
之前的文章我们介绍了spark的wordcount应用程序开发,同时也把spark的wordcount应用程序修改为从hdfs上读取和写入,这篇文章我们介绍下如何把spark应用程序提交到spark集群里面运行。
一、改写wordcount的应用程序:
package org.example
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
//这里主要是声明spark的配置信息
val sparkConf: SparkConf = new SparkConf().setAppName("SparkWordCount")
//把配置信息注入到sparkcontext里面来。
val sc: SparkContext = new SparkContext(sparkConf)
//读取本地的文件
var textFile = sc.textFile("hdfs://43.153.211.182:59000/sources/aaa.txt")
var counts = textFile.flatMap(line => line.split(" ")) //这里主要是把英文单词按照空格进行切分,属于一对多的action,即一条英文可以分成多个单词
.map(word => (word, 1)) //这里是把每一个单词都计数为1
.reduceByKey(_ + _) //最后根据单词进行聚合,然后把单词的计数进行相加。
//打印出最后的统计结果。
counts.collect().foreach(println)
counts.saveAsTextFile("hdfs://43.153.211.182:59000/sparkwordcount")
}
}这里主要是修改conf,把模式去掉,之前是:
val sparkConf: SparkConf = new SparkConf().setMaster("local").setAppName("SparkWordCount")现在要改成
val sparkConf: SparkConf = new SparkConf().setAppName("SparkWordCount")二、把spark的wordcount应用程序进行打包
mvn install
打包成功。可以自爱target里面看到打好的包:
三、把jar包上传到服务器上
然后再spark集群的master节点下进入到spark的bin目录下,执行下面的命令:
./spark-submit --class org.example.SparkWordCount --master spark://master:7077 /opt/share/TestDemo-1.0-SNAPSHOT.jar
