
上一篇文章《分布式调度系统Apache DolphinScheduler系列(二)DolphinScheduler伪集群安装》我们搭建了一个Apache DolphinScheduler伪集群,这里我们来实战一下,配置一个datax的全量同步的job任务。
datax是我们经常使用到的数据迁移工具,所以这里我们第一个使用这个来操作。下面直接开始。
一、准备一个datax
首先我们需要准备一个datax,这里可以直接在官网下载即可,下载地址:datax下载。下载之后我们把datax上传到服务器上,并且解压
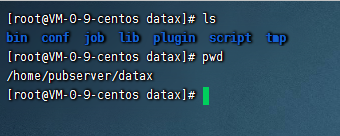
二、修改DolphinScheduler配置,添加python和datax的环境变量
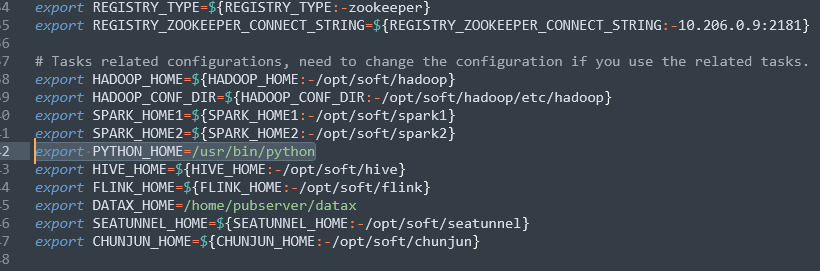
我们进入到${dolphinscheduler_home}/bin/env目录下,修改dolphinscheduler_env.sh,修改如下的信息:
export DATAX_HOME=/home/pubserver/datax export PYTHON_HOME=/usr/bin/python
