
上一篇我们演示了如何安装部署一个datax-web。这一篇我们分解下任务,演示下可视化数据数据迁移。迁移方式为mysql迁移到另外一个mysql。
背景
由于这里没有部署多的服务器,我们拟定使用同一个数据库,创建两张一模一样的表user表和user1表,我们先手动向user表插入一条数据,然后使用datax进行数据的迁移。这里的数据我们也分为全量迁移和增量迁移。
一、全量迁移
1.1、我们创建一下数据源
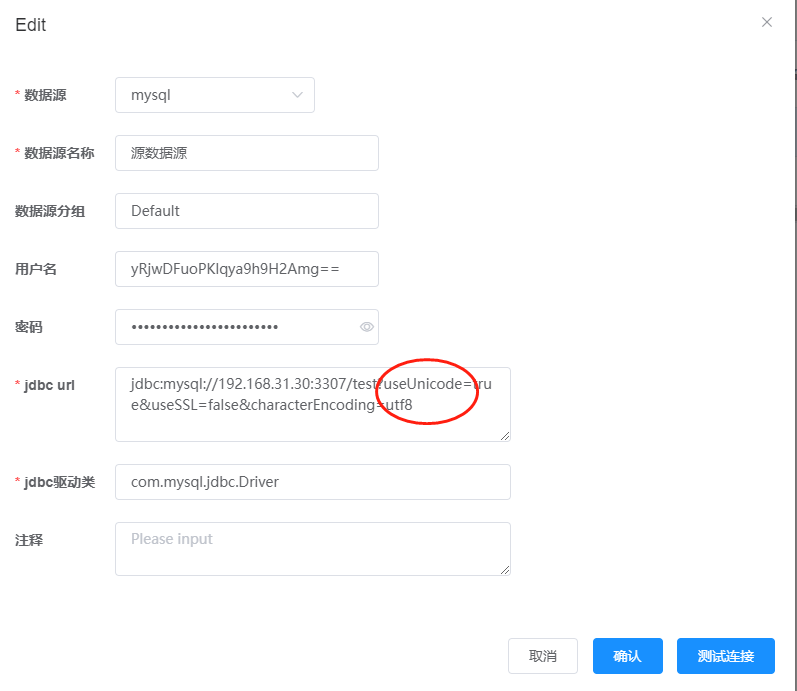
这里由于是同一个数据库,所以我们创建的源数据库和目标数据库是一样的。首先创建源数据源,点击数据源管理,点击添加
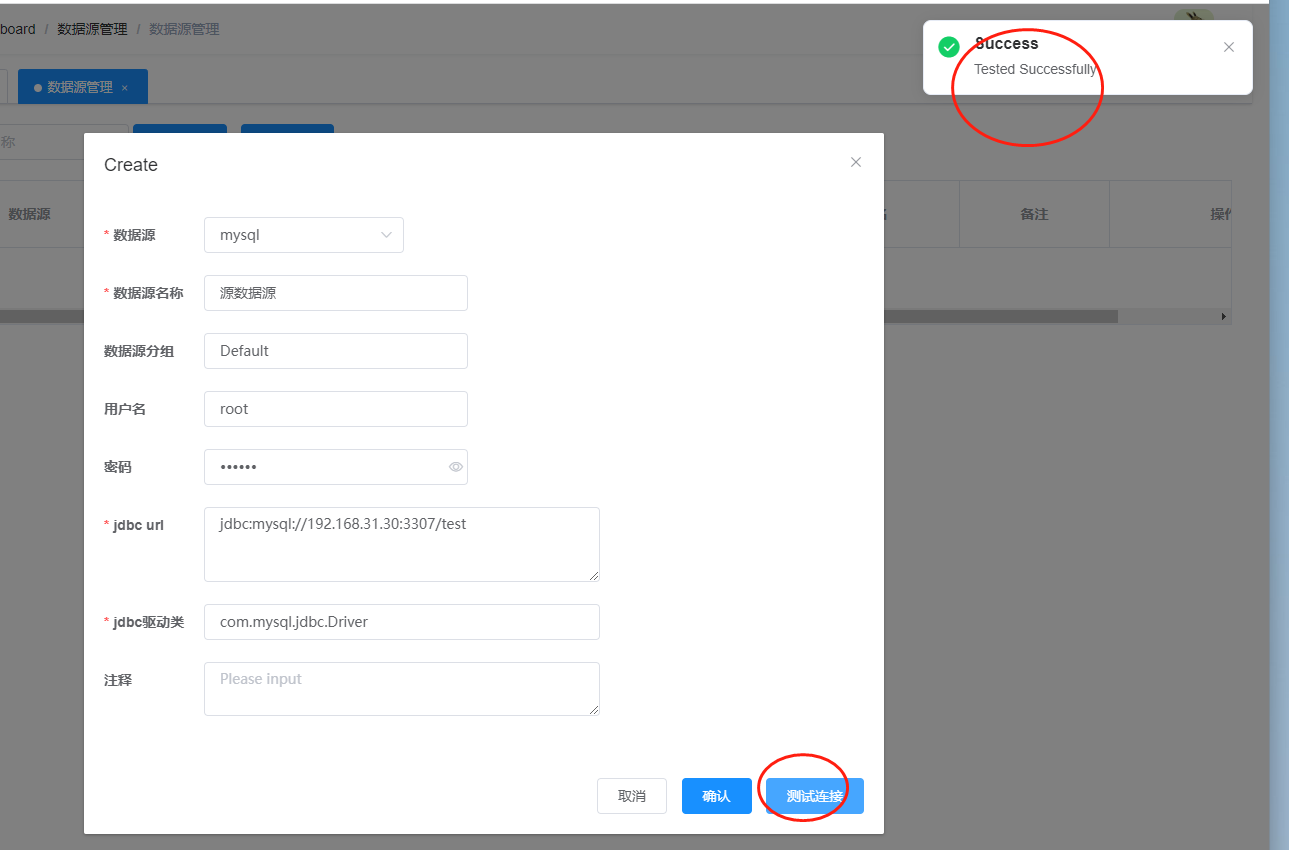
接着我们创建一个目标数据源
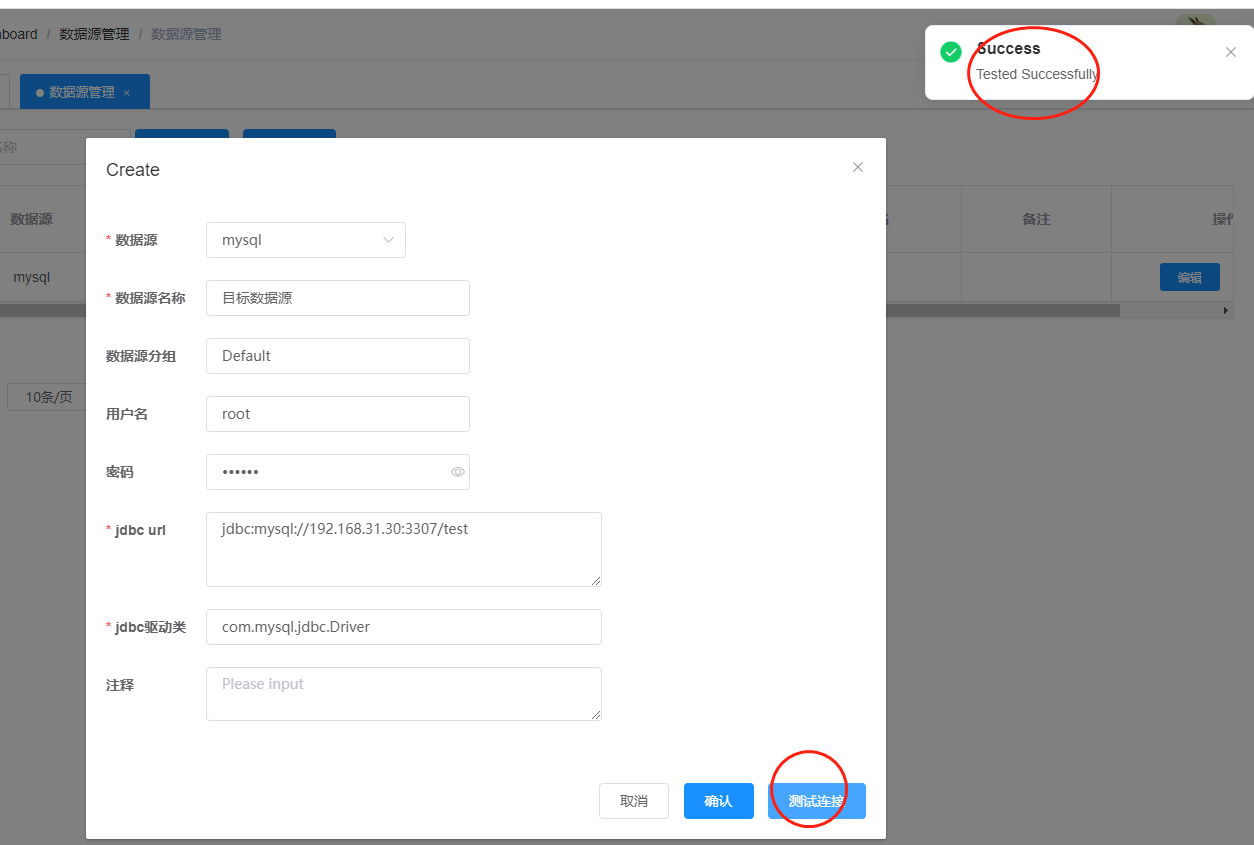
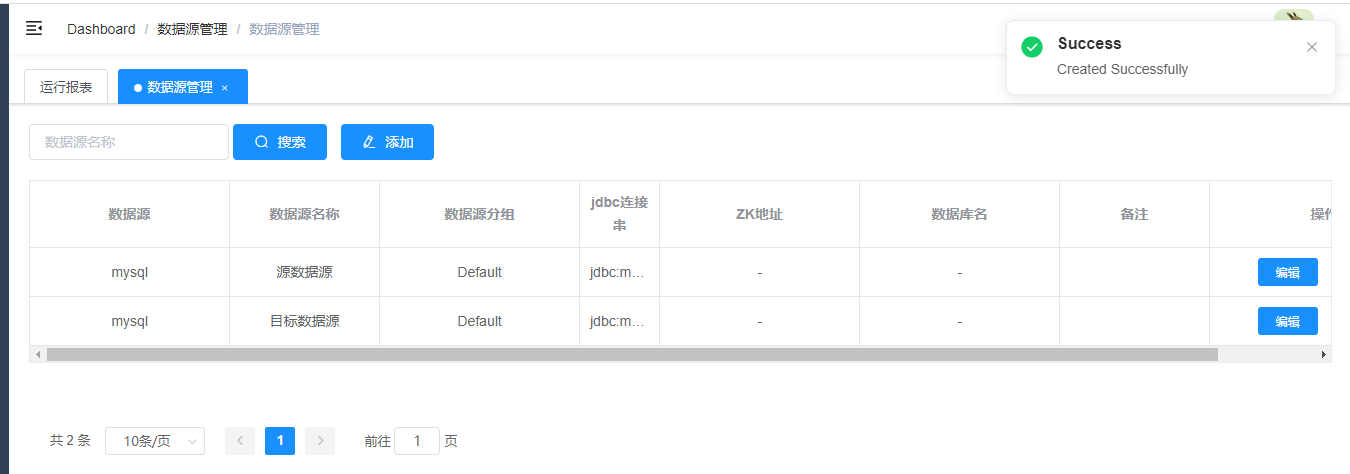
到这里我们的源数据源和目标数据源都已经创建好了。
1.2、构建一个任务
点击左侧的任务管理->任务构建->步骤1
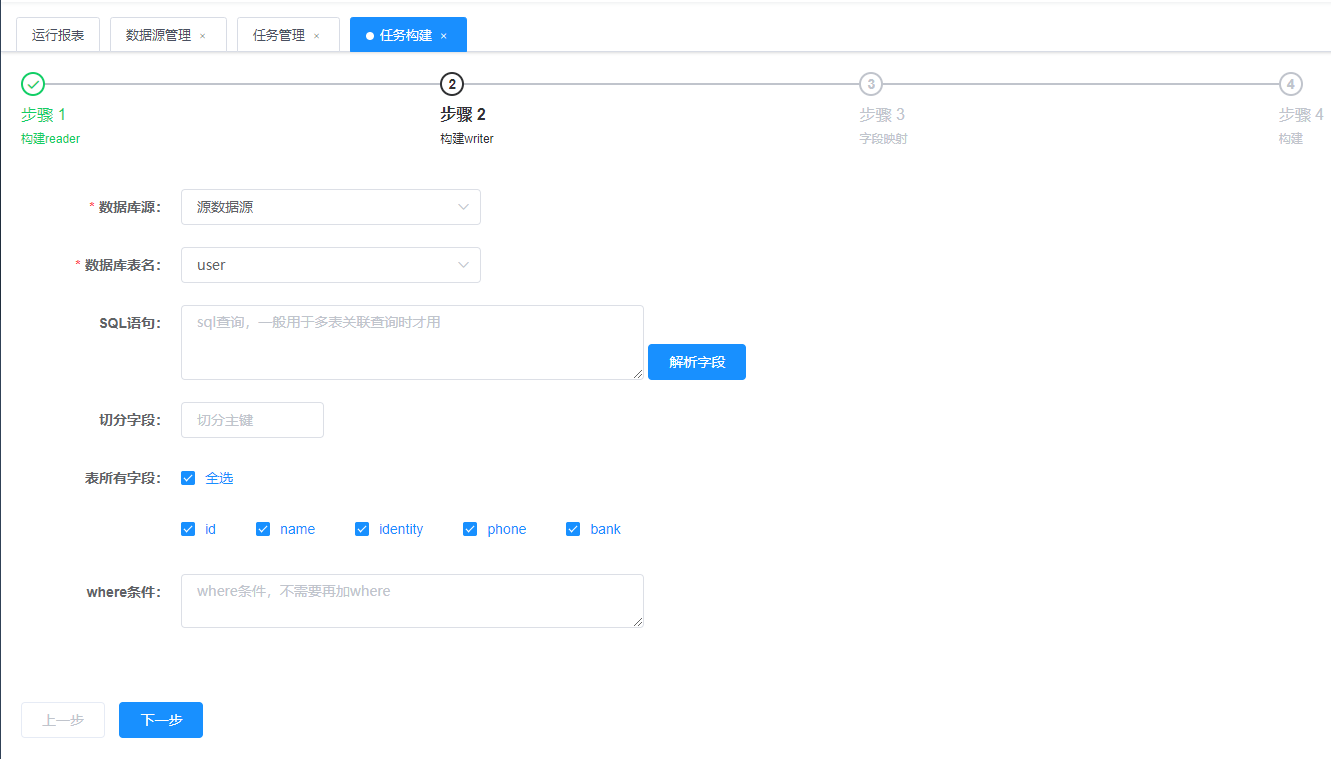
点击下一步,进入步骤2
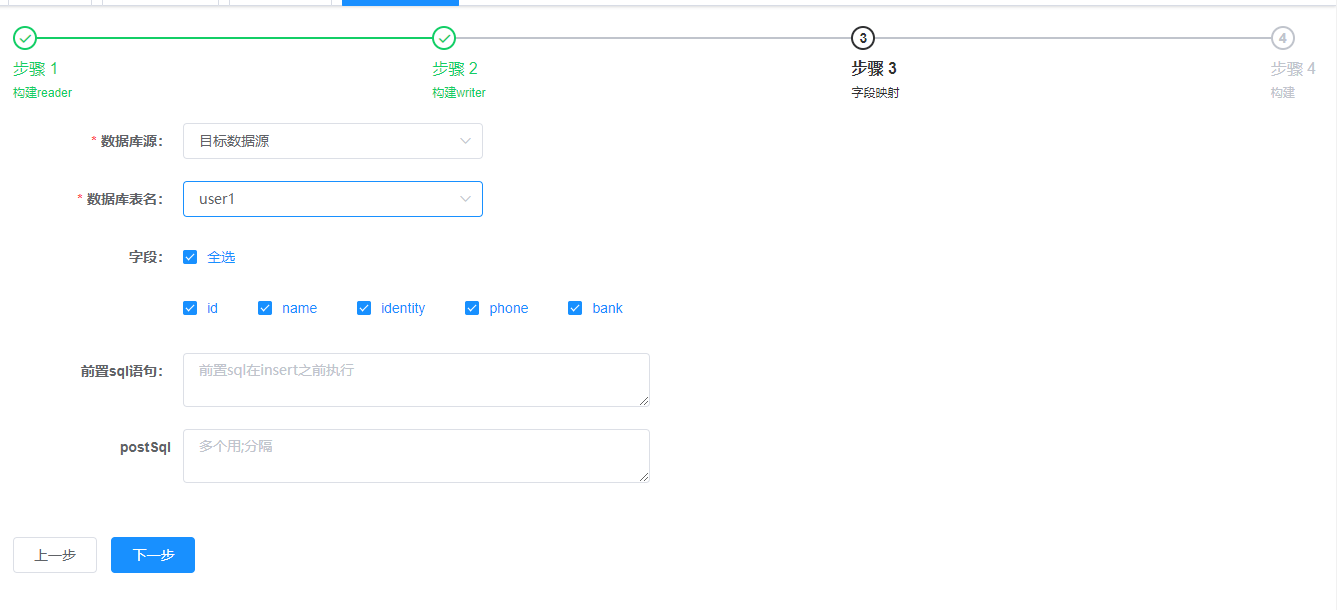
