
上一篇文章《分布式调度系统Apache DolphinScheduler系列(七)使用DolphinScheduler执行hive sql》我们介绍了使用sql的方式执行hive相关的sql,但是这个hive sql需要依赖于hiveserver2这个服务,如果生产环境下数据量较多的话,使用这种方式就不太稳定,会导致连接hiveserver2出现超时等异常情况,因此这里我们再介绍一下这个hive cli去执行hive的sql。
在生产环境下,我们建议使用hive cli的方式,因为这种方式比较稳定。
好了下面我们直接来演示下hive cli的方式配置hive sql任务执行。
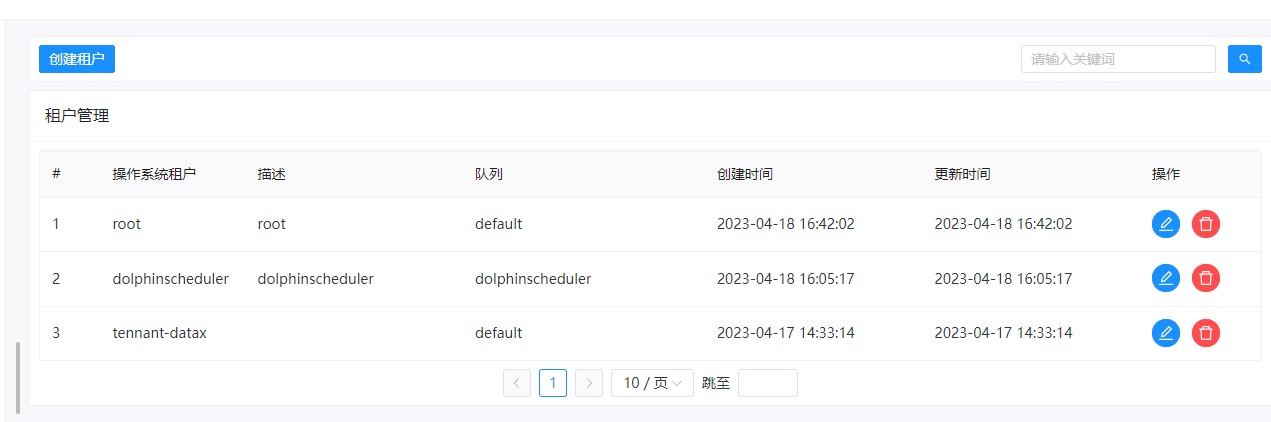
一、创建租户
这里为什么又要创建租户了呢,因为我们在服务器上使用的root的账户安装的hive,在hive执行sql的时候,会创建一些临时的文件夹,因此这里的话,我们需要有执行权限,因此这里我们创建一个名为root的租户。
二、添加大数据的环境变量
这里由于是hive cli,因此需要提前执行下hadoop,和hive的环境变量,我们在这里添加一个环境变量即可
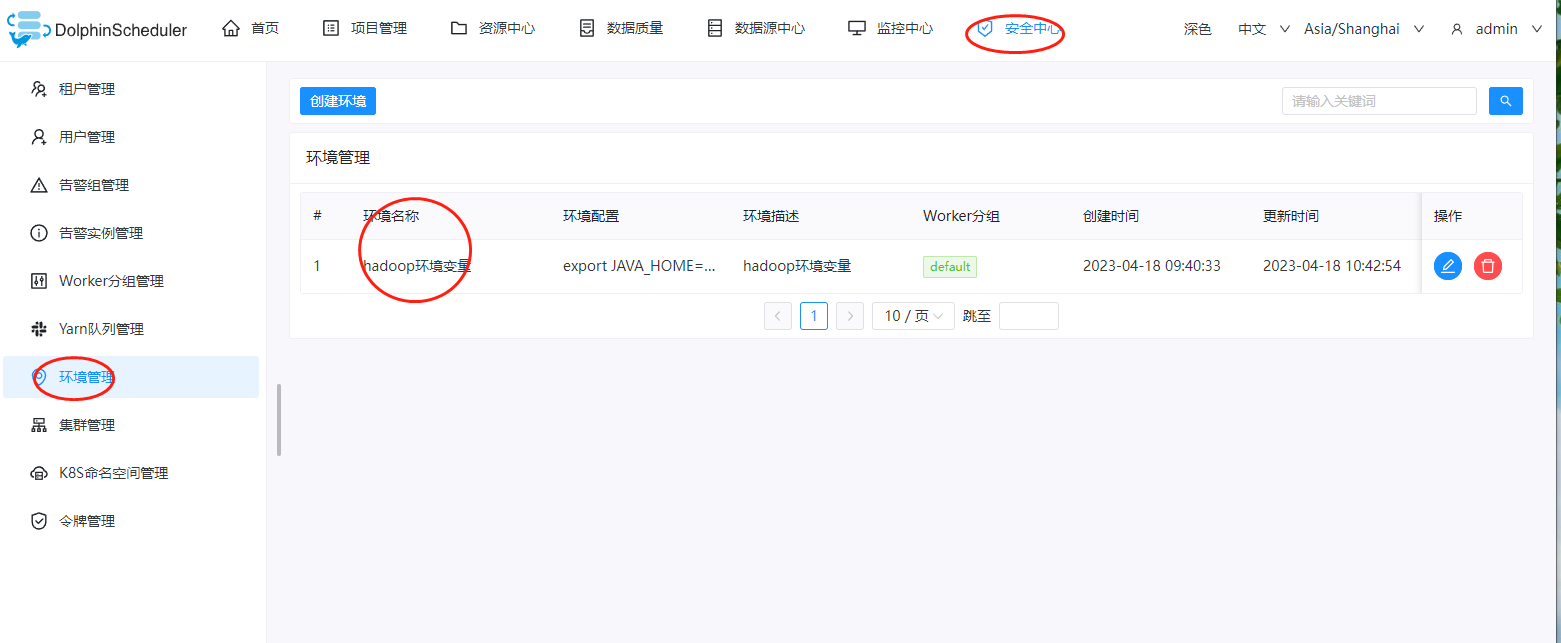
环境变量里面的配置如下:
export JAVA_HOME=/usr/local/jdk1.8.0_271
