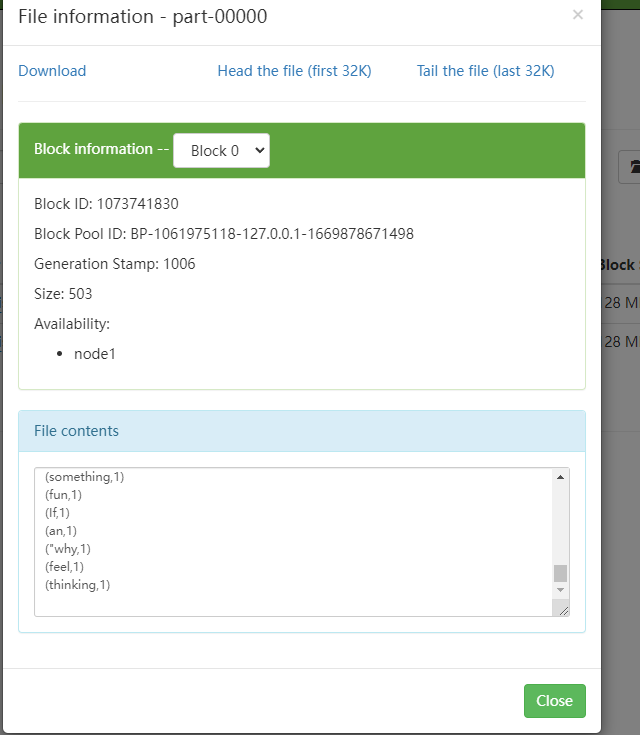
这里代表从hdfs读取文件和写入结果到hdfs上的测试是成功的。
最后附上本文修改后的应用程序源码,登录后即可下载。








还没有评论,来说两句吧...