
在实际的业务中,例如电商的场景里面,对于某一个商品的uv访问量我们会比较看重,为什么呢?这主要是由于我们需要做智能推荐。同时我们后台也可能存在数据统计,哪些商品每天的访问量比较靠前。这时候我们怎么办呢?
有一些小伙伴说我们把用户的访问日志记录做一下存储,每日进行统计,如果数据量比较大,我们可以上hadoop,spark等等。
但是试问一下,你们先找团队很小,可能不到5个后端开发,人手严重不够,此时你会上大数据这一套吗?肯定不会的。所以这里今天给大家介绍一个还是依靠redis来做数据统计,但是使用的数据类型是redis提供的HyperLogLog。
下面我们直接演示一下:
假设先找有一个商品id为1,用户id是1001 1002 1003 1004等等,那么实际情况如下:
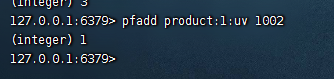
1)用户1002来访问了id为1的商品,此时我们可以添加一个用户
pfadd product:1:uv 1002
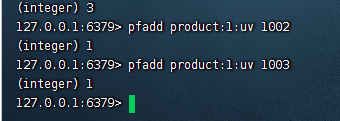
2)此时用户1003也来访问了id为1的商品,我们再添加一个用户
pfadd product:1:uv 1003
以此类推,来一个用户我们就添加一个。
3)统计下有多少人访问了id为1的商品
pfcount product:1:uv
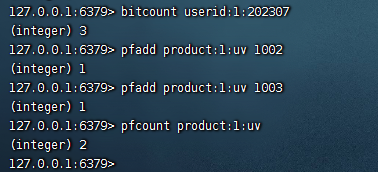
这里我们添加了两条数据,统计也是2,数据是合理的。
以上就是我们使用HyperLogLog数据类型实现统计的效果
备注:
1、HyperLogLog数据类型占用的空间很小,计算2^64个元素大概只需要12KB的内存空间 2、HyperLogLog是存在误差的,大概是在0.81%,所以这种类型只能用于统计哪些不需要很精准的场景,如果需要统计很精准的场景,需要使用其他的数据结构,例如set。 3、HyperLogLog数据类型会实现自动去重,不会有重复的数据统计。








还没有评论,来说两句吧...