修改后如图:
修改完成之后,我们进入到${dolphinscheduler_home}/bin目录下,使用:
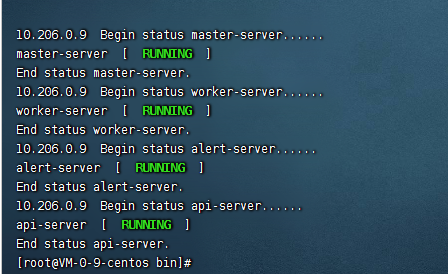
./stop-all.sh
把整个dolphinscheduler集群给停掉。然后再执行下
./install.sh
此时就会重新分发新的配置文件,并且启动整个集群。
备注:
1、这里的话我们进入的这个${dolphinscheduler_home}是之前的解压缩的文件夹目录,不是/tmp的安装目录,因此不要搞错了。
2、只要修改了${dolphinscheduler_home}/bin/env/dolphinscheduler_env.sh都建议重新分发下整个集群,因为在生产环境这里的work非常多,挨个改动的话可能会很麻烦,而且容易出错,因此我们这里使用./install.sh重新进行分发一下即可。重新分发后数据不会丢失,因为我们把数据是存储在mysql上的。
3、这里的python_home不是配置的文件夹,因此centos自带有python,这里我们直接配置到centos自带的python执行文件即可。
