
在DolphinScheduler的flink组件中,除了执行常规的batch和stream项目,这里还可以直接配置flink sql。如果配置flink sql的话,这里执行的是sql-client.sh的执行方式,示例如下:
sql-client.sh -i 105_105_init.sql -f 105_105_node.sql
这里的-i代表的是执行sql之前的初始化sql语句,
这里的-f代表的是执行sql语句的文件。
下面我们直接演示下在DolphinScheduler上配置flink的job任务。在配置之前,建议熟悉下《分布式调度系统Apache DolphinScheduler系列(九)使用DolphinScheduler执行flink job任务》。本文配置的flink job需要使用到这篇文章里面的配置。
一、添加工作流
这里我们在之前创建的flink测试项目中,创建一个名称为flink-sql测试的工作流
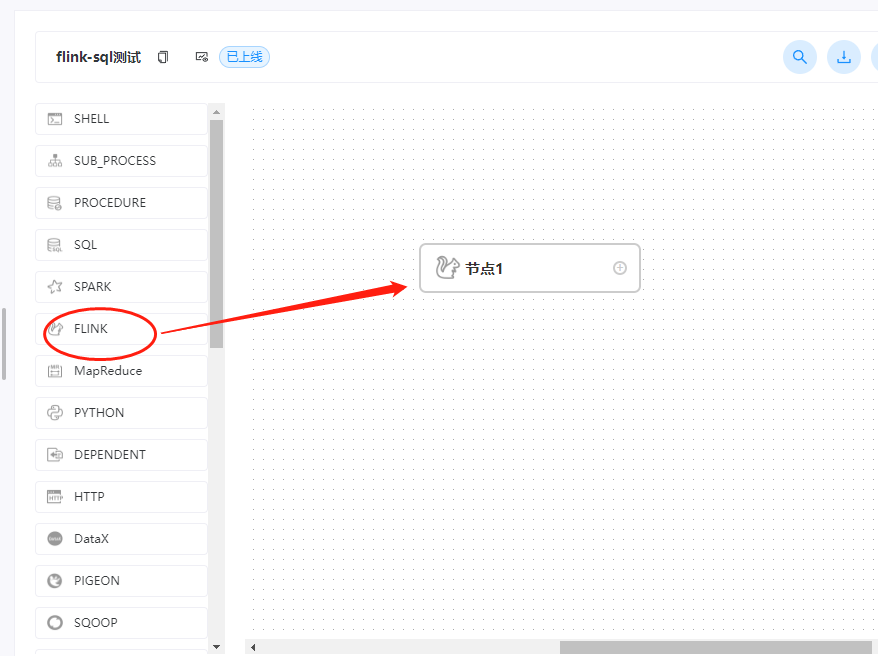
工作流里面的组件还是使用flink
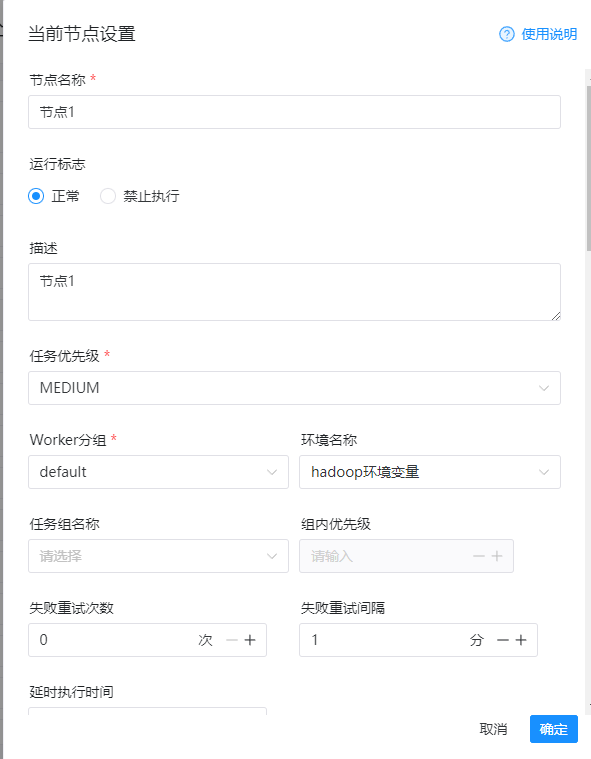
配置项如下:
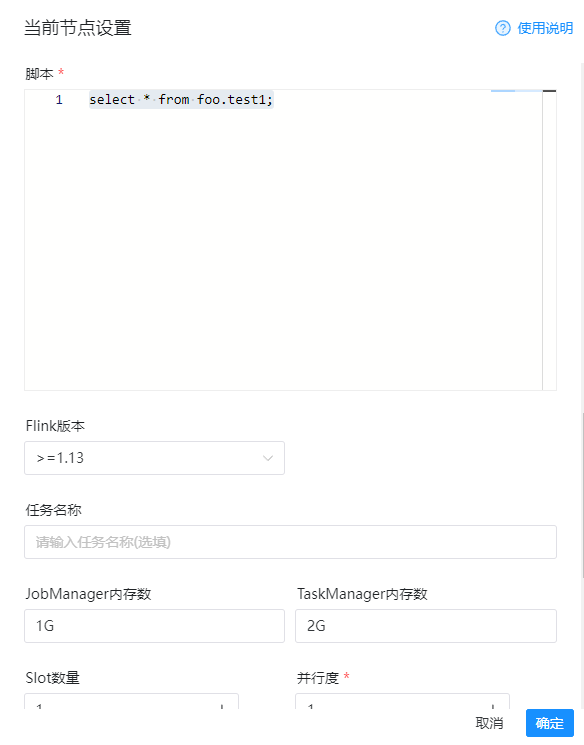
