
在elasticsearch中,虽然在索引数据的时候,elasticsearch会自动为我们创建mapping,但是我们在真实环境查询的时候,不一定能满足我们想要的需求,因此这里我们手动的创建一下mapping,并且对一些细节性的内容做一些说明。
一、手动创建一个简单的mapping
put test/_doc/_mapping?include_type_name=true
{
"properties": {
"name": {
"type": "keyword"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"article": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"likes": {
"type": "integer"
},
"cts": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}执行结果是:
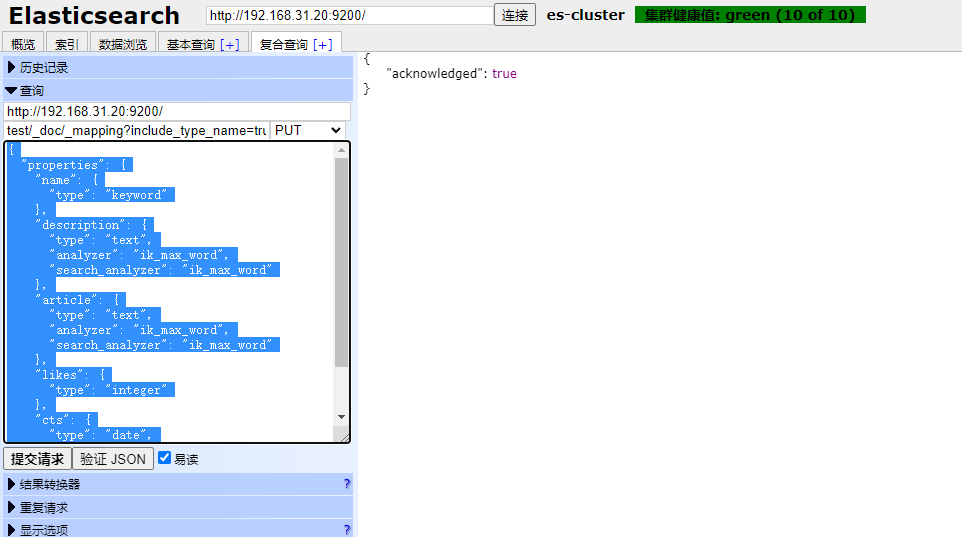
进行验证
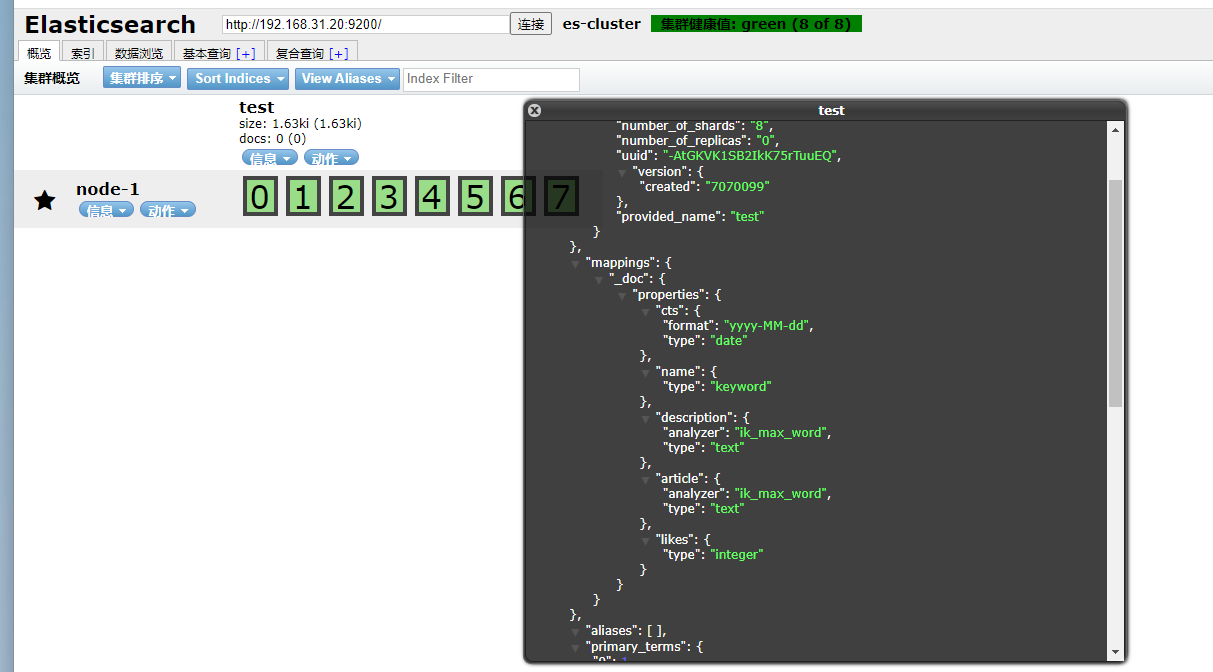
可以看到mapping创建成功了。在这里我们解释下mapping的json含义。
解释如下:
1、在这里我们创建了5个字段,分别的含义是:
| 序号 | 字段 | 说明 |
| 1 | name | 姓名 |
| 2 | description | 文章简介 |
| 3 | article | 文章内容 |
| 4 | likes | 有多少喜欢数 |
| 5 | cts | 发表时间 |
2、这里我们的name字段,业务假设要求全匹配,不能进行模糊匹配,所以我们不需要他进行分词,这里的type直接填写keyword就好。
3、在description和article字段里面,我们要求他进行分词,同时我们需要使用ik分词器,所以这里的type直接填写text即可,然后指定分词器。
4、在likes里面,由于有排序的需要,所以我们使用integer。
5、date类型一般我们需要进行格式化操作。
综合以上我们可以总结出:
1、如果是string类型的字段,我们可以使用keyword或者text类型。如果不需要分词,则直接使用keyword,如果需要分词,则直接使用text类型。
2、keyword不仅应用于string类型,也可以用在其他类型里面,这样索引和查询效率较高。
3、需要涉及到数值排序的场景,字段我们不用keyword,而直接使用对应的integer或者long等类型。
4、在elasticsearch7.x的版本里面更改索引需要添加上?include_type_name=true字段。这是硬性要求。
二、手动控制某些字段不需要被索引
在elasticsearch中,我们每次批量拿过去的字段可能会很多,某些字段我们有时候是不需要被索引的,所以我们在设置mapping的时候也需要进行调整下,那么如何调整呢? 其实很简单,只需要在索引的字段里面添加一个类型 index:true/false即可,例如:
{
"properties": {
"name": {
"type": "keyword"
},
"description": {
"type": "text",
"index":false
},
"article": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
},
"likes": {
"type": "integer"
},
"cts": {
"type": "date",
"format": "yyyy-MM-dd"
}
}
}上面我们的description设置的index是false,所以这时候description他是不能被搜索的,只能通过其他搜索条件搜索到这个文档,最后把这个字段取出来用于显示。
最后总结下:
1、如果设计到后操作elasticsearch的索引变更的话,需要在url上添加:include_type_name=true
2、对于索引的变更,我们不能变更分片的数量,如果涉及到分片数量的修改,则需要重构索引。








还没有评论,来说两句吧...