
上一篇文章《分布式调度系统Apache DolphinScheduler系列(三)配置datax的全量同步》我们配置了datax的全量同步,这里的话我们还可以配置增量同步,增量同步也满足很多的一些场景,例如数据仓库环境。下面直接介绍下:
一、准备数据源
在真实环境里面我们会涉及到不同的数据源,这里为了演示,我们模拟两个数据源,在同一个mysql上创建两个库,每个库分别创建一个user表,并且插入数据,因此执行下下面的sql:
create database user1; use user1; CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL COMMENT '姓名', `age` tinyint(3) DEFAULT NULL COMMENT '年龄', `cts` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `user1`.`user`(`id`, `name`, `age`, `cts`) VALUES (1, '张三', 11, '2023-03-08 11:17:42'); INSERT INTO `user1`.`user`(`id`, `name`, `age`, `cts`) VALUES (2, '李四', 12, '2023-04-13 11:17:54'); INSERT INTO `user1`.`user`(`id`, `name`, `age`, `cts`) VALUES (3, '王五', 13, '2023-04-14 11:17:59'); create datase user2; use user2; CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL COMMENT '姓名', `age` tinyint(3) DEFAULT NULL COMMENT '年龄', `cts` datetime DEFAULT NULL COMMENT '创建时间', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
二、首先创建两个数据源
这里我们主要是做mysql的数据同步演示,因此需要添加两个mysql数据源,如下图:
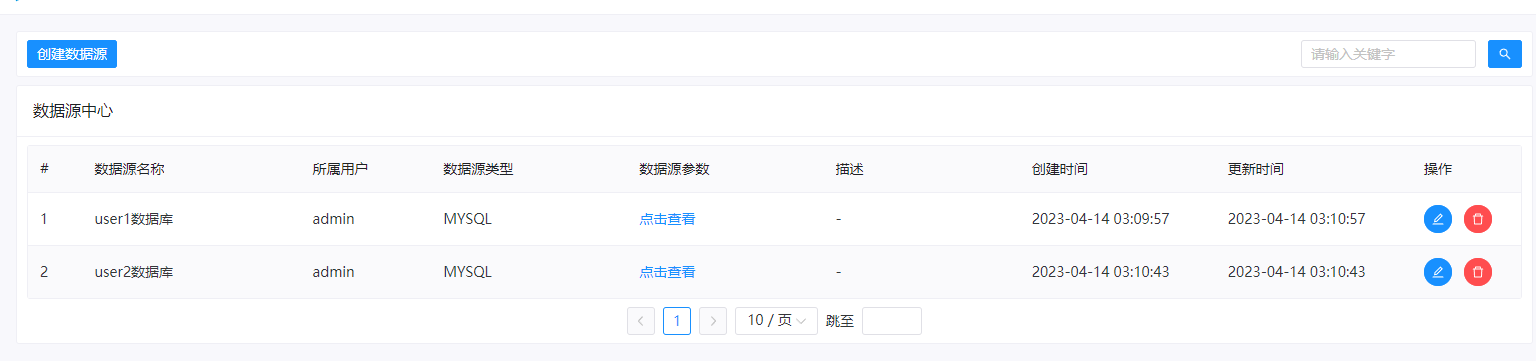
三、创建一个项目
这里的话我们创建一个datax数据同步的项目,创建完成之后,点击进去

四、创建一个工作流
这里我们在工作流定义里面创建一个datax的工作流,拖动一个datax的组件进来:
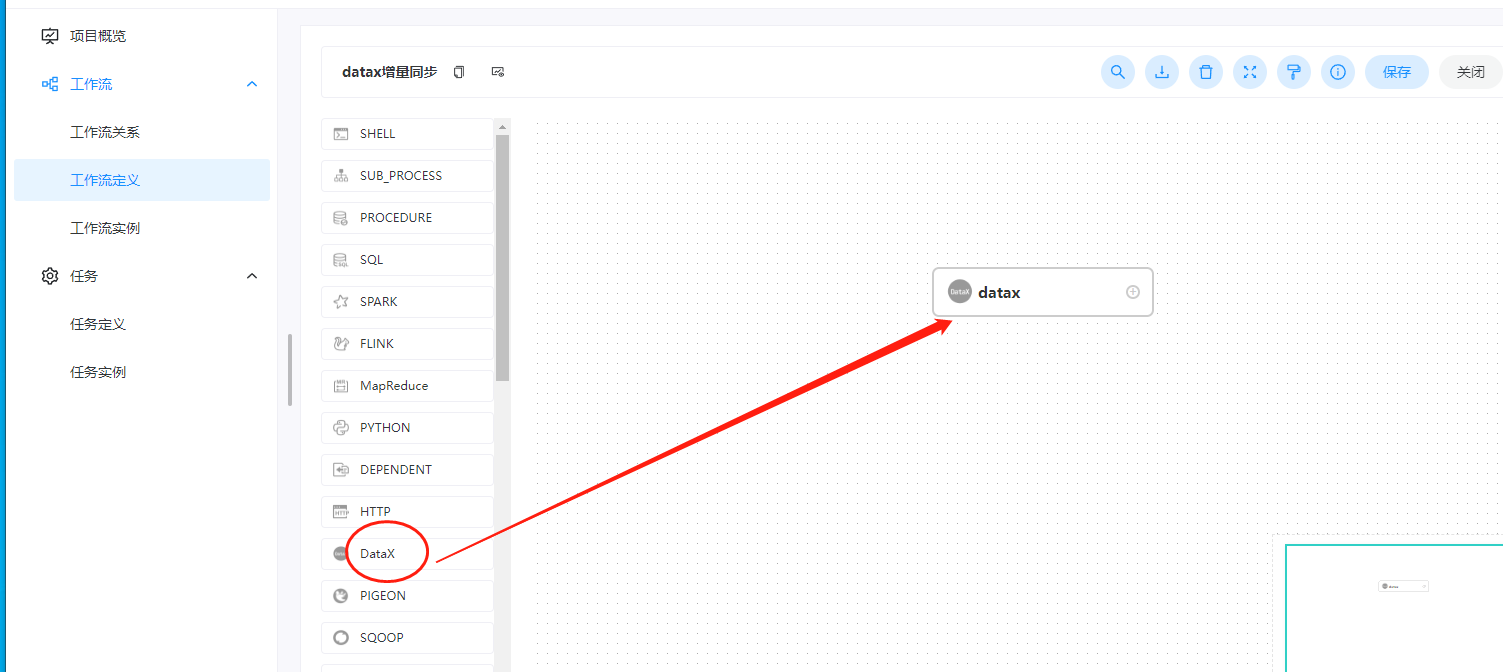
编辑的时候填写的内容如下:
节点名称:这里随便写 运行标志:选择正常即可 描述:这里的话秒速可以随便写 任务优先级:根据实际情况进行选择即可,这里我们保持默认的medium worker分组:这里选择一个自己的分组 环境名称:自定义选择即可 任务组名称:自定义选择即可 组内优先级:自定义输入即可 失败重试次数:自定义输入 失败重试间隔:自定义输入 CPU配额:自定义输入 最大内存:自定义输入
以上指标,我们演示的时候配置如下:
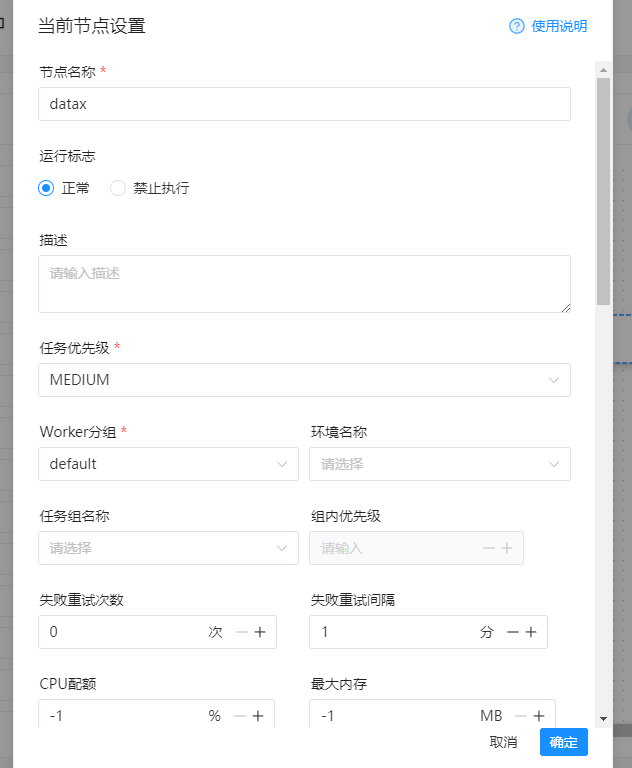
