
在上一篇文章《Mycat数据库中间件系列(二)Mycat2配置主从读写分离》我们介绍了使用mycat配置数据库的读写分离,然后在最后的演示查询的时候,可以发现我们使用:
select * from school_branch;
这里查询的时候,会随机从主节点和从节点进行查询,那么我们面对流量大的情况下才会做读写分离,我们更希望他在主节点上写,在从节点上查,而不要在主节点查询,这时候该怎么办呢?
首先我们需要把主节点定义为写节点,修改${mycat_home}/conf/datasources下的主节点文件,这里我们的主节点是prototypeDs.datasource.json,进入到这个文件,修改里面的instanceType,把值修改为WRITE。示例如下:
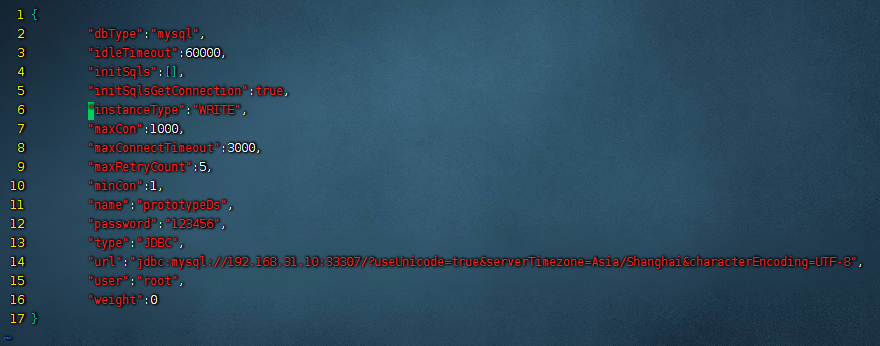
接着我们再修改下从节点,也在${mycat_home}/conf/datasources这个目录下,把从节点的instanceType修改为READ。
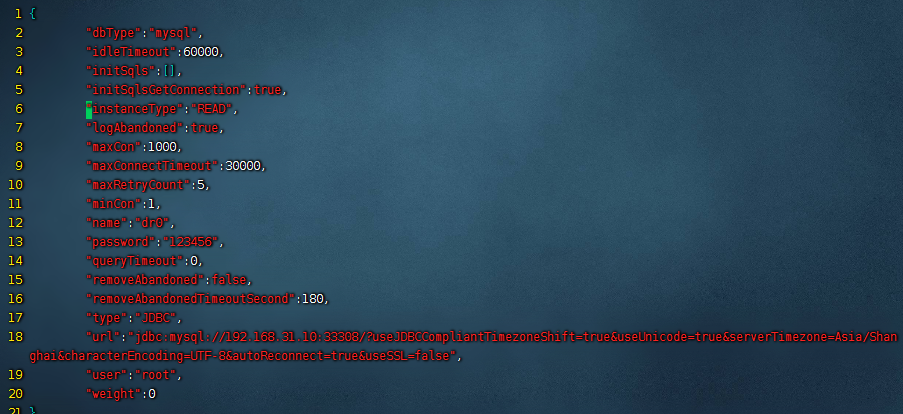
修改之后,我们再修改下集群的负载均衡策略,修改的文件在${mycat_home}/conf/clusters目录下的prototype.cluster.json文件(不同集群名称对应的文件不同,根据实际情况进行修改),修改内容是把readBalanceType修改为BALANCE_ALL_READ。
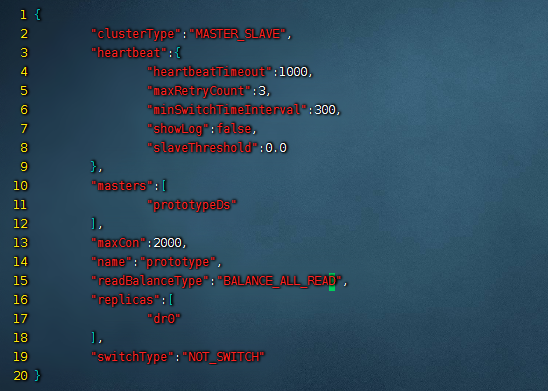
然后我们重启下mycat,再使用navicat查询下:
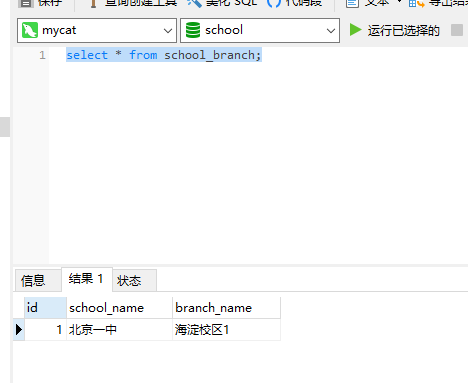
可以发现无论如何刷新,都只会从从节点上查询数据,而不会去主节点上查询数据了。
备注:
1、在mycat中,查询负载均衡策略有四种,分别是:
BALANCE_ALL(默认值) 从集群中所有数据源查询数据 BALANCE_ALL_READ 从集群中允许读的数据源查询数据 BALANCE_READ_WRITE 从集群中允许读写的数据源,但允许读的数据源优先 BALANCE_NONE 从集群中写数据源查询数据








还没有评论,来说两句吧...