4、datax_home我们配置到文件夹下的,他会自动寻找bin/datax.py文件。
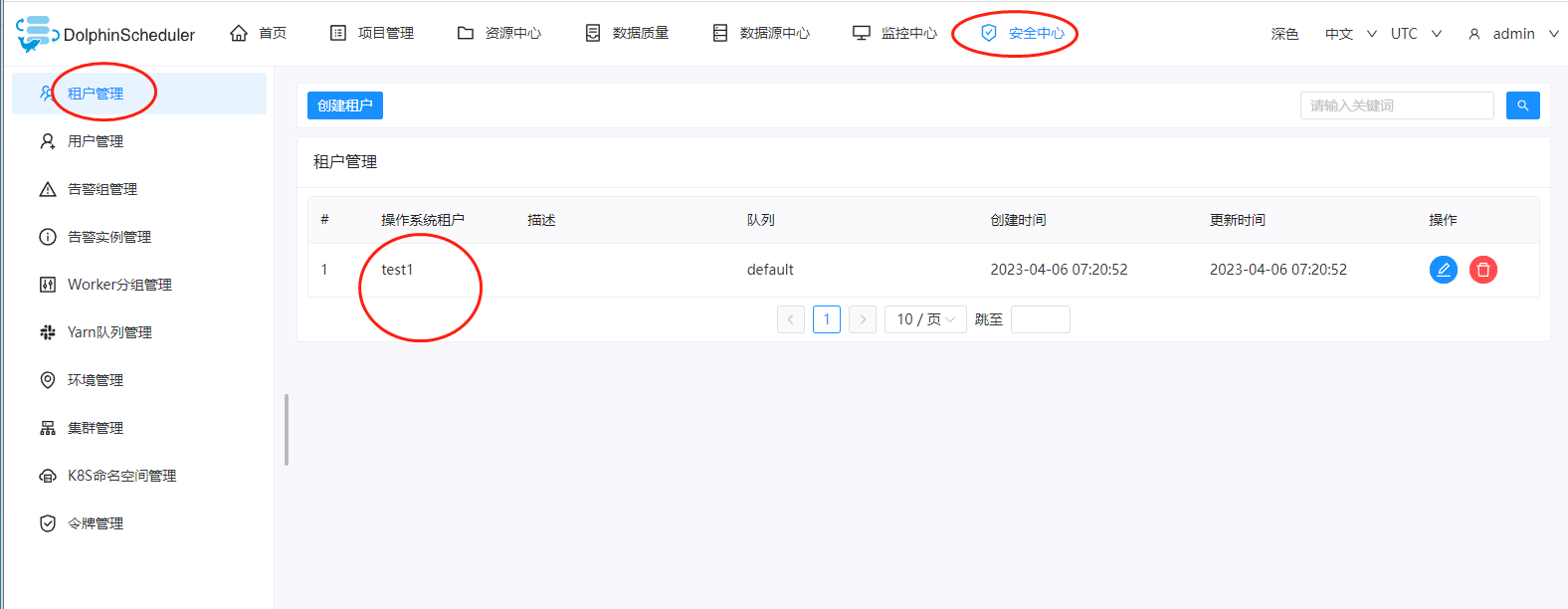
三、添加一个租户
在dolphinscheduler中,我们执行的任何job任务都需要一个租户,因此这里我们创建一个租户即可,进入到dolphinscheduler的dashboard页面,点击:安全中心->租户管理->创建租户,这里我们创建一个名为test1的租户。
四、添加环境变量
这里datax的运行虽然是使用python驱动运行的,但是里面真实的还是使用java,因此我们这里创建一个java的环境变量。点击:安全中心->环境管理->创建环境。这里的话主要是这个export语句:
export JAVA_HOME=/usr/local/jdk1.8.0_271 export PATH=$PATH:$JAVA_HOME/bin
如图:
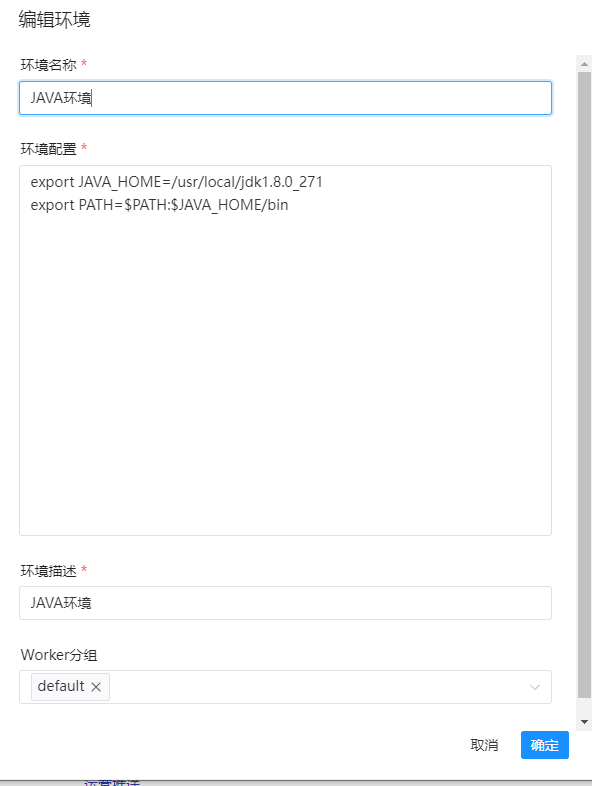
备注:1、这里每一个环境一定要选择一个worker分组,因为字啊job里面首先需要选择worker分组,然后再在worker分组里面找包含的环境变量。
