
Elasticsearch集群在业务高峰的时候,我们的线上业务出现了报价,各种查询缓慢,索引缓慢,查看了相关的日志,大量的请求出现报错,直接被reject了。怎么办呢?
这篇文章我们介绍下正对大量的reject报错改如何进行分析。
可能出现的原因:
我们知道所有的请求落到elasticsearch之后,都是被线程池处理的,当线程池满了之后,就会直接导致请求被reject拒绝掉。所以我们找到了原因。那么如何排查呢?
小技巧:可以通过请求:http://192.168.31.30:9200/_cat/thread_pool/search?v&h=node_name,name,active,rejected,completed 来查看当前集群的请求情况。,例如:
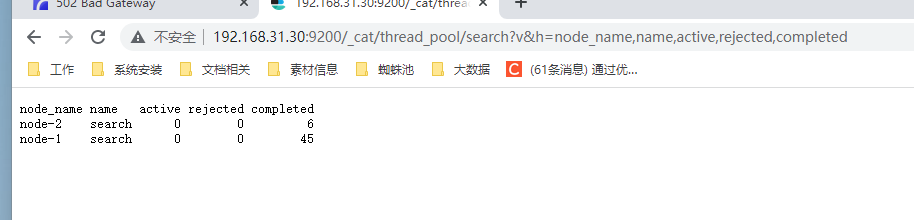
解决思路:
1、我们可以查看下分片,看下分片是否过多,过多的话,则查询就会落到更多的分片上,增加查询时间,占用线程池数量,可以适当根据情况降低下分片数量。
2、为集群的存储使用ssd,提升磁盘I/O的吞吐量。
3、通过api取消掉部分任务,在elasticsearch5.x之后,支持取消正在进行的查询任务。
GET _tasks?nodes=node-1,node-2 POST _tasks/oTUltX4IQMOUUVeiohTt8A:12345/_cancel
4、把查询结果存储到缓存里面,例如:redis等,使大部分请求不走elasticsearch存储。








还没有评论,来说两句吧...