1)节点名称
节点1
2)运行标志
正常
3)环境名称(之前在环境配置里面添加的环境变量)
hadoop环境变量
4)程序类型(一定要选择sql)
SQL
5)部署方式
per-job/cluster
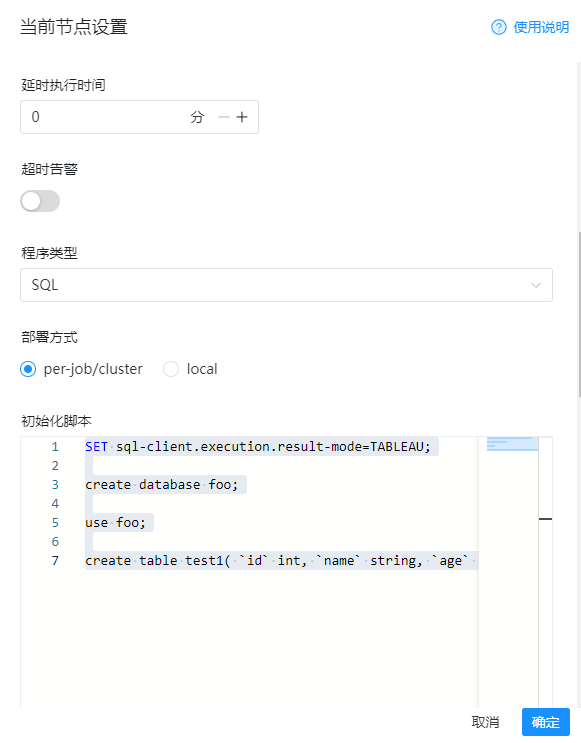
6)初始化脚本(一般是设置环境,创建外部表等等)
SET sql-client.execution.result-mode=TABLEAU; create database foo; use foo; create table test1( `id` int, `name` string, `age` int, `cts` TIMESTAMP )with( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://192.168.31.10:33306/user1?serverTimezone=UTC', 'table-name' = 'user', 'username' = 'root', 'password' = '123456', 'driver' = 'com.mysql.jdbc.Driver' );