点击下一步,进入步骤3
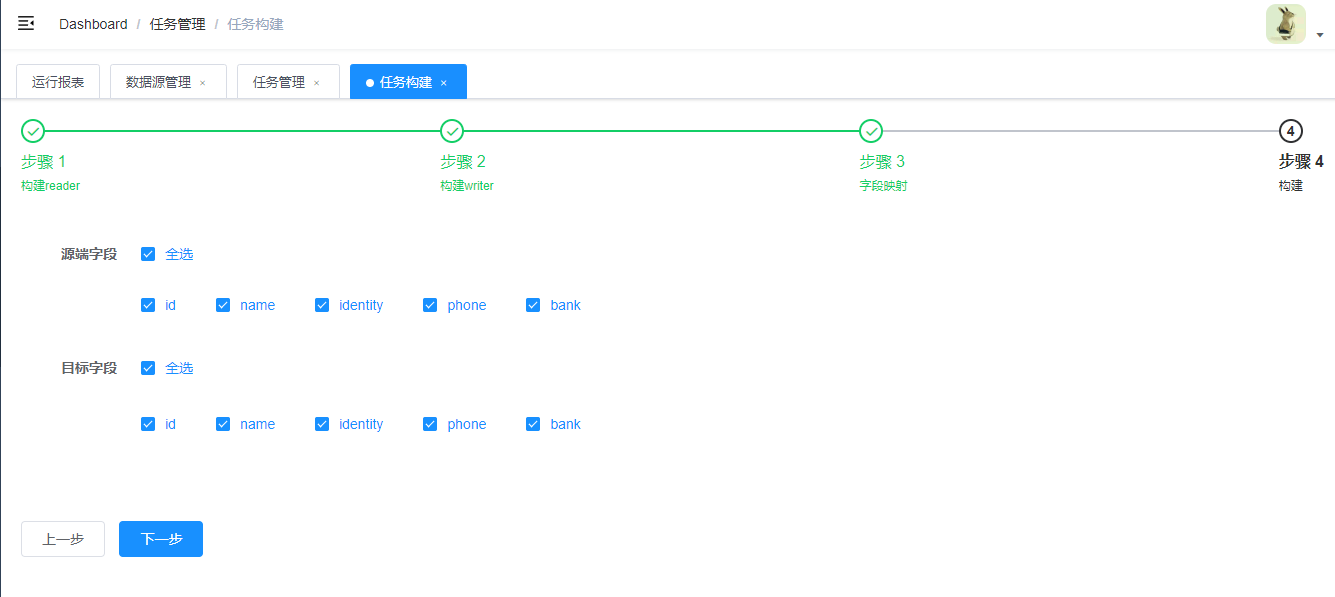
点击下一步,进入步骤4,点击构建
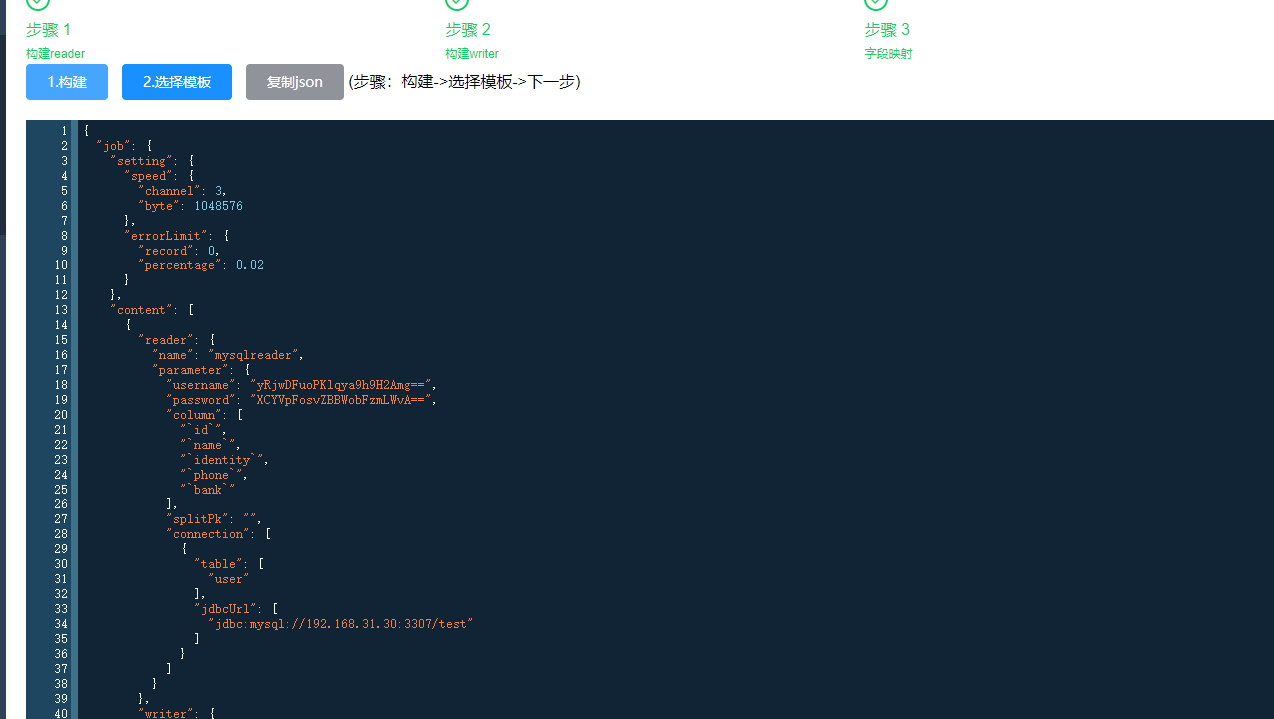
这里就会生成对应的json数据。此时我们要的就是这个json数据。
然后点击任务管理->添加
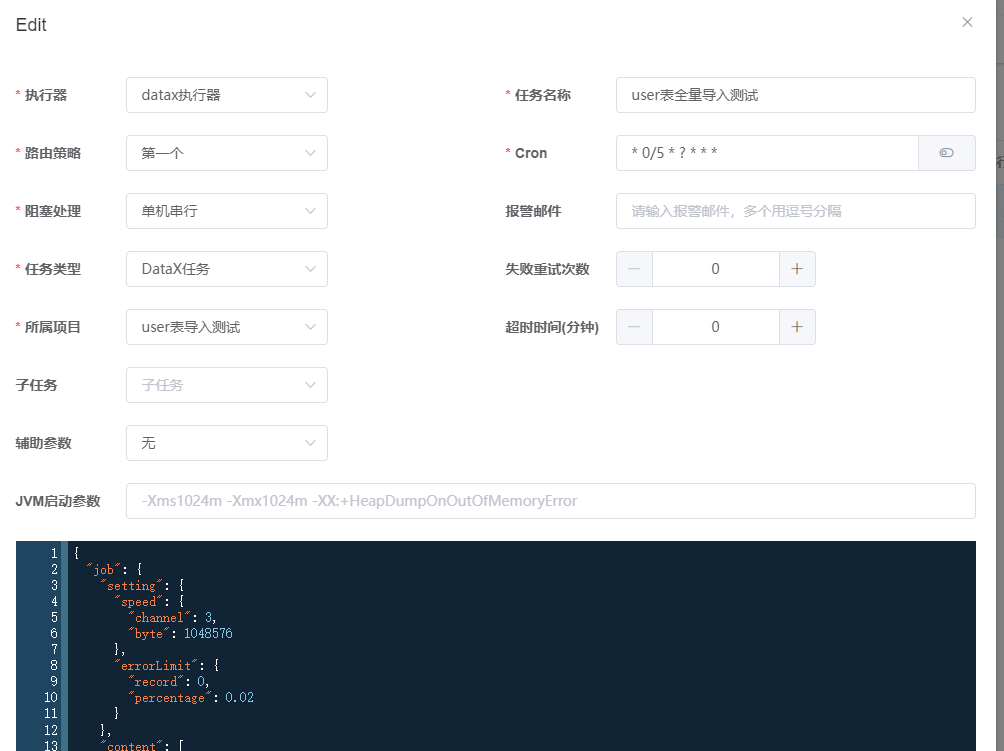
上面的选项根据情况进行填写即可,下面的json就使用刚才的构建的json。然后点击保存。
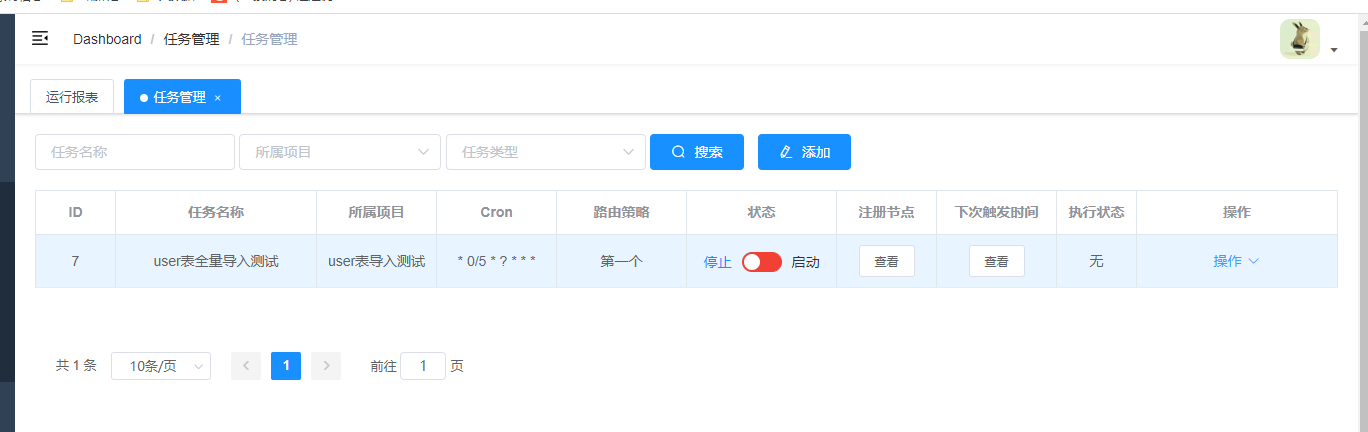
此时我们可以看到这个任务是停止运行的状态。
1.3、查看对应的表数据
我们可以看看user表和user1表
user表是有数据的,user1表是没有数据的。
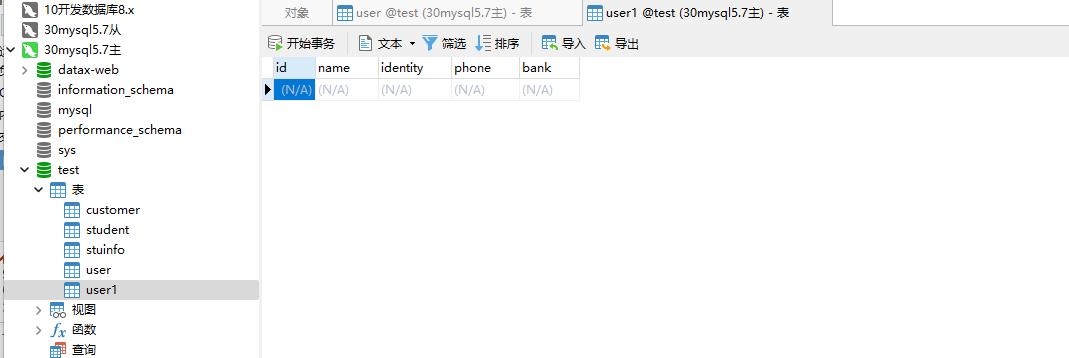
1.4、测试运行一下
进入datax-web的界面上,进入到任务管理点击,找到我们刚才配置的任务,最右侧有一个操作按钮,点击下执行一次。
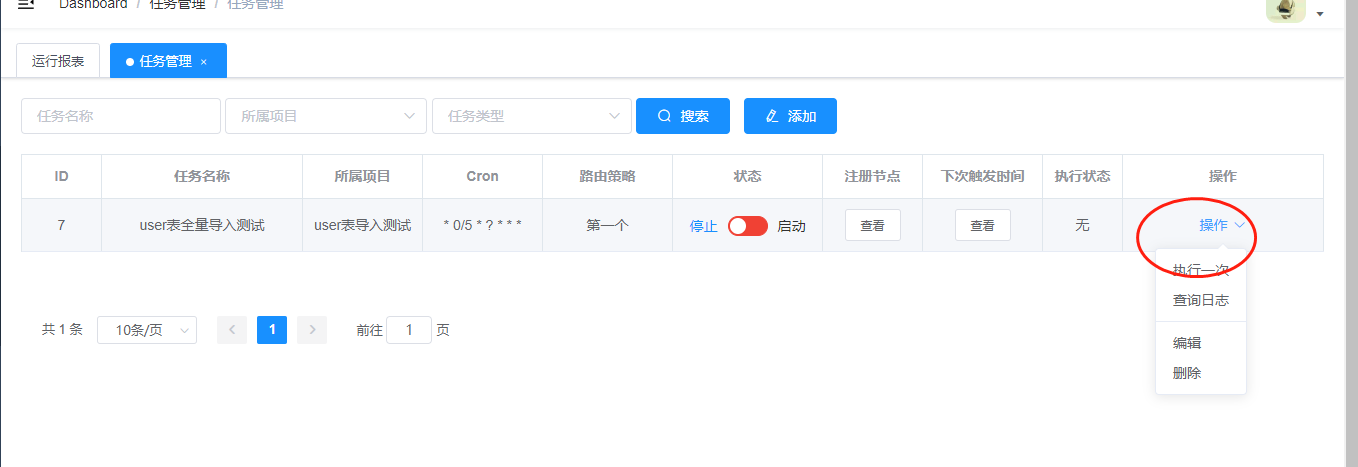
提示执行成功的时候,我们进入到日志界面,查看下日志。
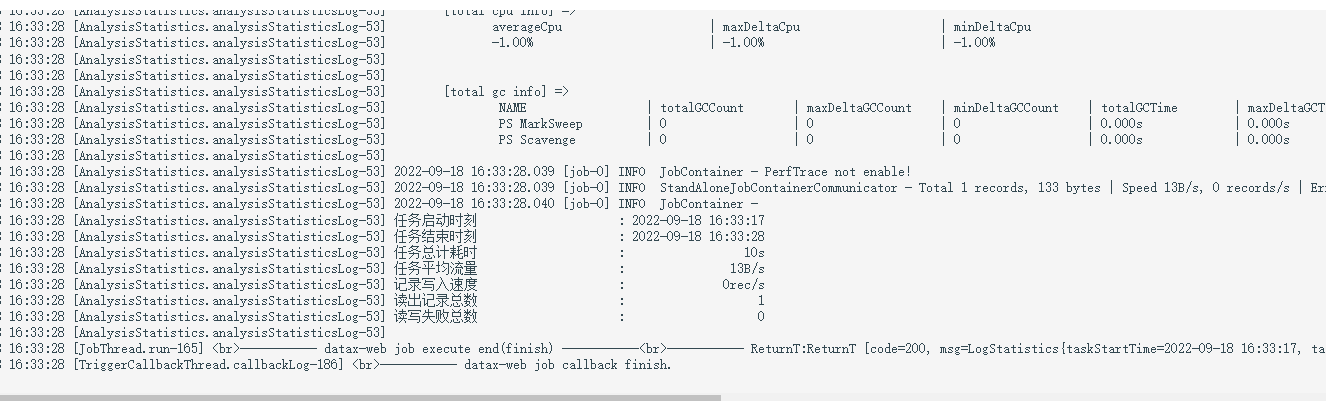
