
在使用sparksql的时候,除了系统内置的一些函数之外,我们还可以自定义UDF函数,然后在查询的时候使用这个UDF函数即可。整个UDF函数的流程如下:
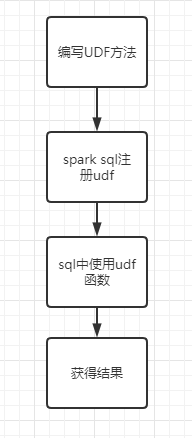
这个UDF其实就是一个方法,在使用的时候传入一个值然后返回一个新值,也就是传入一个参数,返回一个参数。下面我们用代码来演示一下UDF函数的使用。
package org.example
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.udf
object Demo {
case class UserPoJo(name: String, age: Long, sex: String)
def main(args: Array[String]): Unit = {
//初始化sparksession,这里暂时不允许到集群中,所以简单的编写一个,如果需要运行在集群中,根据之前的文章修改成对应的sparkconf即可。
val session = SparkSession.builder().config(new SparkConf()).appName("demo").master("local[*]").getOrCreate();
//使用spark sql的时候我们都需要在业务代码里面引入下面的依赖,在引入implicits的时候,spark会把对象隐式的转成dataset对象,所以一般这些对象我们可以直接使用即可
import session.implicits._
var user = Seq(UserPoJo("张三", 12, "男"), UserPoJo("李四", 17, "男"), UserPoJo("王五", 20, "男"))
val userDF = user.toDF()
userDF.createOrReplaceTempView("user")
//注册udf函数
session.udf.register("converToAge", converToAge(_: Int): String)
//使用udf函数
session.sql("select name,converToAge(age) as age1 from user").show()
}
//编写udf方法
def converToAge(age: Int): String = {
age match {
case `age` if age > 18 => "成年"
case _ => "未成年"
}
}
}备注:
1、在上面我们自定义了一个udf函数:converToAge,在编程的时候其实这就是一个方法,具体的逻辑我们可以自由控制。
2、在使用udf之前,必须要先把这个udf函数在session里面注册后才能使用,不注册的话是使用不了的。
运行下,看下效果
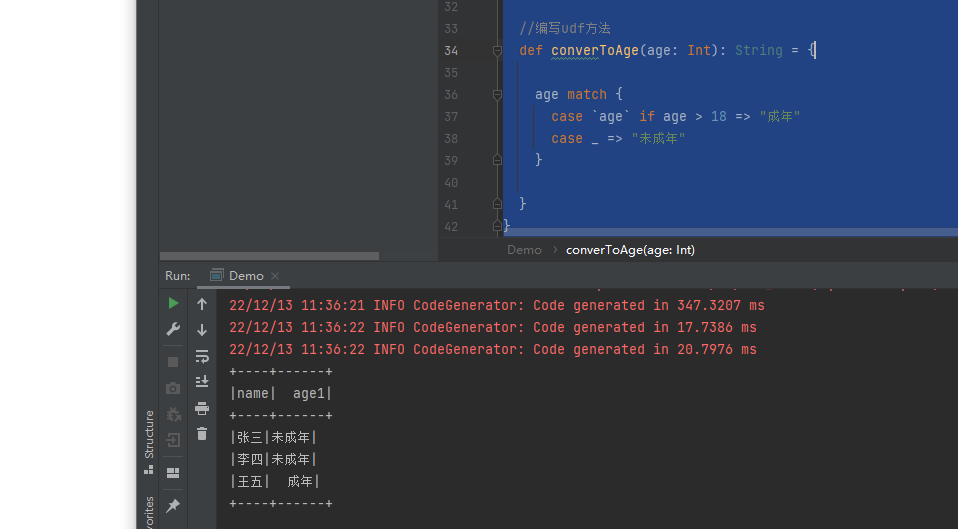
可以看到udf函数生效了。
以上就是UDF函数的使用,非常的简单,就是一进一出,在后面我们还会介绍UDAF,UDTF等函数,到时候再说。








还没有评论,来说两句吧...