7)脚本(正式执行的sql)
select * from foo.test1;
8)flink版本
大于等于1.13
完整的示例配置如下图:
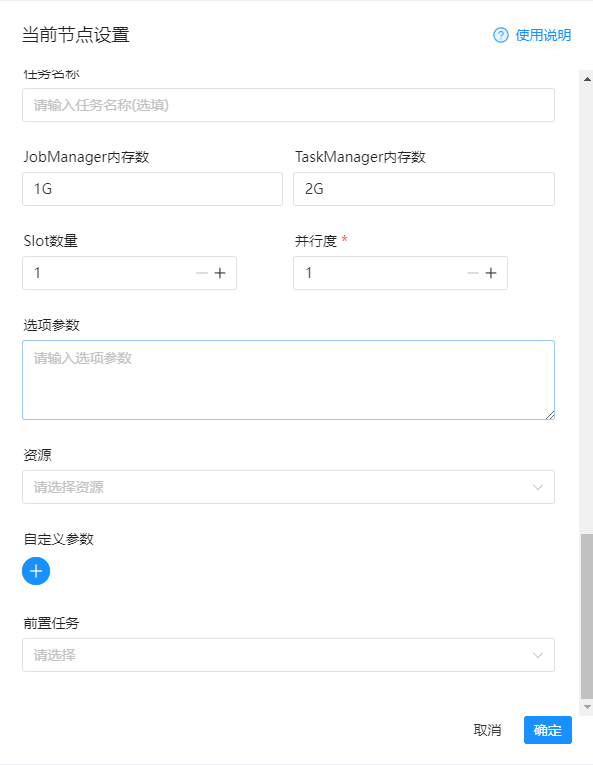
然后我们保存下
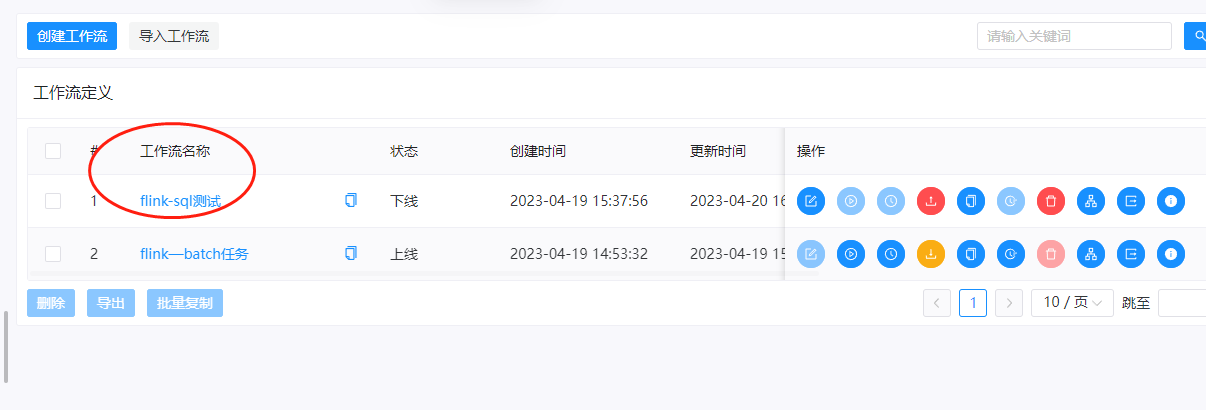
二、运行测试
这里我们把工作流上线,并且运行起来
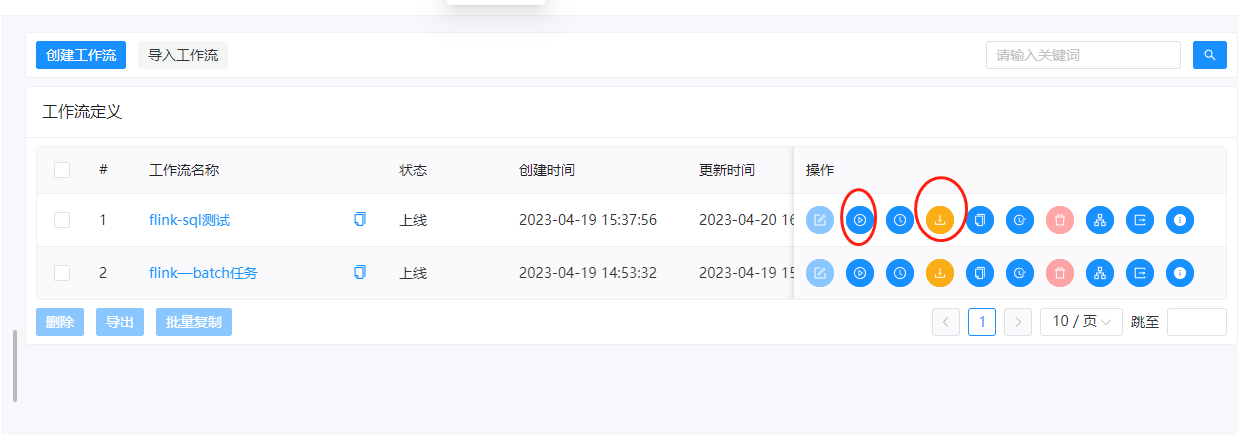
能看到任务被执行成功了。

以上就是使用DolphinScheduler配置flink sql的详细配置。
备注:
1、配置完成之后,我们会运行对应的工作流,在flink sql里面DolphinScheduler这块做的不是太好,就是如果允许日志里面出现了错误信息,他也会认为执行是成功的,因此这里我们如果需要依靠DolphinScheduler执行flink sql的话,一定要人为的去确认下这个flink sql是否正确的执行了。
2、在运行flink sql的时候,在前置初始化sql里面,一定要添加如下的配置:
SET sql-client.execution.result-mode=TABLEAU;
这个配置是标配,如果没有配置的话,要报错。