我们可以看到具体日志是没问题的,都执行成功了。
此时再回到日志列表中。
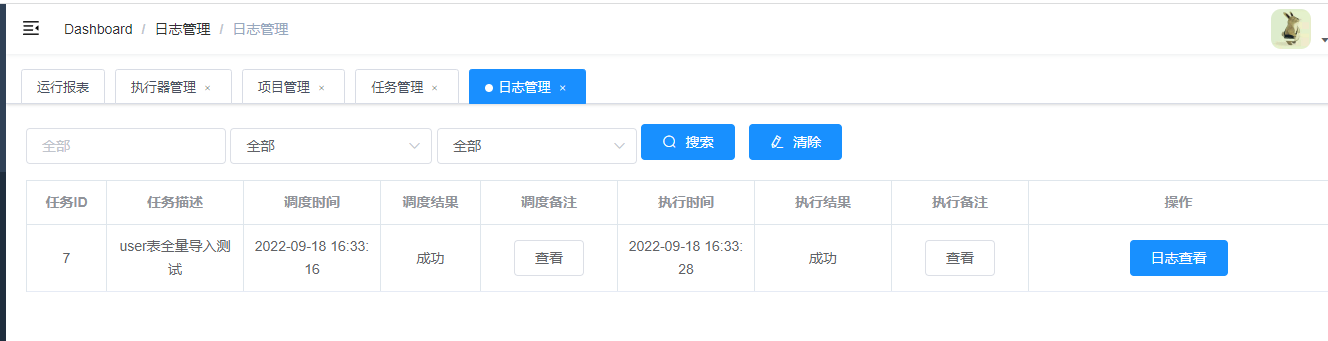
也是成功的。然后我们去看看数据库的数据,user1表是否有数据。
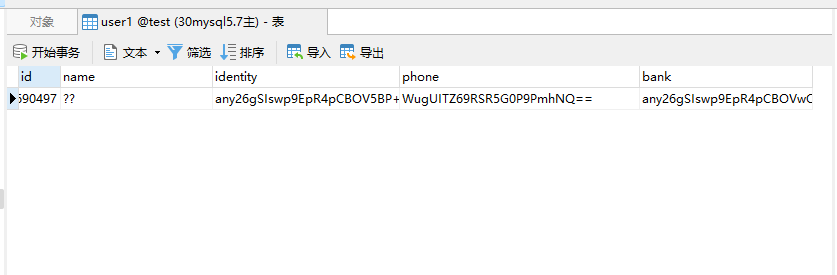
可以看到数据已经过来了。但是有没有发现一个问题,中文乱码了。那怎么办呢?我们还记得在jdbc连接里面,我们的url后面会带参数吗?回到数据源给他添加上。
?useUnicode=true&useSSL=false&characterEncoding=utf8
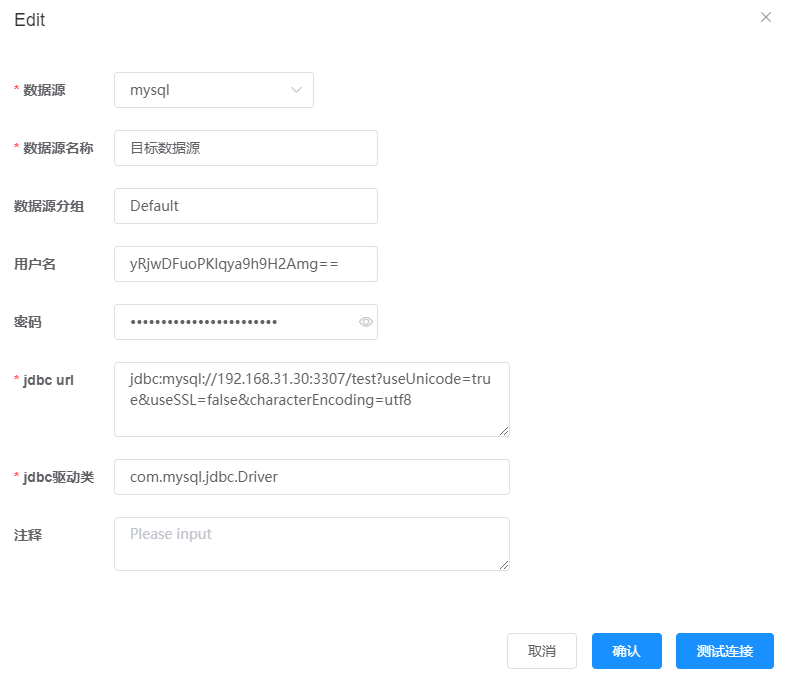
改完这里之后,由于我们的任务已经配置过了,json不会自动覆盖,所以需要去把json里面的连接也要添加上。
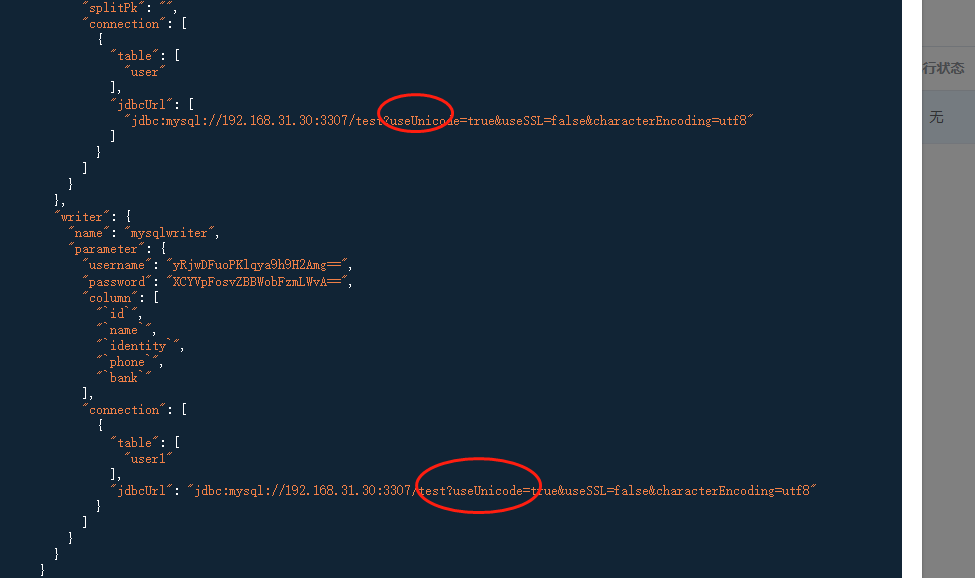
再测试一下。
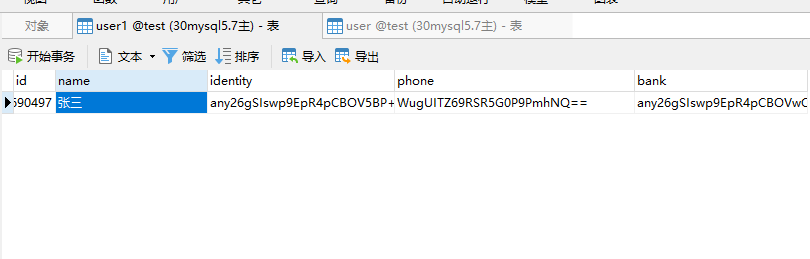
没有问题了。
二、增量数据迁移
2.1、根据id进行增量迁移
增量数据的迁移其实也很简单,可以根据id大于的方式进行迁移,也可以根据时间进行迁移。我们这里先演示下根据id进行迁移。
