
上一篇文章《分布式调度系统Apache DolphinScheduler系列(八)使用DolphinScheduler执行hive cli》我们介绍了在DolphinScheduler上配置hive cli,这篇文章我们介绍下使用DolphinScheduler配置flink的job,让其可以直接执行flink相关的任务。下面直接开始。
一、准备一个flink的环境
flink的安装在前面我们已经介绍过了,可以参考这篇文章《Flink流处理系列(二)standalone集群安装》。有一个特别的说明,我们需要在${flink_home}/conf/flink-conf.yaml文件中配置如下项:
classloader.check-leaked-classloader: false
二、添加环境变量
这里还是一样,涉及到大数据相关的,都需要配置一个环境变量,因此这里在DolphinScheduler的环境变量里面我们创建一个环境变量
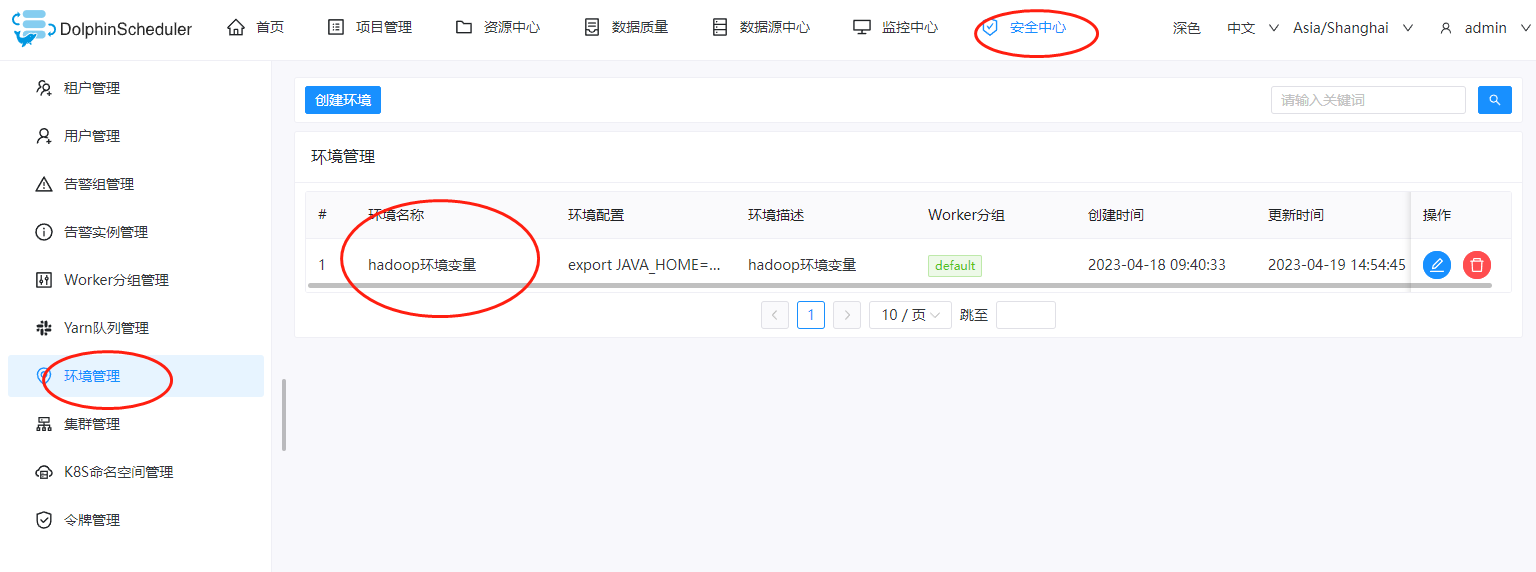
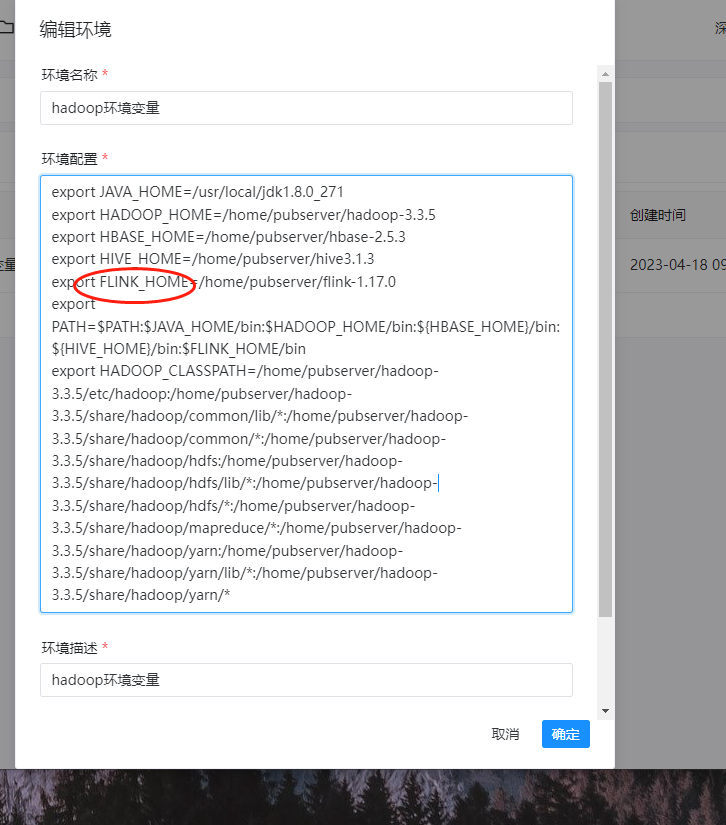
这里面环境变量的值,示例如下:
export JAVA_HOME=/usr/local/jdk1.8.0_271
export HADOOP_HOME=/home/pubserver/hadoop-3.3.5
export HBASE_HOME=/home/pubserver/hbase-2.5.3
export HIVE_HOME=/home/pubserver/hive3.1.3
export FLINK_HOME=/home/pubserver/flink-1.17.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin:$FLINK_HOME/bin