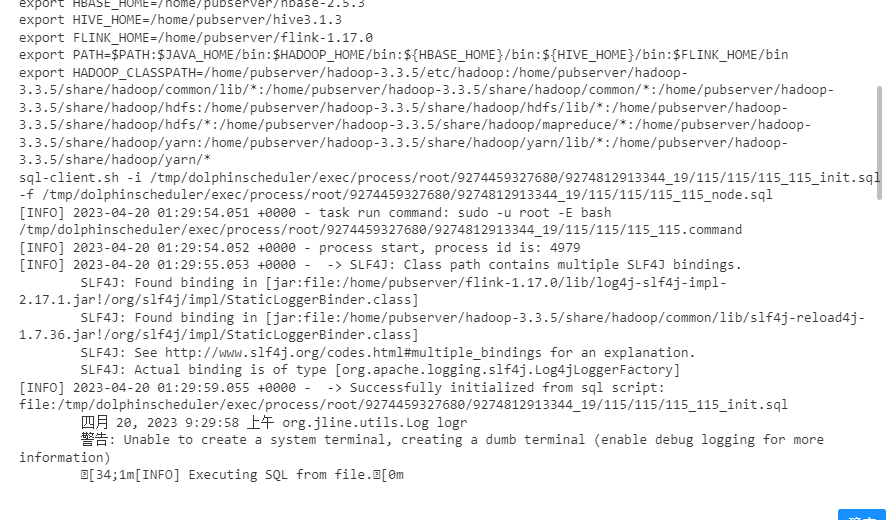
3、这里运行flink的话,他执行的时候使用的是类似如下的命令:
sql-client.sh -i /tmp/dolphinscheduler/exec/process/root/9274459327680/9274812913344_19/115/115/115_115_init.sql -f /tmp/dolphinscheduler/exec/process/root/9274459327680/9274812913344_19/115/115/115_115_node.sql
也就是使用的sql-client提交的sql任务
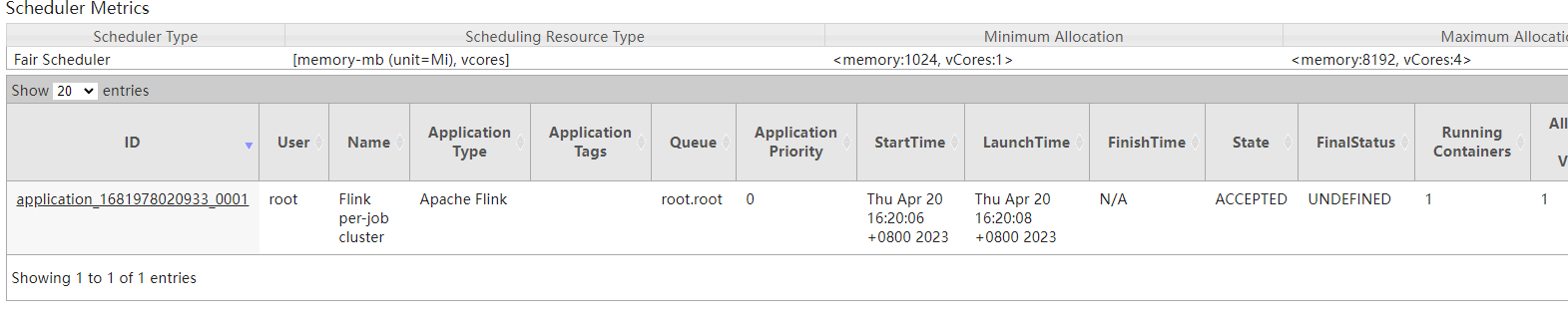
4、这里的flink sql会被提交到yarn上去执行,因此我们在yarn上可以看到对应的sql执行情况
5、hadoop3与flink有一些不兼容的地方,因此这里需要在flink的环境变量里面的conf文件中的flink-conf.yaml文件中,添加如下的配置:
classloader.check-leaked-classloader: false








还没有评论,来说两句吧...