前面的操作步骤是一样的,只有两个地方需要进行修改,第一个地方是json配置。我们先来看看全量的数据迁移的json配置是什么样子的
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "XCYVpFosvZBBWobFzmLWvA==",
"column": [
"`id`",
"`name`",
"`identity`",
"`phone`",
"`bank`"
],
"splitPk": "",
"connection": [
{
"table": [
"user"
],
"jdbcUrl": [
"jdbc:mysql://192.168.31.30:3307/test?useUnicode=true&useSSL=false&characterEncoding=utf8"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "XCYVpFosvZBBWobFzmLWvA==",
"column": [
"`id`",
"`name`",
"`identity`",
"`phone`",
"`bank`"
],
"connection": [
{
"table": [
"user1"
],
"jdbcUrl": "jdbc:mysql://192.168.31.30:3307/test?useUnicode=true&useSSL=false&characterEncoding=utf8"
}
]
}
}
}
]
}
}那么增量我们需要怎么做呢? 其实就是把读取的部分,改成我们对应的sql语句即可,例如我们通过id进行增量更新,则修改成
"connection": [
{
"querySql": [
"select * from user where id>= ${startId}"
],
"jdbcUrl": [
"jdbc:mysql://192.168.31.30:3307/test?useUnicode=true&useSSL=false&characterEncoding=utf8"
]
}
]完整的json配置文件是:
{
"job": {
"setting": {
"speed": {
"channel": 3,
"byte": 1048576
},
"errorLimit": {
"record": 0,
"percentage": 0.02
}
},
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "XCYVpFosvZBBWobFzmLWvA==",
"splitPk": "",
"connection": [
{
"querySql": [