创建完成后,可以看到java环境了。
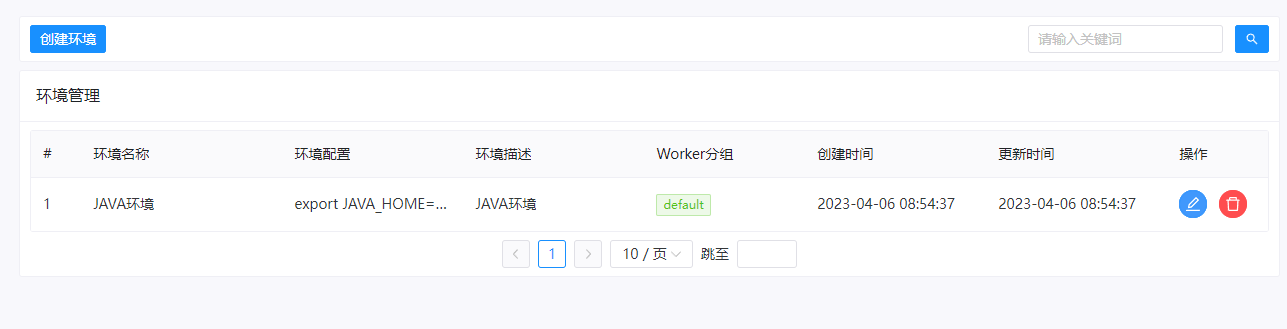
五、找一个mysql,创建两个数据库
这里我们主要是做演示数据,因此分别创建一个名为user1的数据库和名为user2的数据库,同时在user1数据库里面添加一张user表,再在user表里面插入3条数据,并且在user2数据库中也添加一张user表,但是不插入数据。完整的执行如下:
数据源1:
CREATE DATABASE `user1` /*!40100 DEFAULT CHARACTER SET utf8 */ use user1 CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL COMMENT '姓名', `age` tinyint(3) DEFAULT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `user1`.`user`(`id`, `name`, `age`) VALUES (1, '张三', 11); INSERT INTO `user1`.