
在前面我们介绍了spark直接提交到standalone的集群运行,这里我们演示下把spark的程序提交到yarn上运行。在生产环境中我们一般都会把应用程序提交到yarn上运行,这几乎是我遇到的大数据公司的共识,通过yarn做集群的资源管理,这样整个集群的资源都可控,同时集群内的资源都可以很直观的被查看到。
演示的话程序还是之前开发的sparkwordcount程序,只是在spark上提交的命令不一样,这里我们使用的命令是:
./spark-submit --deploy-mode cluster --class org.example.SparkWordCount --master yarn /home/pubserver/spark-3.3.0-bin-hadoop3/jobjar/TestDemo-1.0-SNAPSHOT.jar
提交之后,命令行的日志就会发生变化,例如:
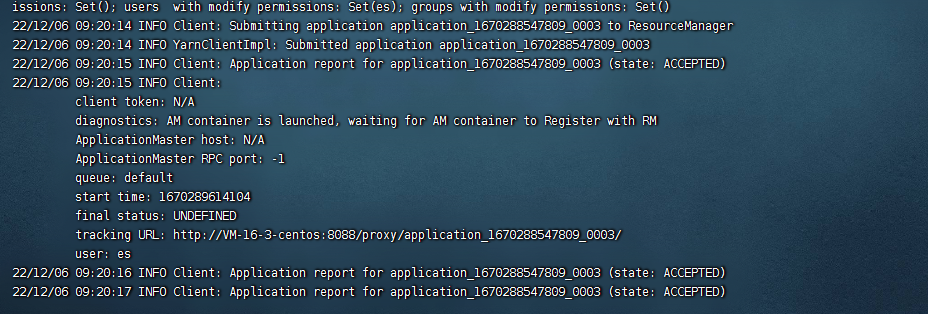
此时我们访问hadoop的yarn资源管理页面:http://${host}:8088
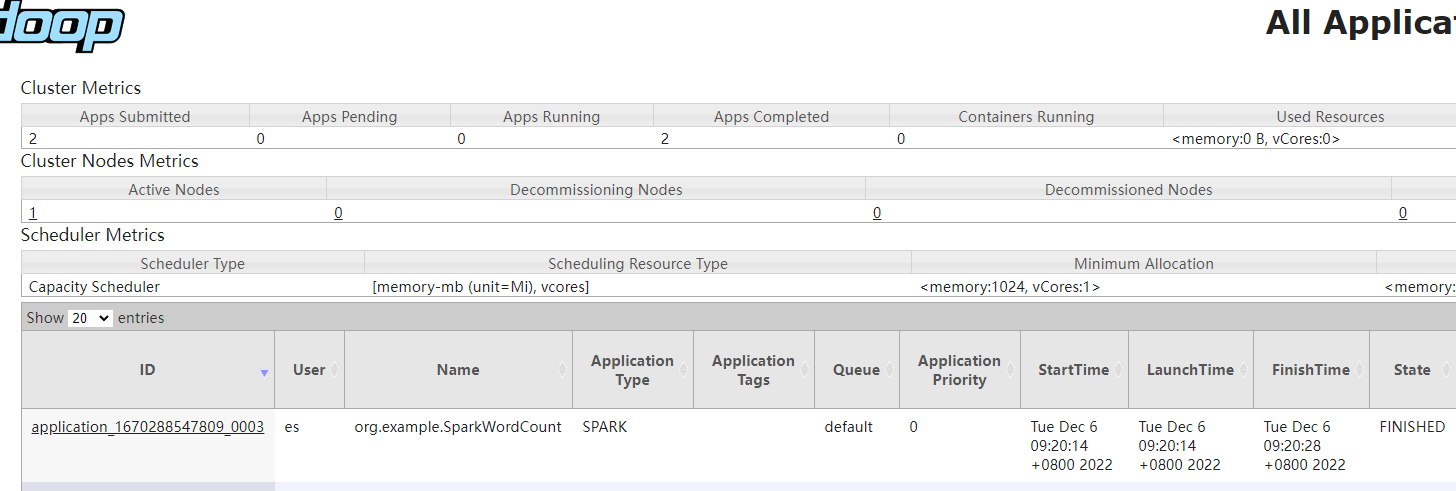
这里我们可以看到程序被正确的执行了,此时我们就相当于成功的把spark的程序提交到了yarn上执行。
备注:
1、在提交程序到yarn上之后,这里的命令里面需要添加如下参数:
--deploy-mode cluster
并且在master参数里面也有变化,之前在master参数后面填写的是spark的7077端口,在提交到yarn的时候,这里必须要写死,直接是:
--master yarn
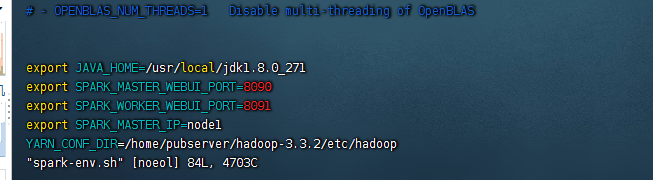
2、spark的安装方式在本篇演示的时候我们更改到了本地单机,主要是由于在spark中,我们需要配置hadoop的conf信息,这样子spark才能读取到yarn相关的配置(使用docker的话,目录不关联)这里配置信息是在 ${SPARK_HOME}/conf/spark-env.sh文件中添加如下信息:
YARN_CONF_DIR=/home/pubserver/hadoop-3.3.2/etc/hadoop
如图:
3、在提交到yarn的时候,一般我们还会配置很多参数,例如:
1、spark.driver.memory spark驱动的内存配置 2、executor-cores cpu个数 3、num-executors 执行器个数 4、executor-memory 执行器内存配置 5、jars 外部依赖jar包 6、name 为spark job任务起一个名称
除了以上的常用参数之外,还有其他的参数,这里暂时就不做介绍了,使用到的时候再进行酌情添加即可。这里再提供一个示例:
./spark-submit --deploy-mode cluster --master yarn --conf spark.driver.memory=512m --executor-cores 2 --num-executors 2 --executor-memory 1g --class org.example.SparkWordCount --name wordcount /home/pubserver/spark-3.3.0-bin-hadoop3/jobjar/TestDemo-1.0-SNAPSHOT.jar
最后附上本案例测试的源码,登录即可下载








还没有评论,来说两句吧...