"select * from user where id>= ${startId}"
],
"jdbcUrl": [
"jdbc:mysql://192.168.31.30:3307/test?useUnicode=true&useSSL=false&characterEncoding=utf8"
]
}
]
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"username": "yRjwDFuoPKlqya9h9H2Amg==",
"password": "XCYVpFosvZBBWobFzmLWvA==",
"column": [
"`id`",
"`name`",
"`identity`",
"`phone`",
"`bank`"
],
"connection": [
{
"table": [
"user1"
],
"jdbcUrl": "jdbc:mysql://192.168.31.30:3307/test?useUnicode=true&useSSL=false&characterEncoding=utf8"
}
]
}
}
}
]
}
}此时我们还需要改这些地方
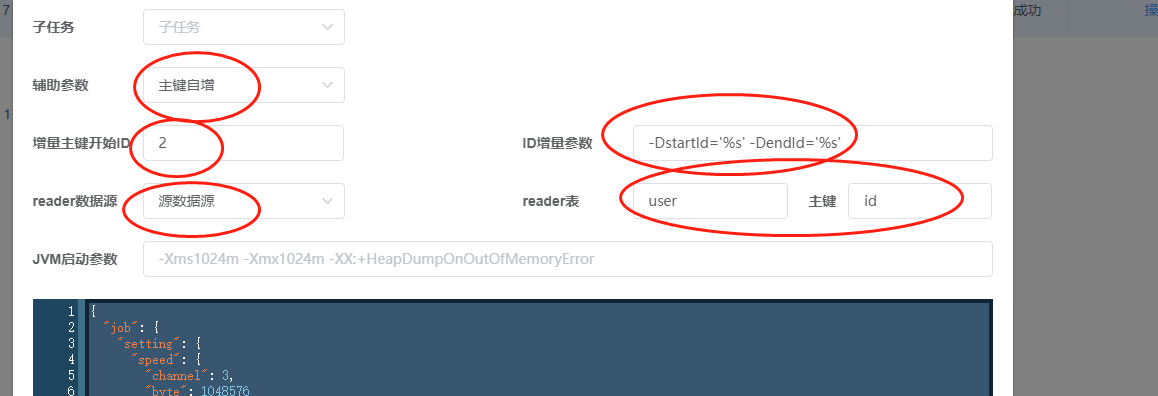
具体解释是:
1.任务类型选DataX任务 2.辅助参数选择主键自增 3.增量主键开始ID选择,即sql中查询ID的开始ID,用户使用此选项方便第一次的全量同步。第一次同步完成后,该ID被更新为上一次的任务触发时最大的ID,任务失败不更新。 4.增量时间字段,-DstartId='%s' -DendId='%s' 先来解析下这段字符串 1.-D是DataX参数的标识符,必配 2.-D后面的startId和endId是DataX json中where条件的id字段标识符,必须和json中的变量名称保持一致,endId是任务在每次执行时获取当前表maxId,也是下一次任务的startId 3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致 4.注意-DstartId='%s'和-DendId='%s' 中间有一个空格,空格必须保留并且是一个空格 5.reader数据源,选择任务同步的读数据源 6.配置reader数据源中需要同步数据的表名及该表的主键
然后我们回到任务列表,开启任务,任务就会自动定时执行,新增的数据都会写入到新的库表里面去。
备注:使用id进行操作的时候,需要选择单机串行的阻塞策略。
2.2、根据时间进行增量迁移
根据时间进行增量迁移也比较简单,跟id一样,更改sql,更改策略。
1)更改sql
"querySql": [
"select * from user where cts >= FROM_UNIXTIME(${lastTime})"
]2)更改配置文件
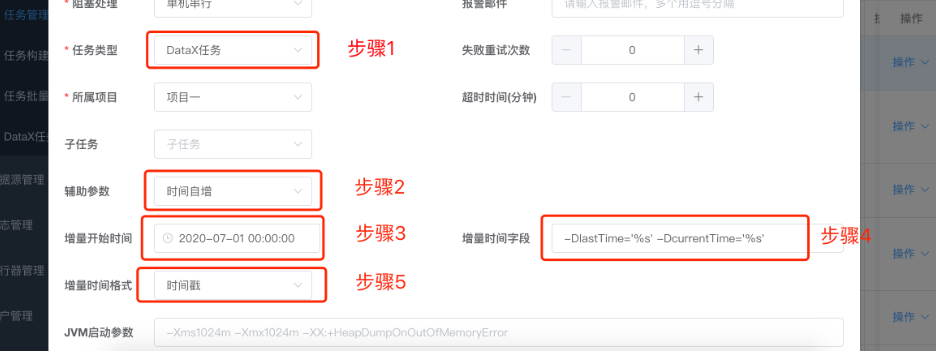
具体参数解释如下:
1.任务类型选DataX任务 2.辅助参数选择时间自增 3.增量开始时间选择,即sql中查询时间的开始时间,用户使用此选项方便第一次的全量同步。第一次同步完成后,该时间被更新为上一次的任务触发时间,任务失败不更新。 4.增量时间字段,-DlastTime='%s' -DcurrentTime='%s' 先来解析下这段字符串 1.-D是DataX参数的标识符,必配 2.-D后面的lastTime和currentTime是DataX json中where条件的时间字段标识符,必须和json中的变量名称保持一致 3.='%s'是项目用来去替换时间的占位符,比配并且格式要完全一致 4.注意-DlastTime='%s'和-DcurrentTime='%s'中间有一个空格,空格必须保留并且是一个空格 5.时间格式,可以选择自己数据库中时间的格式,也可以通过json中配置sql时间转换函数来处理
以上就是我们使用datax进行数据库的全量数据迁移和增量数据迁移。








还没有评论,来说两句吧...