
在spark中,对于rdd进行combineByKey,那这个rdd一定是一个key-value pair 类型的rdd。在这里使用combineByKey的时候,可能会遇到TupleN的参数格式,例如,如果我们得数据格式是:List(("张三",1,1,1,1,1,1,1))这种多Tuple的参数格式,我们需要把他转换成一个key-value这样的键值对的rdd类型。也就是需要转换成:List(("张三",(1,1,1,1,1,1,1,1))),这样就变成了只有一个key和一个value这样的rdd,然后在此rdd的基础上使用aggregateByKey函数。combineByKey函数的使用方式如下:
combineByKey(createCombiner,mergeValue,mergeCombiner)
在使用combineByKey的时候,这里其实相当于需要一套完整的流程来处理业务,也就是上面这3个参数,这3个参数分别需要传入3个函数,下面对这3个函数做下详细的解释:
1、createCombiner,这个函数主要是相当于前置的数据处理,这个函数主要是在分区里面进行处理的,一般我们在正式进行逻辑处理之前,讴需要对数据进行处理。所以这个里面一般都是一些数据处理的逻辑,例如:制作新的tuple数据结构,数据类型的转换操作等等。
2、mergeValue,这个函数主要是在分区里面进行合并处理,也就是在每一个小的分区里面进行逻辑处理,例如我们统计学生的总分数,那这个时候就需要把数据进行相加,传进来一份参数就相加一次,然后形成新的tuple数据结构。
3、mergeCombiner,这个主要是在最后shuffle完成的阶段进行的数据合并,也就是把每一个分区的处理结果进行数据合并。
所以基于上面的函数逻辑来看,在使用combineByKey的时候我们需要对数据进行阶段性的数据处理,最终达到我们想要结果,所以这里可以看做是一套业务的完整生命周期。下面我们举个案例来说明一下,这个案例的背景是统计学生的平均成绩。示例代码如下:
package org.example
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.SparkSession
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().config(new SparkConf()).master("local[*]").appName("SparkWordCount").getOrCreate();
val sc = session.sparkContext
//制作用户的成绩信息
val studentRDD = sc.parallelize(List(
("张三", "数学", 83), ("李四", "数学", 74), ("王五", "数学", 91),
("张三", "英语", 82), ("李四", "英语", 69), ("王五", "英语", 62),
("张三", "物理", 97), ("李四", "物理", 80), ("王五", "物理", 78),
("张三", "化学", 73), ("李四", "化学", 68), ("王五", "化学", 87),
("张三", "语文", 87), ("李四", "语文", 93), ("王五", "语文", 91)), 5)
//所有的多键值对都要做成一个键值对,所以一般我们是把首参数做成key,后面的参数合并后做成一个value,也就是value是多Tuple的RDD
val combineRdd = studentRDD.map( e => (e._1,(e._2,e._3)))
//这里执行combineByKey,也就是需要把整个函数做成创建,分区合并,最终合并 3个阶段处理
.combineByKey(createCombiner,mergeValue,mergeCombiner)
//前面相当于已经聚合成(${姓名},(${总分},${科目数量})),在这里我们需要对结果进行计算平均分,也就是形成(${姓名},${总分}/${总数量})
.map(e => (e._1,e._2._1/e._2._2))
//最后把结果打印出来
combineRdd.collect().foreach(println)
}
// 定义 createCombiner 函数,这里相当于把成绩和数量组装成一个数组,即("语文",80)转换成 (80,1)这里的1是写死的,即代表一个
def createCombiner = (tuple: (String, Int)) =>
(tuple._2.toDouble, 1)
// 定义 mergeValue 函数,这里相当于把每一次传递进来的参数和上一个进行相加,也就是(${总分},${数量}) 这里有1个+1,代表的是遇到一个学科就+1,因此这里不考虑传递进来重复的学科和成绩
def mergeValue = (accumulator: (Double, Int), element: (String, Int)) =>
(accumulator._1 + element._2, accumulator._2 + 1)
// 定义 mergeCombiner 函数 这里就相当于shuffle完成,传递过来的都是(${总分},${数量}),然后把这个分区的计算结果进行相加
def mergeCombiner = (accumulator1: (Double, Int), accumulator2: (Double, Int)) =>
(accumulator1._1 + accumulator2._1, accumulator1._2 + accumulator2._2)
}在代码里面有详细的combineByKey的完整诠释。看注释能明白里面的逻辑。
最后我们运行一下:
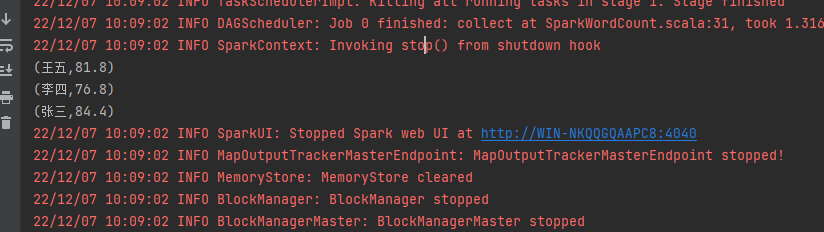
这里我们就可以看到统计出来了学生的平均成绩。








还没有评论,来说两句吧...