`user`(`id`, `name`, `age`) VALUES (2, '李四', 12); INSERT INTO `user1`.`user`(`id`, `name`, `age`) VALUES (3, '王五', 13);
数据源2:
CREATE DATABASE `user2` /*!40100 DEFAULT CHARACTER SET utf8 */ use user2 CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(20) DEFAULT NULL COMMENT '姓名', `age` tinyint(3) DEFAULT NULL COMMENT '年龄', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
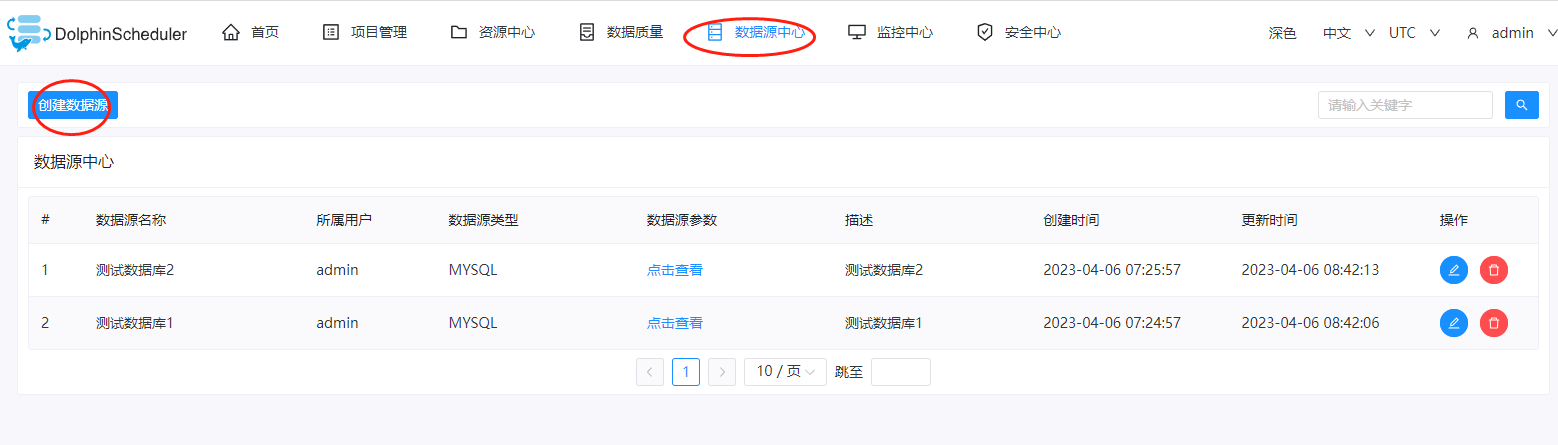
六、添加数据源
这里再次进入到DolphinScheduler的dashboard上,这里我们分别创建2个数据源,依次点击:数据源中心->创建数据源
创建的数据源填写信息示例如下:
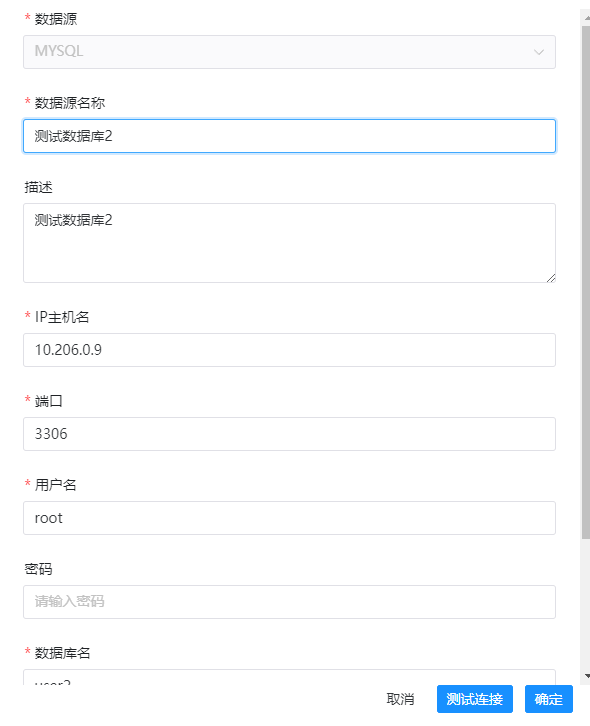
