
在elasticsearch中,如果我们没有事先为某个索引创建mapping的话,那么我们直接插入数据的时候,elasticsearch会根据插入的数据值进行反推mapping,同时我们也可以提前为某个index创建一份mapping,这样子的话可能更有利于我们规划搜索引擎系统的使用。关于自动创建mapping这块暂时不提,我们只介绍手动创建mapping这块。
先直接上一个案例,创建一个设备的index,并且为设备的index创建mapping
put /devices
{
"mappings": {
"properties": {
"device_uuid": {
"type": "keyword"
},
"device_name": {
"type": "keyword"
},
"device_cts": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}然后我们执行一下,可以看到执行结果
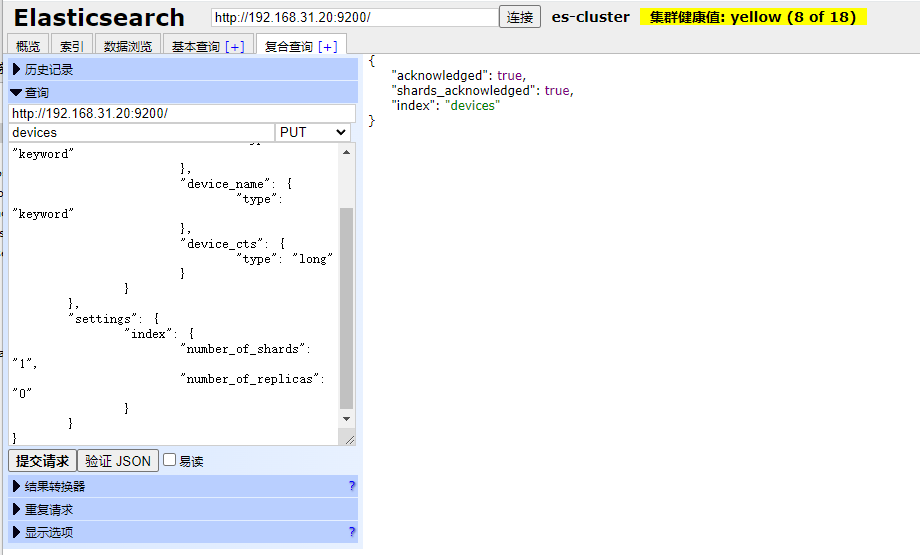
这时候我们就创建成功了。下面分别介绍一下。
1、在创建索引的时候,我们需要定义下索引的分片数和副本数,使用下面的模块
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}2、在elasticsearch7.x里面,是不需要指定type(这里的type是_type,可以理解成数据库中的表,在elasticsearch7.x的版本里面,只有一个固定的type为_doc)的,只需要直接创建mapping的properties就可以了。示例如下:
"mappings": {
"properties": {
"device_uuid": {
"type": "keyword"
},
"device_name": {
"type": "keyword"
},
"device_cts": {
"type": "long"
}
}
}上面是我们简单的创建index的需求,由于elasticsearch有动态创建mapping的功能,所以动态创建的mapping在我们查看的时候其实和这块是差不多的。
备注下:
1、使用手动创建mapping能更好的方便于我们对于搜索引擎的规划使用。
2、像上面的案例,我们创建了mappings之后,如果索引的时候有超出定义的字段的话,那么elasticsearch会自动增加mapping的字段映射信息。如果我们不希望elasticsearch在索引的时候有除我们规定之外的字段被映射和存储的话,我们需要考虑下mapping的严格模式,只需要在mappings配置里面添加如下配置:
"dynamic": "strict",
示例如下:
put /devices
{
"mappings": {
"dynamic": "strict",
"properties": {
"device_uuid": {
"type": "keyword"
},
"device_name": {
"type": "keyword"
},
"device_cts": {
"type": "long"
}
}
},
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
}
}严格模式比较利于我们在规划使用搜索引擎的时候对数据进行固定,避免产生很多的“脏数据”。
3、elasticsearch的mapping一旦创建之后将不能被修改,这里的修改主要是之前存在的字段类型这些不能被修改,因为倒排索引已经创建了,所以是无法被修改的,但是我们可以手动新增字段。
4、在elasticsearch中,我们自定义mapping之后,如果是严格模式是无法插入除mapping定义之外的字段的,那有时候我们数据有变动的话,怎么办呢?这时我们可以修改mapping的设置,例如:添加一个字段映射,设置的语法如下:
put /${index_name}/_mapping
新的json下面列举下:
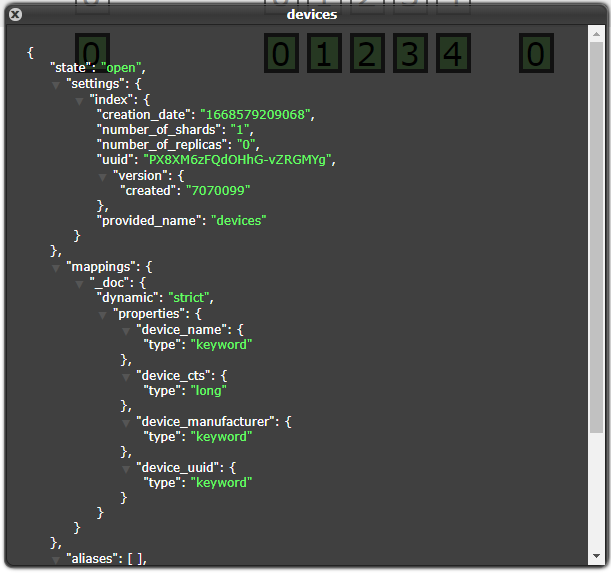
put /devices/_mapping
{
"properties":{
"device_manufacturer":{"type":"keyword"}
}
}上面的案例就是向devices索引里面添加一个device_manufacturer字段。这种添加方式适用于动态模式、静态模式和严格模式。添加后即可插入新的字段数据了。
切记修改mapping只能新增字段,不能修改已存在的字段。
5、在创建mapping的时候,所有的字段我们可以规定当前的字段是索引+存储的方式还是索引+不存储的方式或者是不索引+存储的方式。具体的配置如下:
1)不索引只存储的语法设置
{
"properties": {
"key1": {
"type": "keyword",
"index": false
}
}
}2)索引但是不存储的语法设置
put /${indexname}
{
"settings": {
"index": {
"number_of_shards": "1",
"number_of_replicas": "0"
}
},
"mappings": {
"_source": {
"excludes": ["key2"]
},
"properties": {
"key1": {
"type": "long"
},
"key2": {
"type": "keyword"
}
}
}
}在上面我们在_source节点里面把不需要存储的字段放在excludes里面就可以了,然后我们插入数据就会发现,可以根据key2进行搜索,但是不能直接取出来key2对应的值。
3)索引并且存储的语法设置
这里其实不用设置,默认就是这种
6、在创建mapping的时候,一个字段可以有多个类型,这个在前面我们介绍下,下面演示一下:
{
"description": {
"type": "text",
"analyzer": "ik_max_word",
"fields": {
"keyword": {
"ignore_above": 256,
"type": "keyword"
}
}
}
}







还没有评论,来说两句吧...