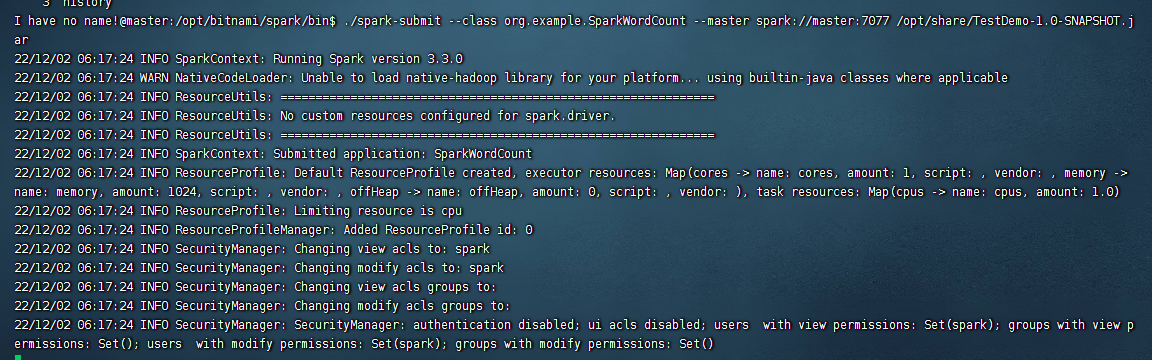
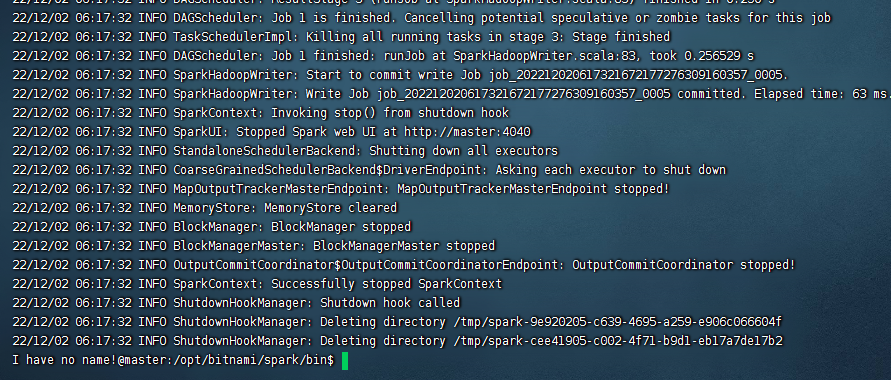
到这里我们就执行完毕了,然后看下hdfs上的文件
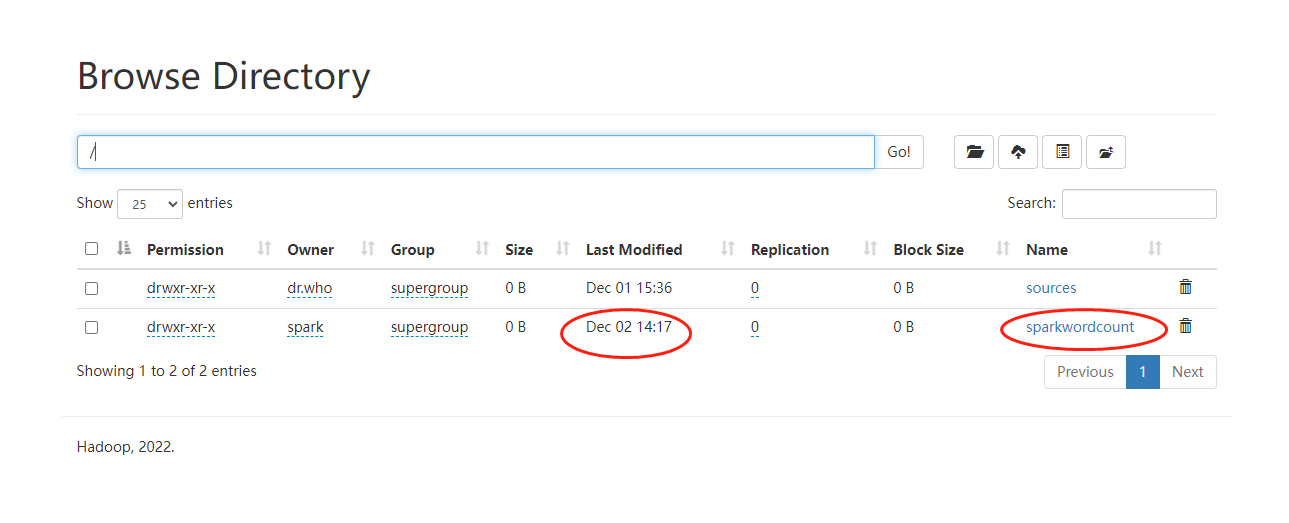
目标文件已经生成,然后再看下统计结果:
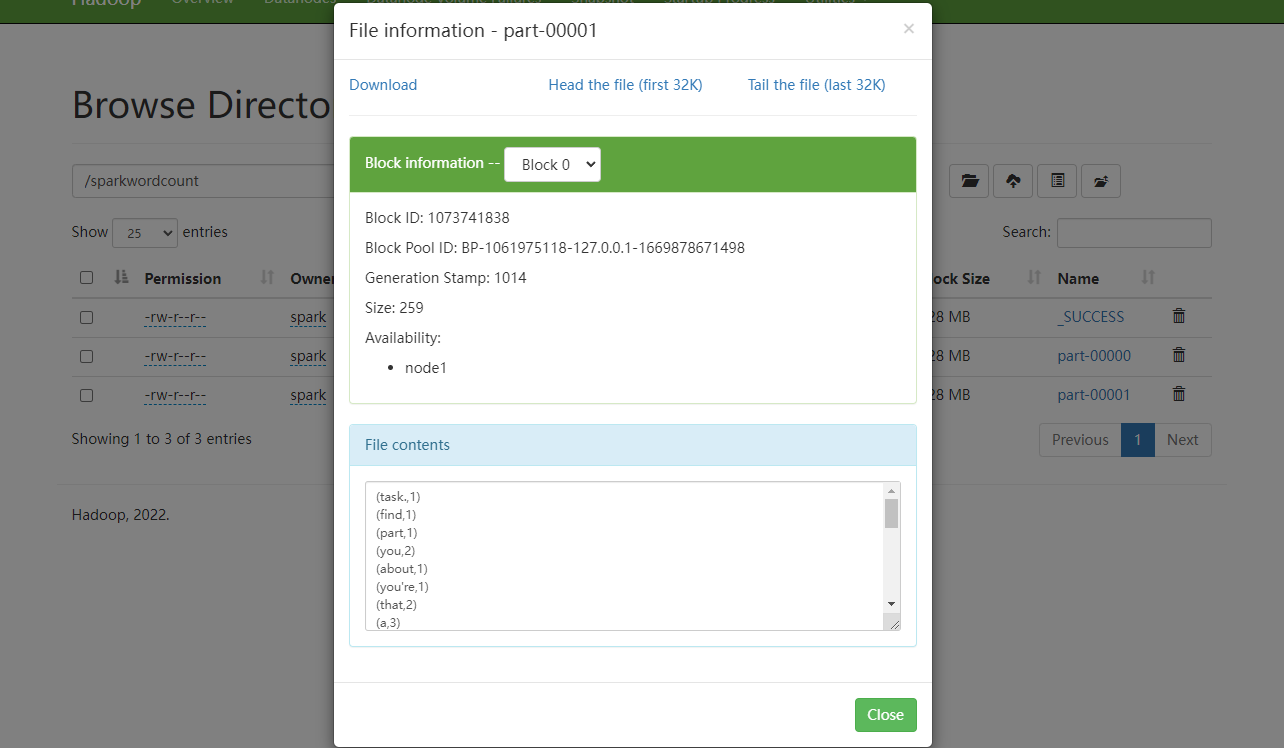
执行成功了。然后我们去看下sparkui里面的任务类型: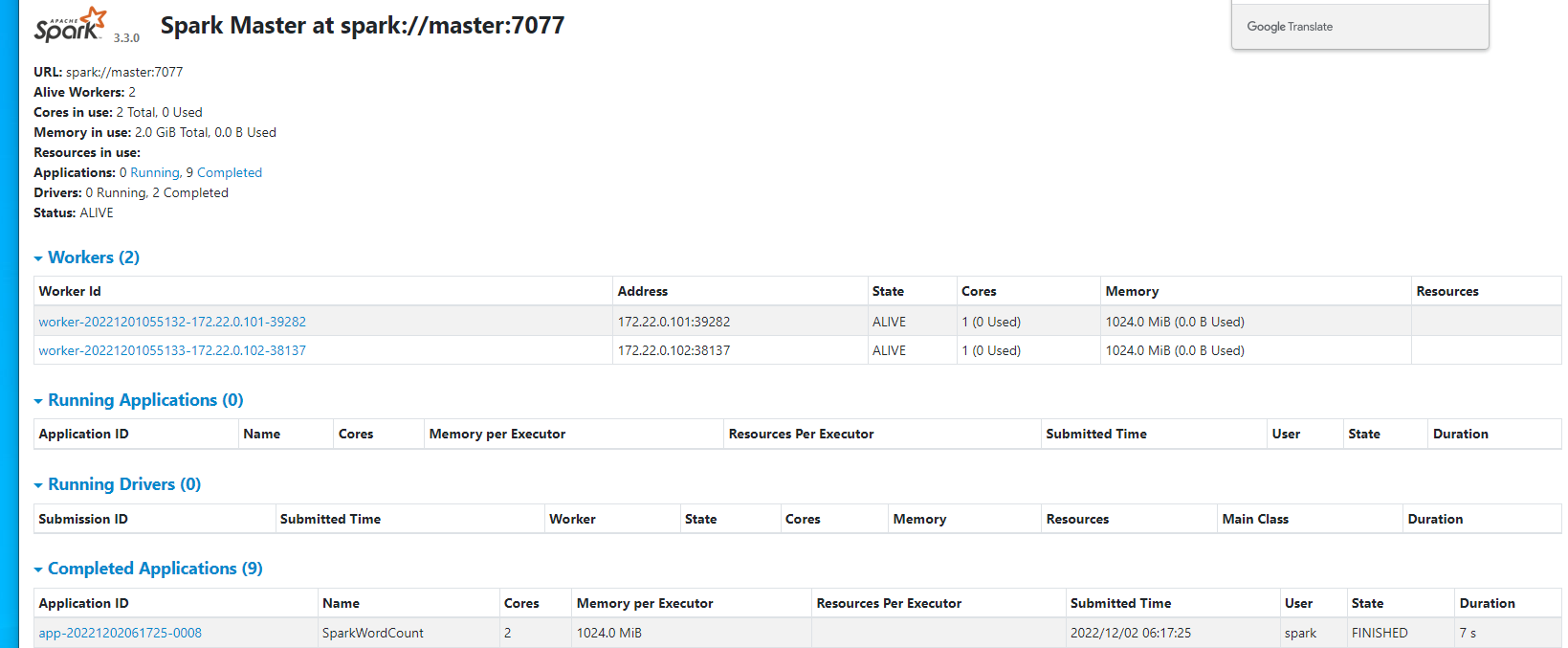
可以看到任务提交时间,执行情况,执行状态,整体耗时。到此为止我们一个完整的spark程序就提交到spark集群上运行了。
备注:
1、这里打包的时候需要关注下spark使用的scala版本,这里我们使用的是之前介绍的docker方式启动的spark集群,内部的scala版本是2.12.15,因此在开发代码的时候也需要把scala版本修改为和spark集群保持一致。
2、在添加spark依赖的时候,也需要留意下具体的spark依赖使用的scala版本,如果spark版本太高或者太低,导致与当前spark集群的scala版本不一致,运行的时候也会报错。
最后附上本案例的源码,登录后即可下载








还没有评论,来说两句吧...