最后的jdbc参数的话,我们可以选择这个:
{"useUnicode":"true","useSSL ":"false","characterEncoding":"UTF-8"}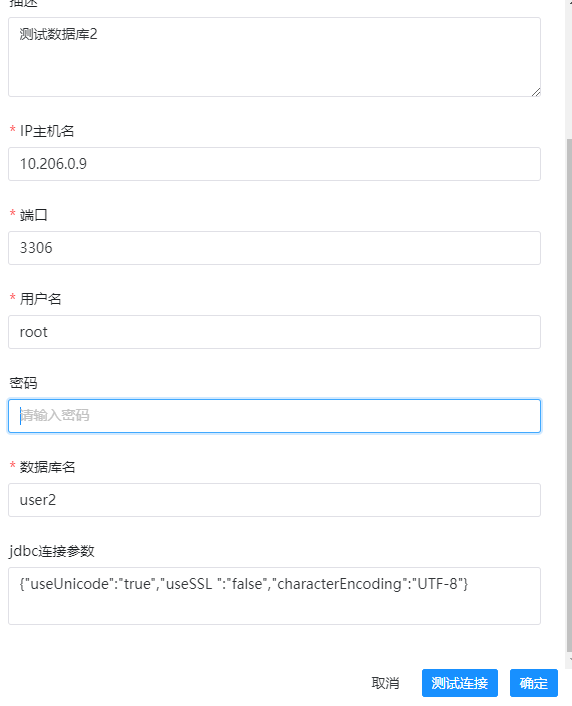
重复操作两次,即可以建立两个数据源。
七、创建一个项目
在DolphinScheduler中,所有的任务都是以项目为主的,依次点击:项目管理->创建项目。这里我们创建一个名为测试datax全量同步的名称的项目
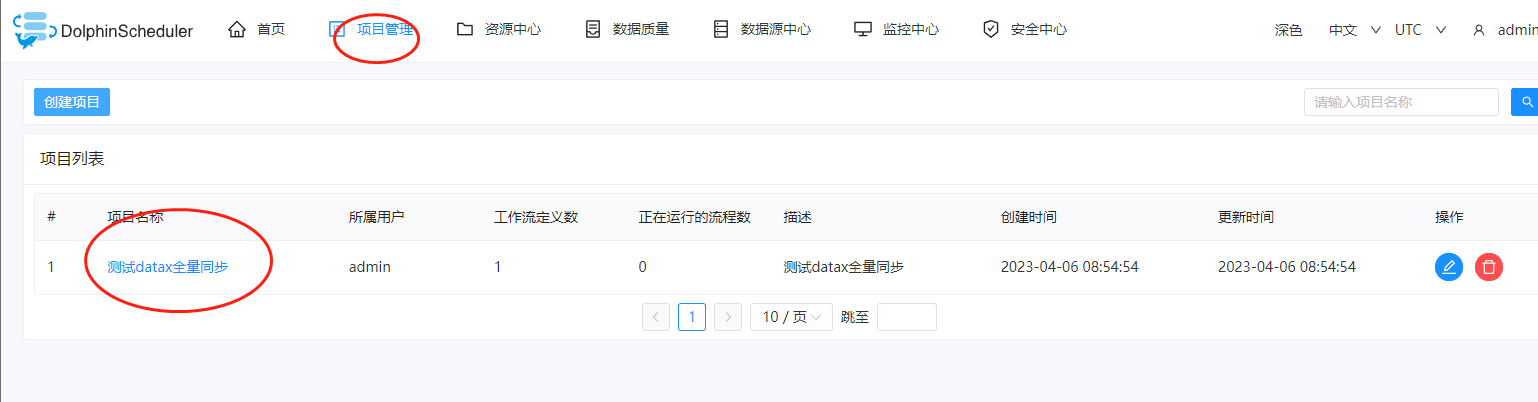
创建完成之后,我们点击项目名称,进入到里面来
点击左侧菜单的工作流定义,然后再这里创建一个工作流
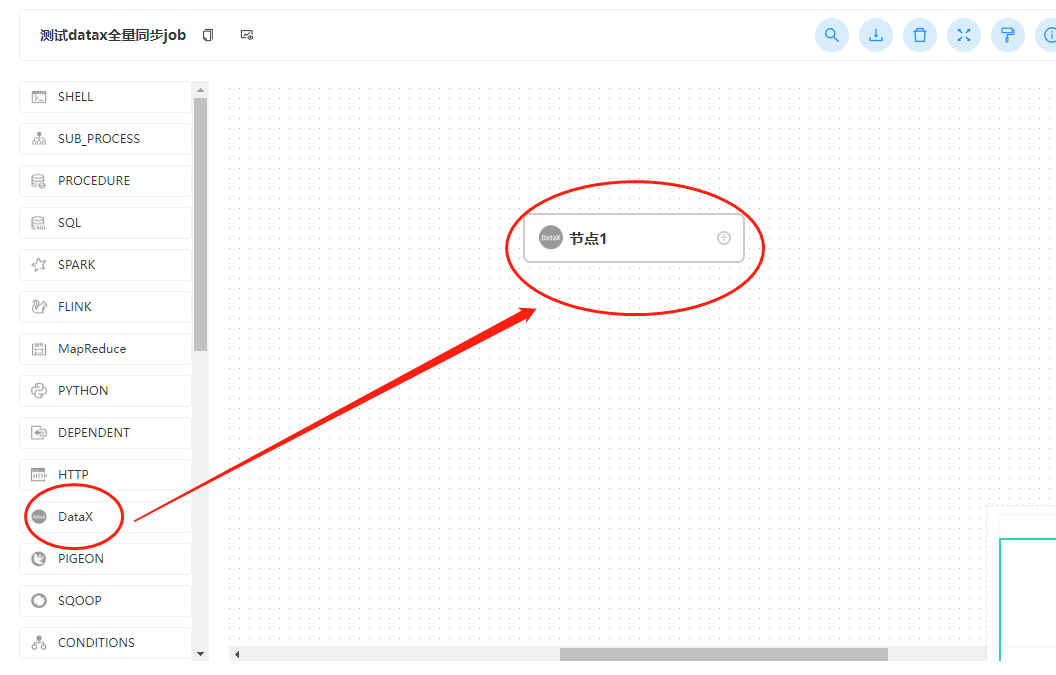
此时我们从左侧拖动一个datax到右边的画布中
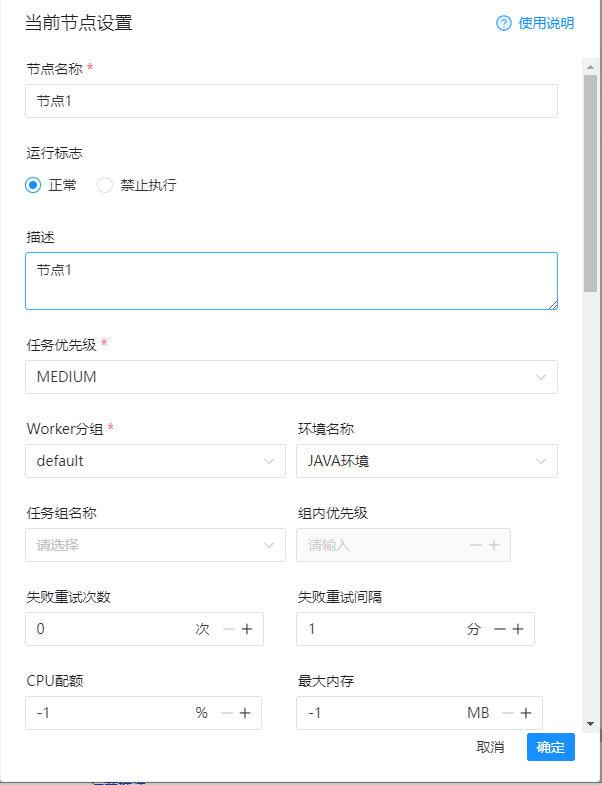
然后开始配置信息,这里的信息主要是编写节点的信息,所以示例如下:
节点名称:随便写 运行标志:正常 任务优先级:看情况调整 worker分组:选择default 环境名称:这里选择刚才配置的java环境 数据源类型:选择mysql 数据源实例:选择第一个数据库 sql语句:这里就是需要使用datax同步数据的查询sql 数据源类型:选择mysql 数据源实例:选择第二个数据库 其他的保持不变
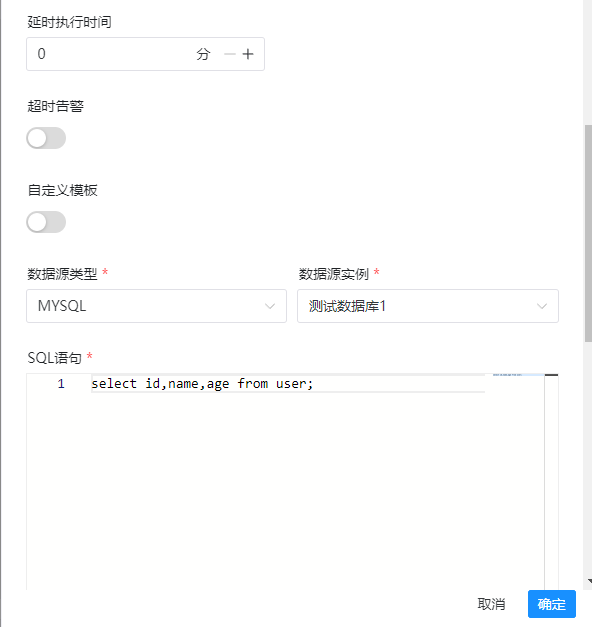
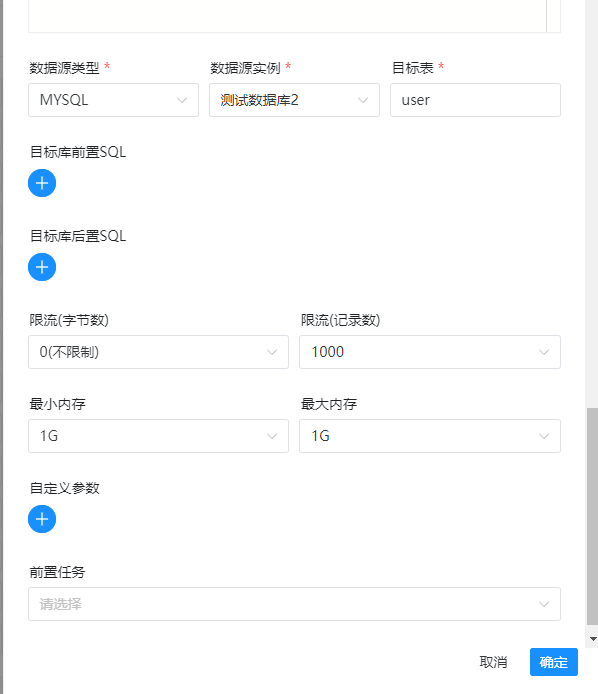
所有的信息填写完毕之后,点击确定即可,然后我们选择右上角点击保存:
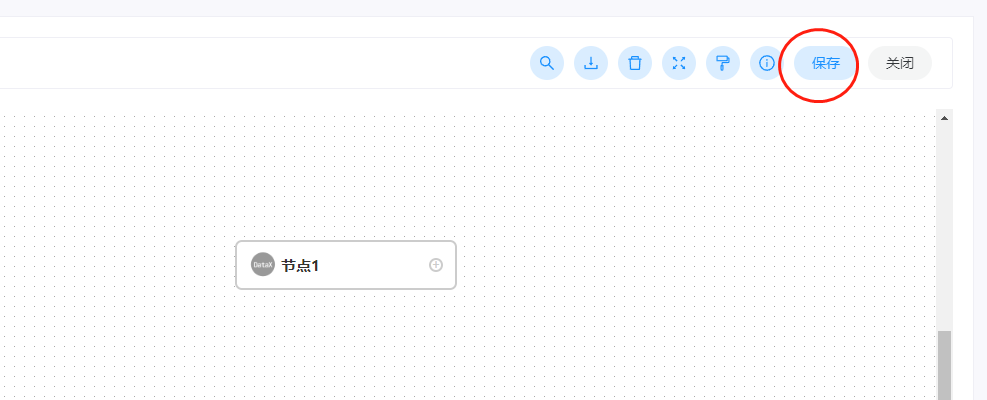
此时需要再填写依次信息,示例信息如下:
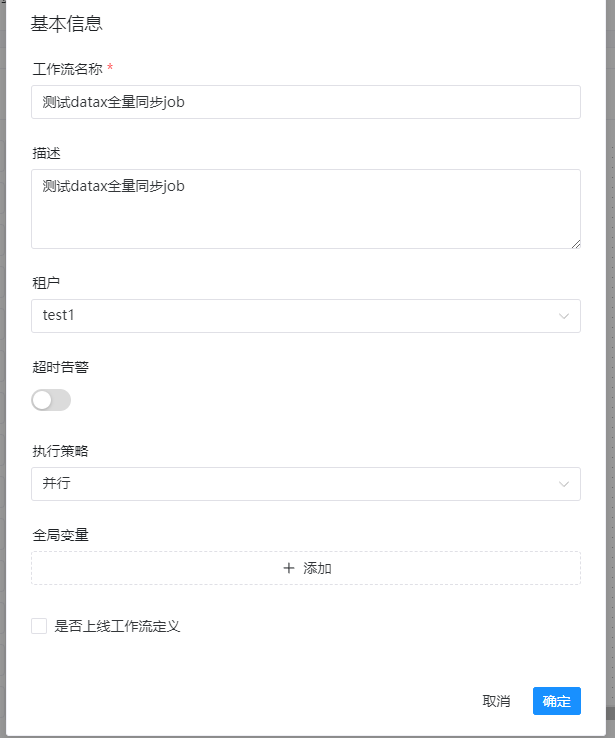
备注:
1、记得在这里选择租户,如果没有选择租户,那么无法保存的。
八、项目上线
经过前面的操作我们已经完成了项目的编辑,此时我们回到工作流定义里面,可以看到刚才配置的job
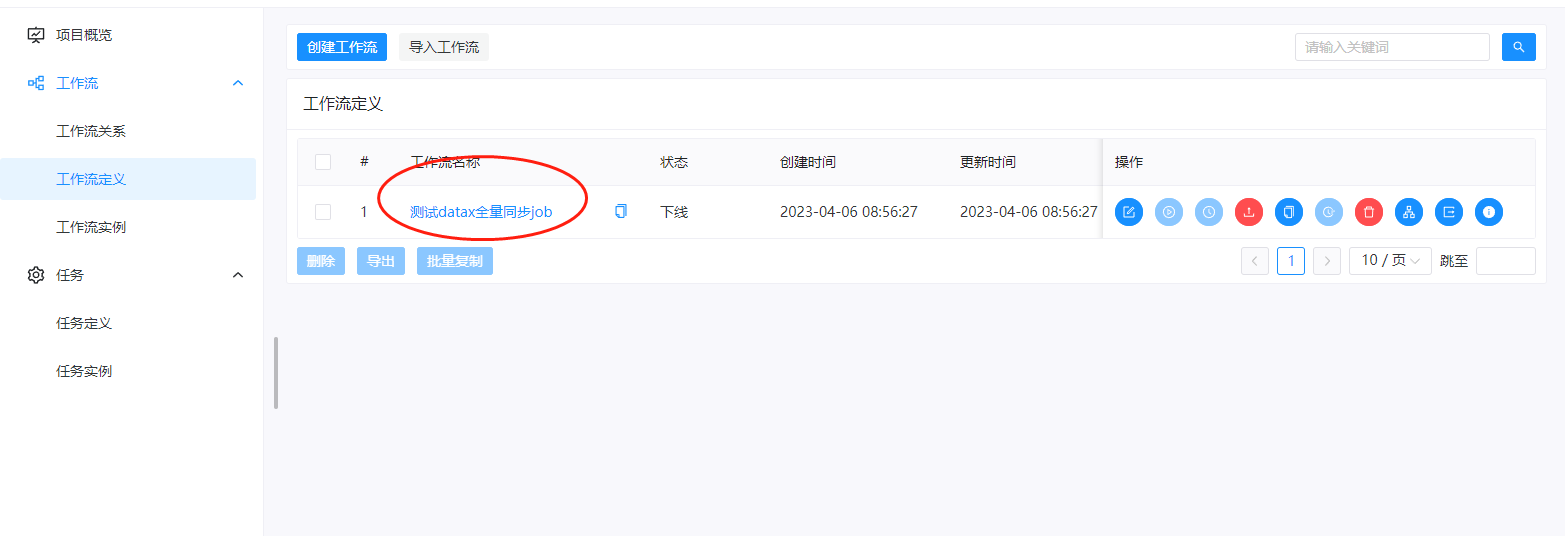
在右侧,我们选择上线按钮,点击上线
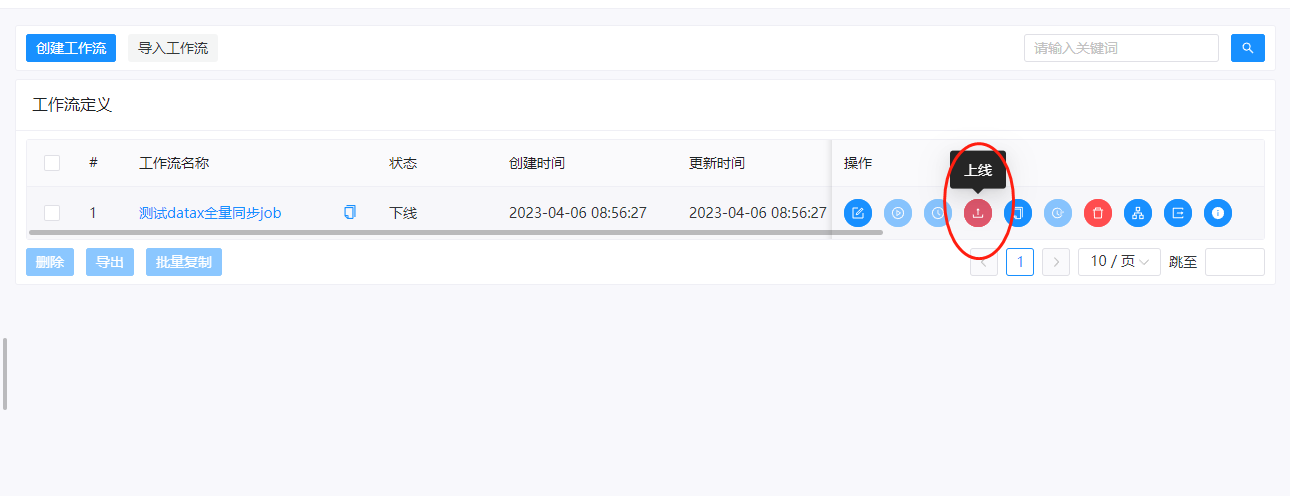