export HADOOP_CLASSPATH=/home/pubserver/hadoop-3.3.5/etc/hadoop:/home/pubserver/hadoop-3.3.5/share/hadoop/common/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/common/*:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs/*:/home/pubserver/hadoop-3.3.5/share/hadoop/mapreduce/*:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn/*配置示例图如下:
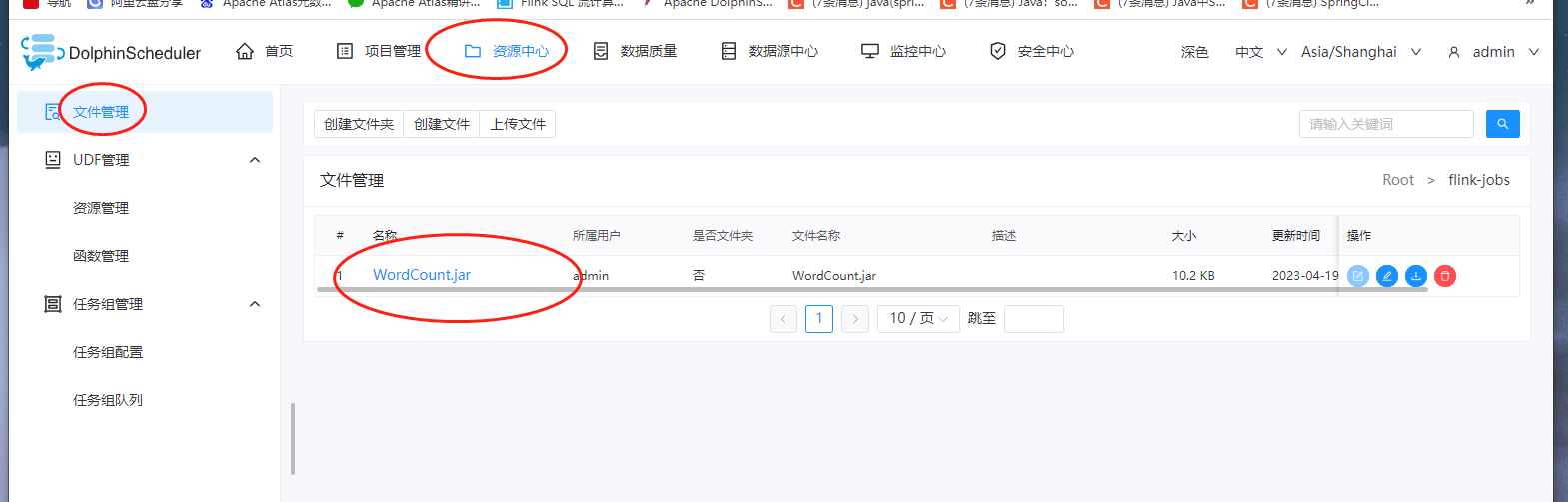
三、上传wordcount程序