接着配置如下的信息:
延时执行时间:这里我们选择0即可。
超时警告:根据实际情况进行开关
自定义模板:这里我们需要打开,因为这里我们需要自己来配置这个json,这里我们的演示json是:
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [{
"jdbcUrl": [
"jdbc:mysql://192.168.31.10:33306/user1?useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF8&autoReconnect=true&useSSL=false&&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false"
],
"querySql": [
"select id,name,age,cts from user where cts >= '${biz_update_dt}';"
]
}],
"password": "123456",
"username": "root"
}
},
"writer": {
"name": "mysqlwriter",
"parameter": {
"column": [
"`id`",
"`name`",
"`age`",
"`cts`"
],
"connection": [{
"jdbcUrl": "jdbc:mysql://192.168.31.10:33306/user2?useUnicode=true&zeroDateTimeBehavior=convertToNull&characterEncoding=UTF8&autoReconnect=true&useSSL=false&&allowLoadLocalInfile=false&autoDeserialize=false&allowLocalInfile=false&allowUrlInLocalInfile=false",
"table": [
"user"
]
}],
"writeMode": "replace",
"password": "123456",
"username": "root"
}
}
}],
"setting": {
"speed": {
"channel": "1"
}
}
}
}在这个json里面,我们所有的参数都可以使用配置,例如上面我们在sql查询的时候使用了动态字段:biz_update_dt。这里的动态字段定义的话,我们需要在下面的自定义参数里面进行配置:
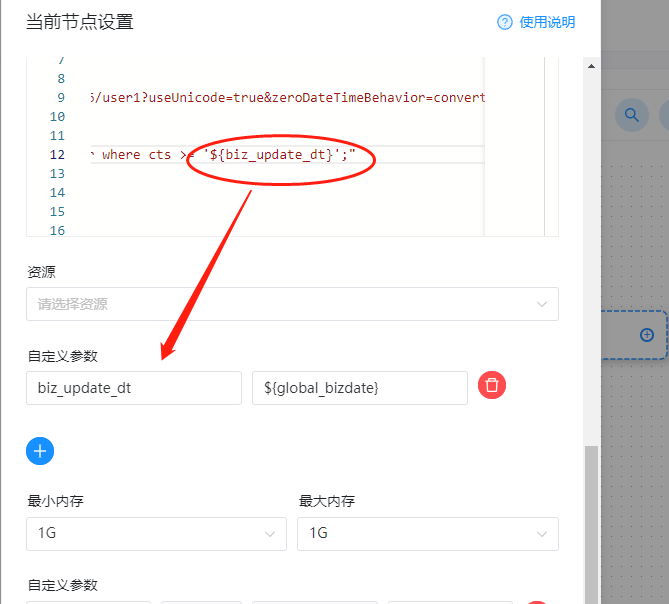
备注:
1、这里我们可以在json里面自定义任何参数,只需要使用如下的格式进行替代即可:
${自定义参数}2、如果在json里面自定义了参数之后,需要在下面的自定义参数里面添加上对应的值,在json里面有几个自定义参数,下面就需要添加几个自定义的参数。
3、在自定义参数里面,这里的参数值也可以使用${自定义参数}的方式进行配置,这里如果自定义参数的值使用动态参数的话,则需要在这个工作流的最顶层进行配置。
4、这里有个非常重要的操作,由于我们这里是增量的操作,因此这里我们的json配置里面,目的数据源里面,我们需要把模式调整下,修改为:
"writeMode": "replace",