上线之后,右侧的运行按钮就不再是灰色的,而是可以点击的。
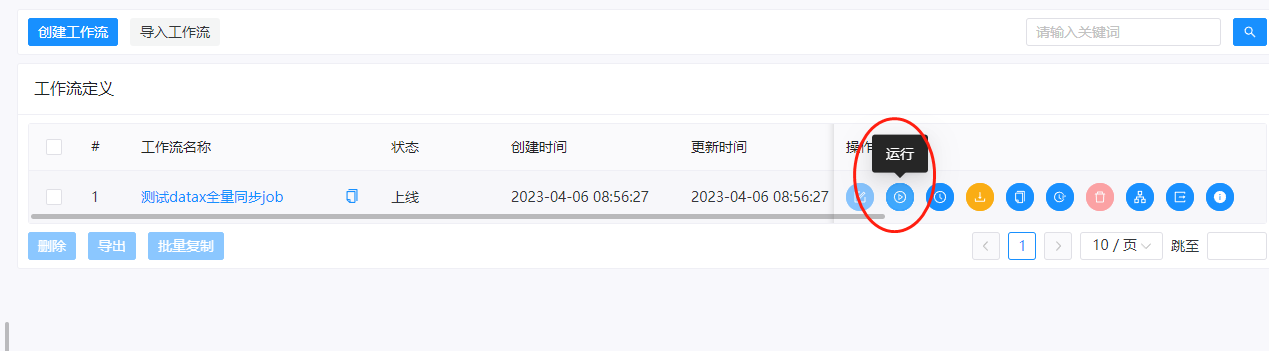
我们点击下这里的运行按钮,任务就会开始运行了。此时我们可以选择左侧的任务实例,查看任务的执行状态
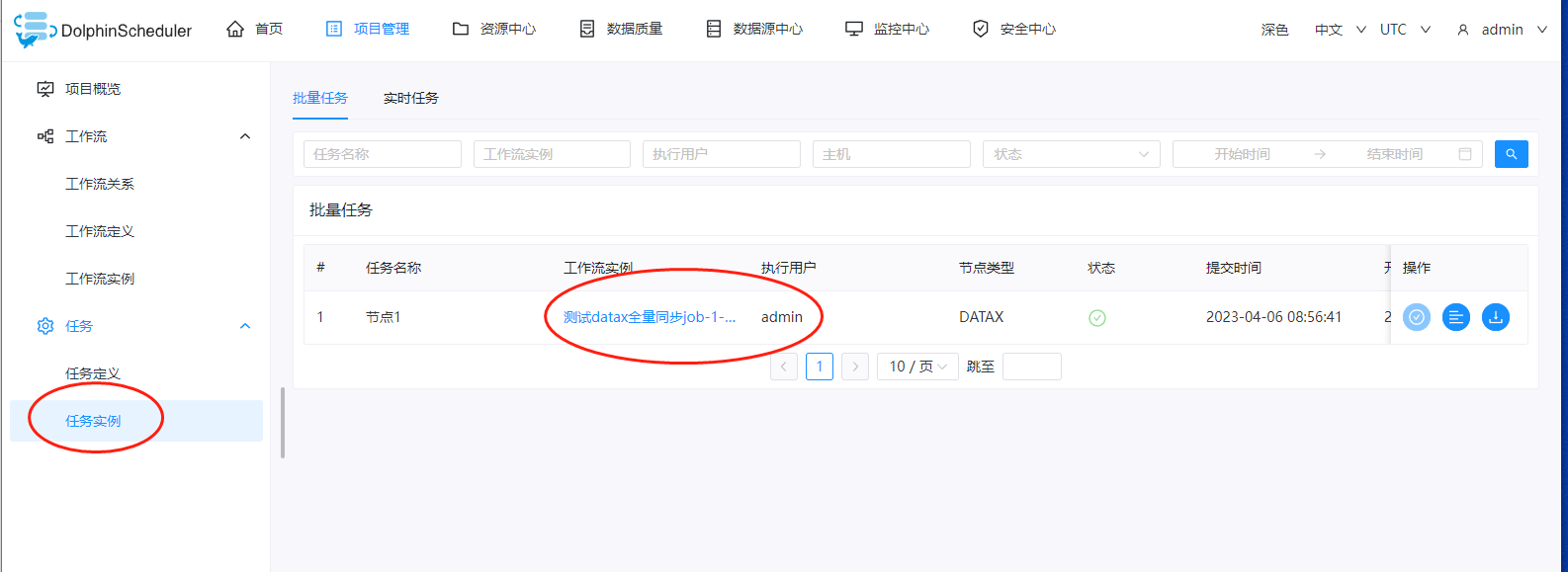
这里如果任务执行成功的话,这里的状态是一个勾,如果任务执行失败的话,这里的状态是一个叉。同时我们可以点击右侧,查看任务执行的日志:
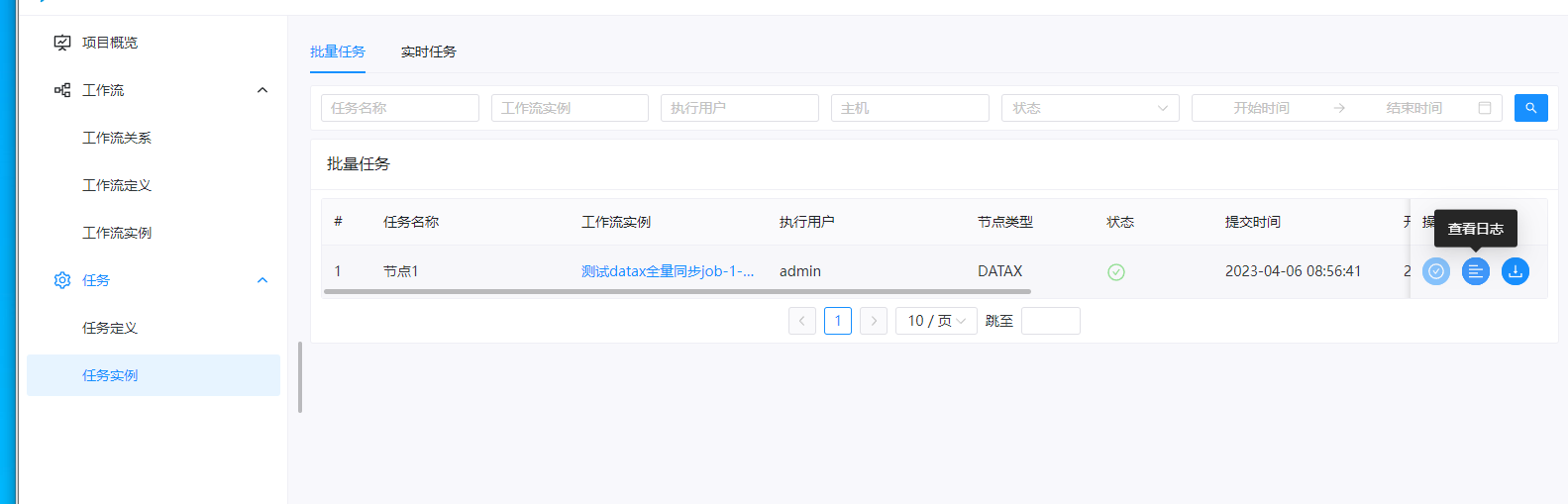
这里我们运行的话,可以看到状态是成功的。数据库的数据也被同步进来了。
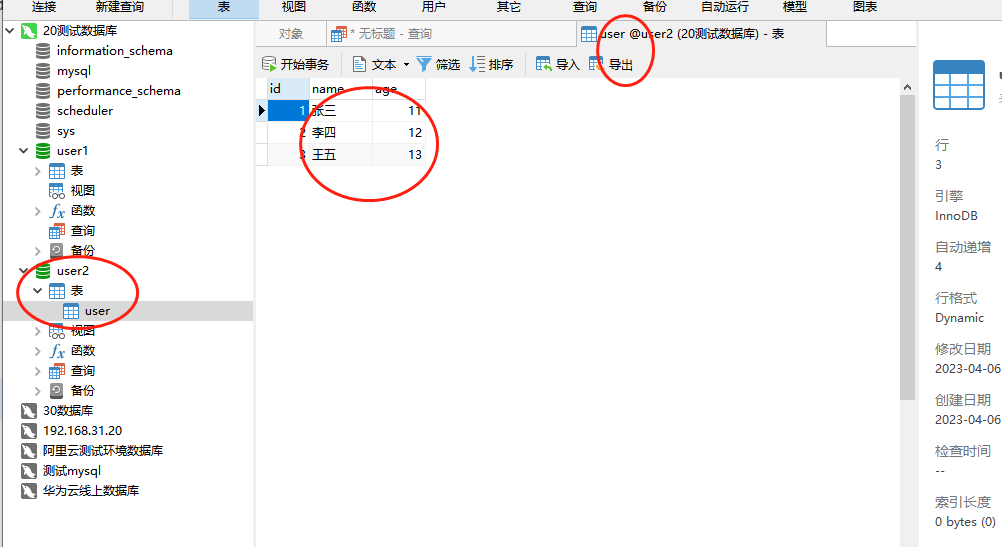
以上就是使用DolphinScheduler来进行配置datax的全量同步的任务示例。
备注:
1、在原本使用datax的时候,我们需要编写繁琐的xxx.json文件,详情见:《数据迁移工具-datax介绍》。使用这个进行配置的时候,我们不再需要编写xxx.json文件,只需要配置对应的sql即可。








还没有评论,来说两句吧...