这里的话,我们没有单独去写一个flink的程序,因此这里我们直接使用现成的wordcount程序即可,在flink的安装包里面提供有wordcount的example,位置在:${flink_home}/examples/batch/WordCount.jar。我们把这个wordcount的jar包上传到DolphinScheduler的资源中心上,如下:
四、创建一个项目
这里我们创建一个名称为flink的测试项目

五、创建一个工作流
这里我们创建一个flink组件的工作流,如下图:
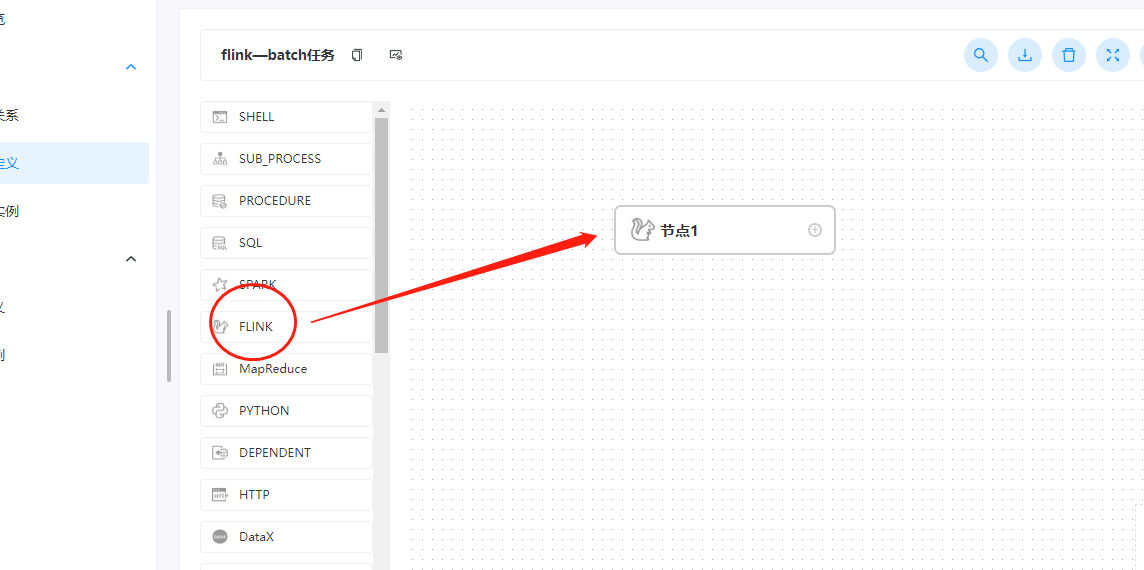
配置项如下:
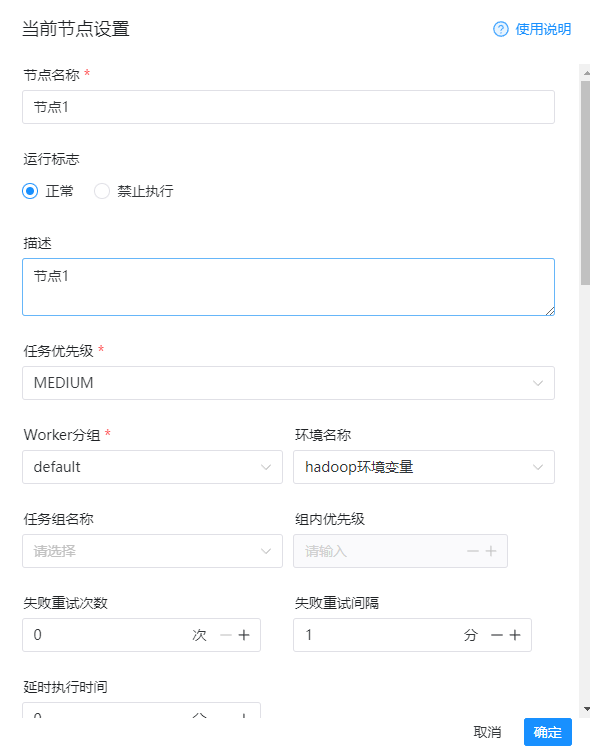
1)节点名称
节点1
2)运行标志
正常
3)环境名称(选择刚才配置的环境变量)
hadoop环境变量
4)程序类型
java
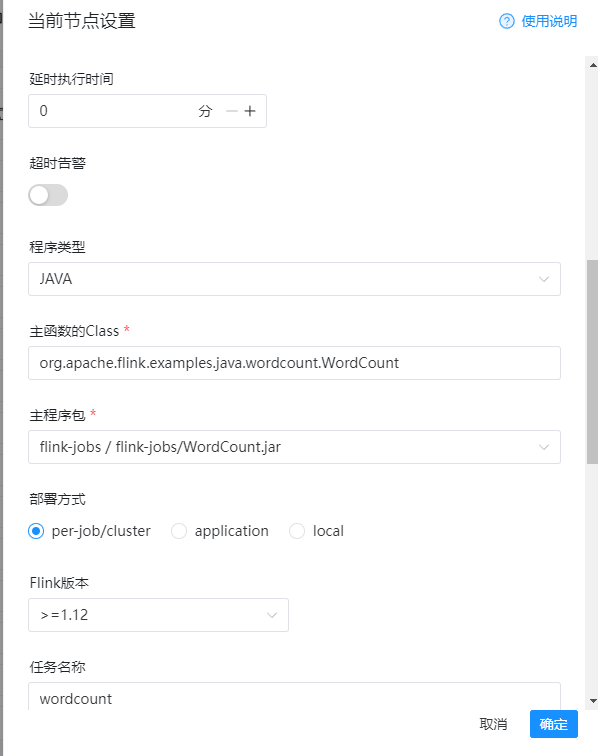