上面第四点,非常重要。上面第四点,非常重要。上面第四点,非常重要。
如下图:是我们的整个配置
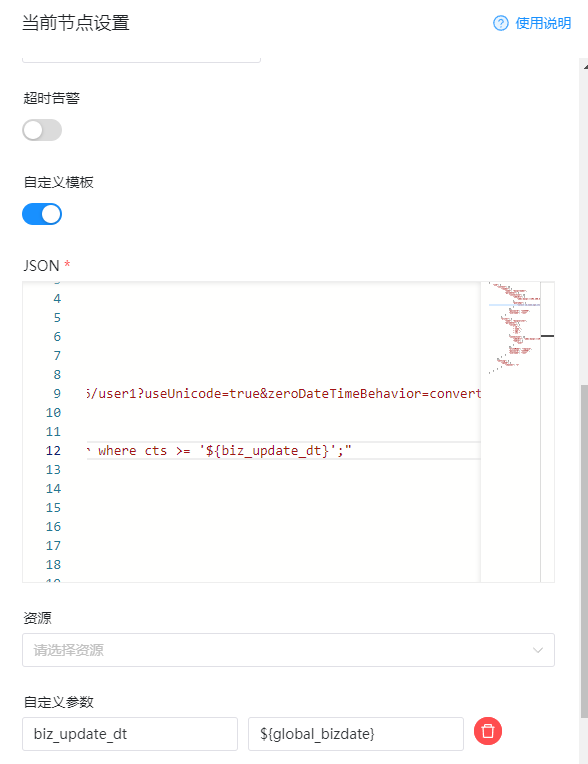
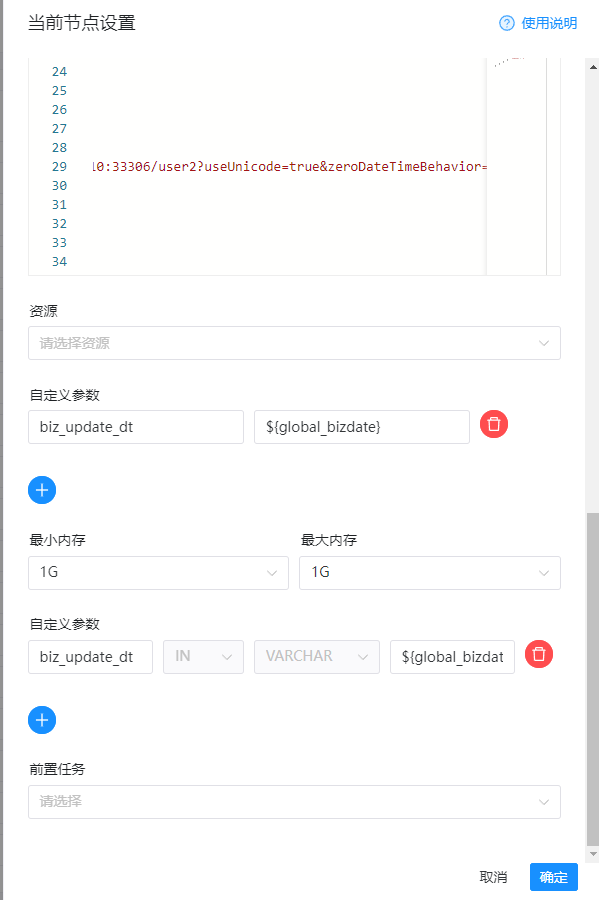
这里我们就配置完毕了,节点点击确定保存
接着我们再点击画布上的保存按钮
这里的保存就是保存整个工作流,在上一步里面我们配置了一个自定义参数:${global_bizdate},这里的话我们增量同步是根据时间来的,因此这里我们需要在这里定义下这个全局的变量参数,如下图:
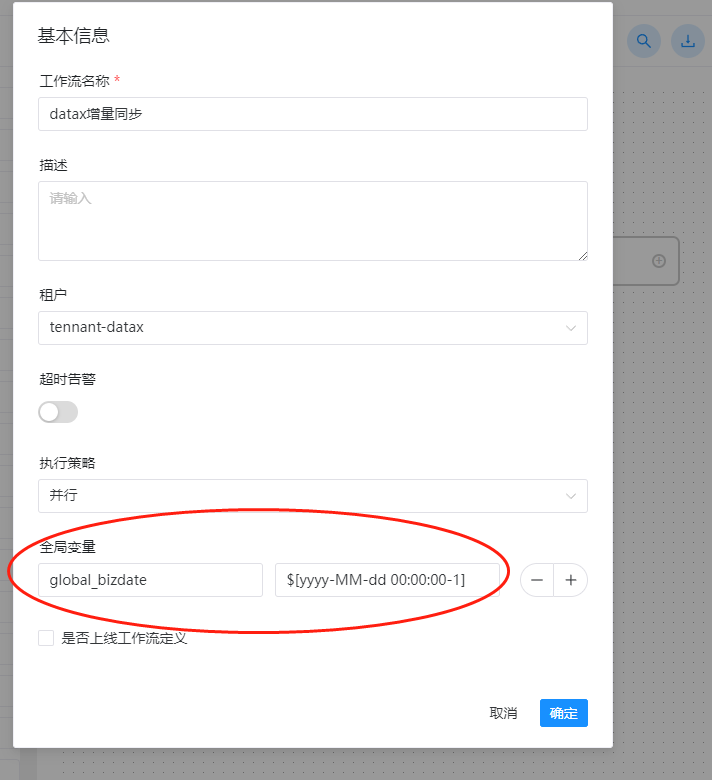
这里的值取时间的话,我们格式是这样的:$[yyyy-MM-dd 00:00:00] 这种格式是DolphinScheduler自带的时间生成,如我们配置成这个,代表的就是今日的0点0分0秒,由于是增量同步,因此这里我们有一个减一的操作,代表的就是今天的时间减去1天,也就是昨天的0点0分0秒,这里同步的话,具体减多少我们根据实际情况进行操作即可。
配置完毕之后,我们点击确定。然后回到工作流定义里面,把工作流进行上线:
上线之后这个工作流就可以运行了,点击运行
运行之后,我们再任务实例里面就能看到对应的结果了。
可以看到运行成功了,然后我们看下数据源2的user表的数据
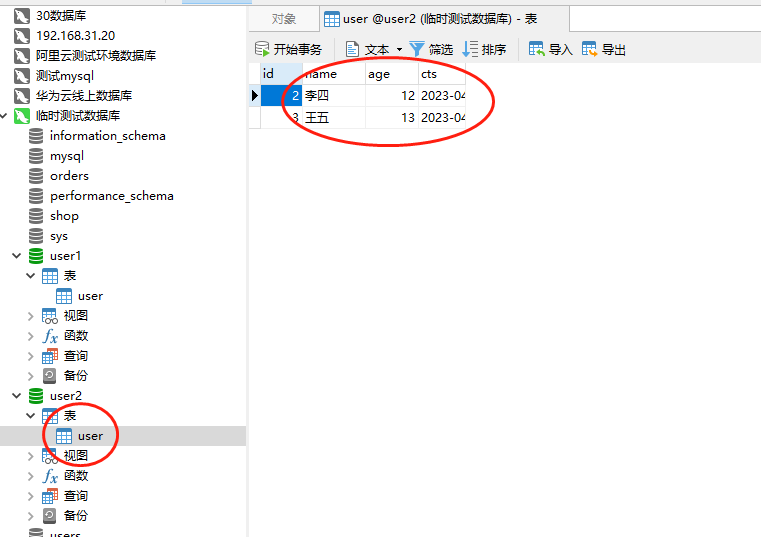
可以看到增量的数据已经进来了。
以上就是使用DolphinScheduler配置datax进行数据增量操作的步骤。








还没有评论,来说两句吧...