5)主函数的Class
org.apache.flink.examples.java.wordcount.WordCount
6)主程序包(选择刚才上传的jar包)
wordcount.jar
7)部署方式
per-job/cluster
8)flink版本
大于等于1.12
我们这里的flink版本是1.17的,所以要选择大于等于1.12版本
9)任务名称
wordcount
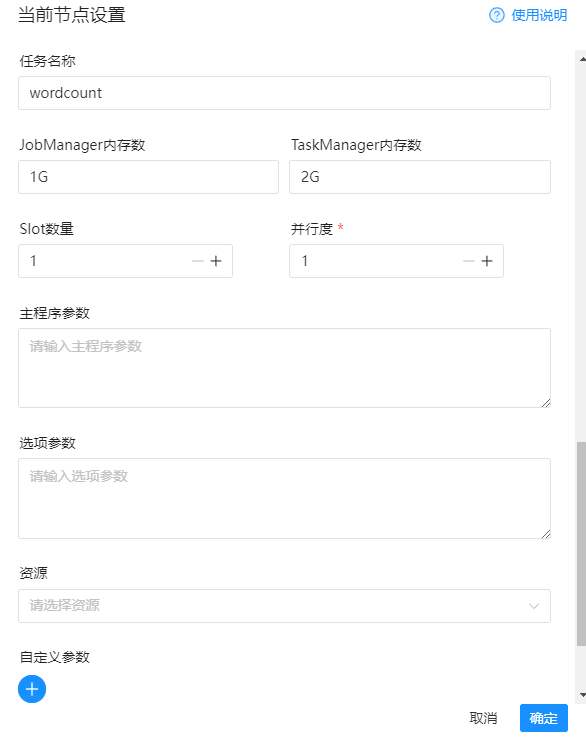
完整的配置示例如下:
配置完毕之后,我们把工作流保存起来。
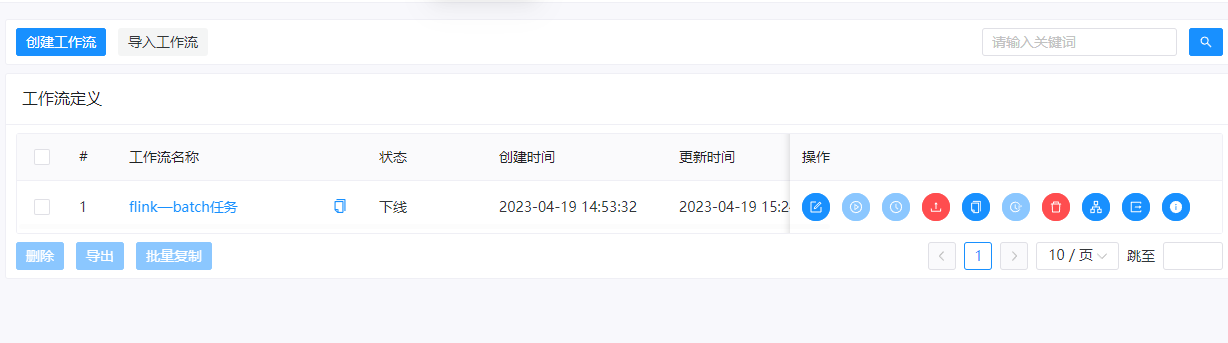
六、运行测试
最后我们把工作流上线,然后运行起来
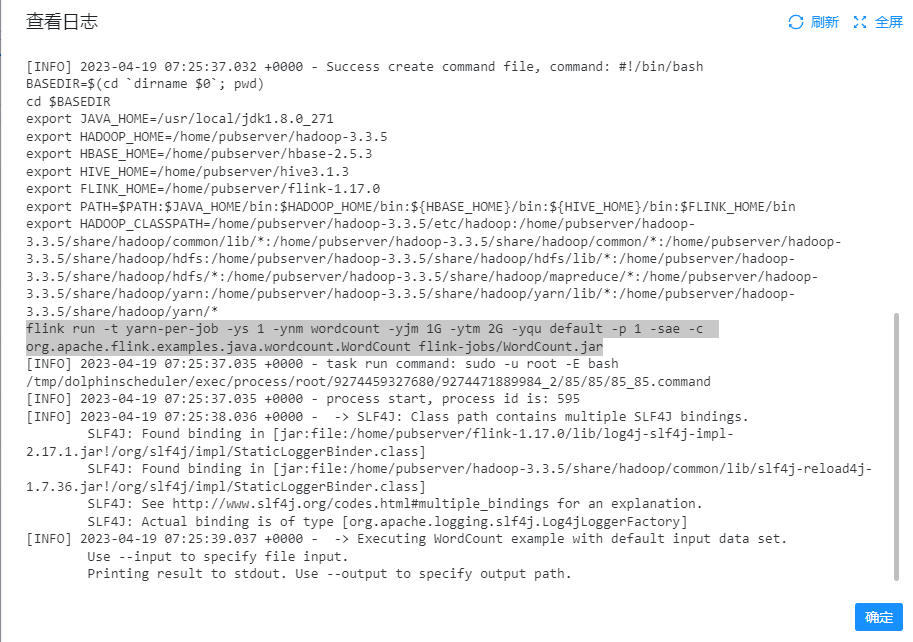
可以看到这里的提交flink job的命令是:
flink run -t yarn-per-job -ys 1 -ynm wordcount -yjm 1G -ytm 2G -yqu default -p 1 -sae -c org.apache.flink.examples.java.wordcount.WordCount flink-jobs/WordCount.jar
也就是他是向yarn上提交的,所以这个任务可以在yarn上看到,此时我们访问下yarn
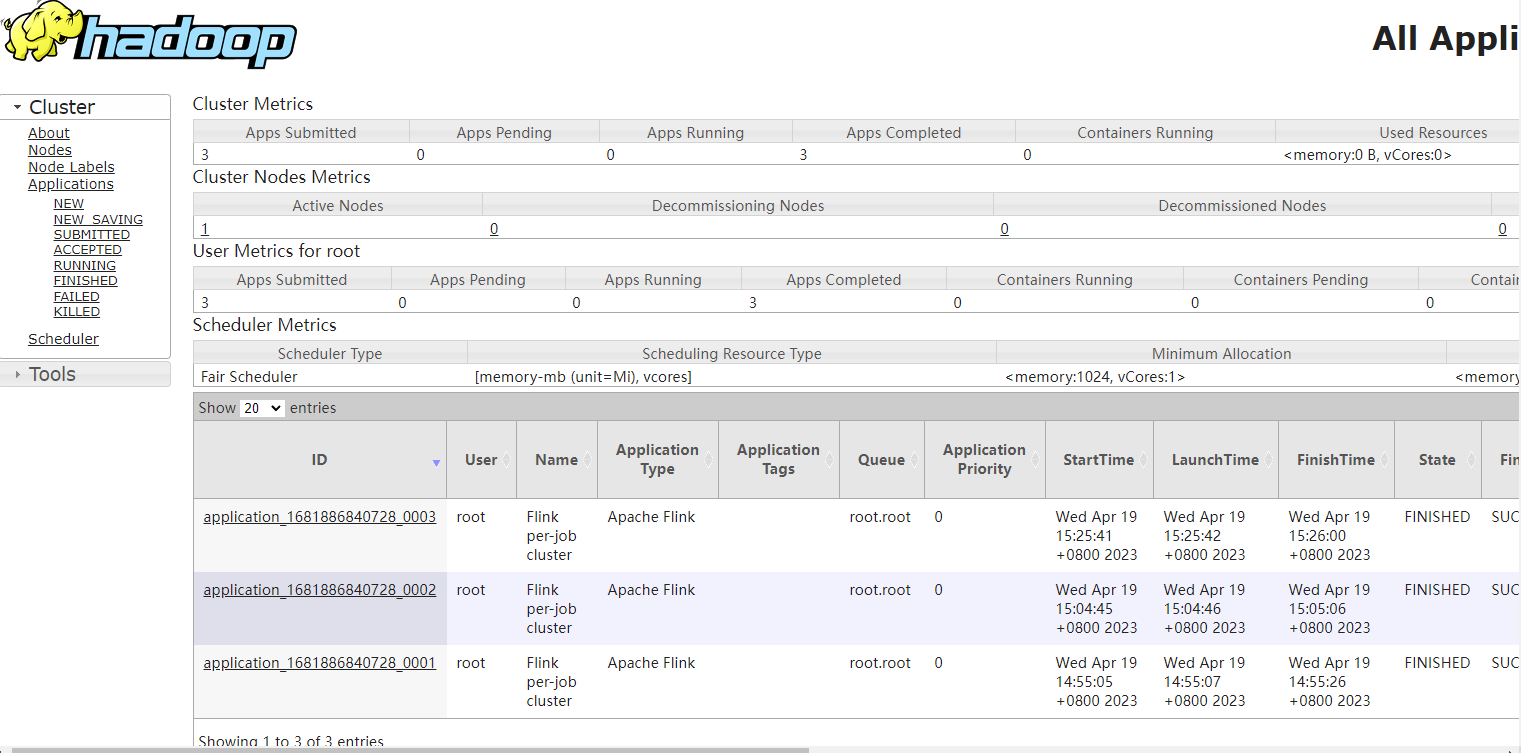
然后也可以看到运行成功了,我们看看结果:

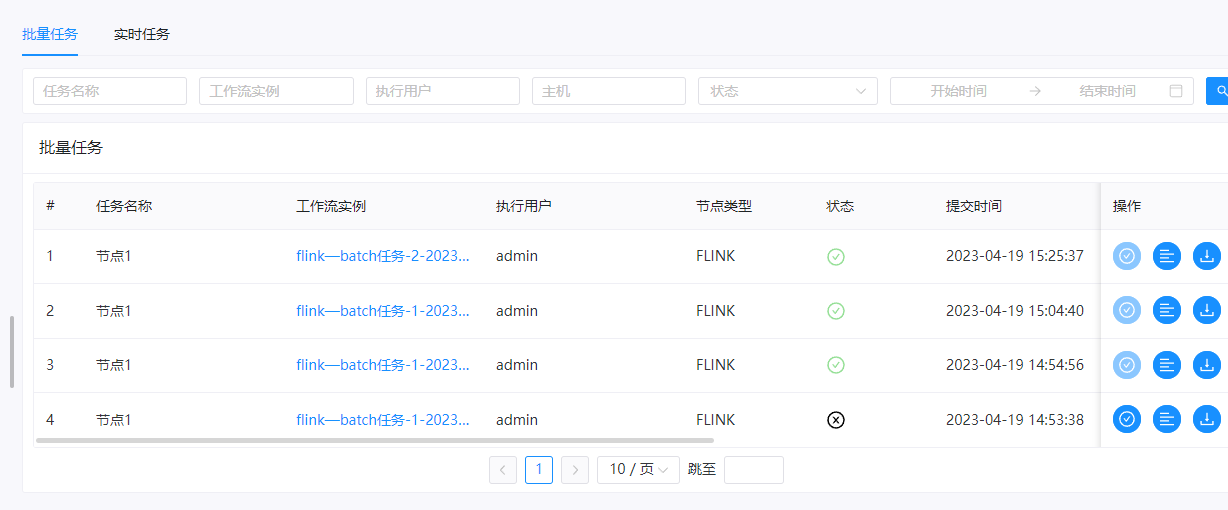
以上就是使用DolphinScheduler部署flink job任务的详细教程。
备注:
1、在DolphinScheduler上配置flink_stream的流程和上面是一样的。








还没有评论,来说两句吧...