export HADOOP_HOME=/home/pubserver/hadoop-3.3.5
export HBASE_HOME=/home/pubserver/hbase-2.5.3
export HIVE_HOME=/home/pubserver/hive3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin
export HADOOP_CLASSPATH=/home/pubserver/hadoop-3.3.5/etc/hadoop:/home/pubserver/hadoop-3.3.5/share/hadoop/common/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/common/*:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs/*:/home/pubserver/hadoop-3.3.5/share/hadoop/mapreduce/*:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn/*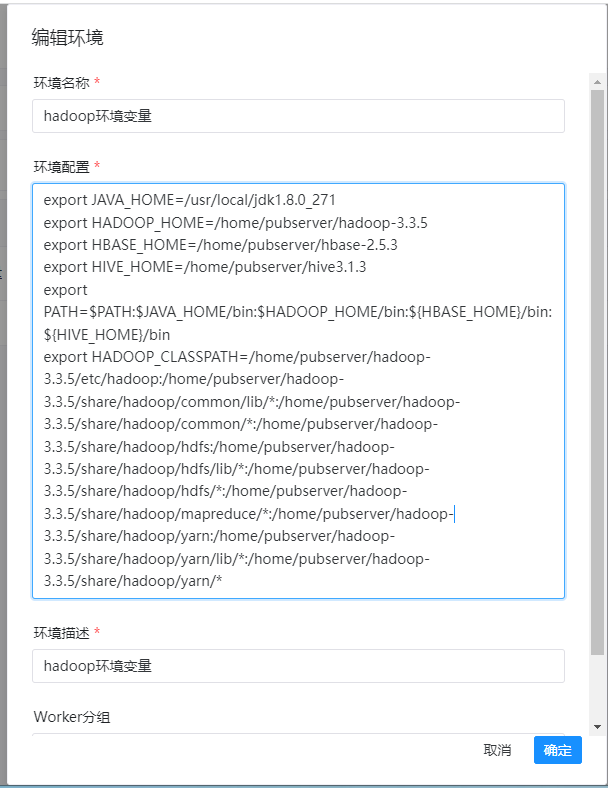
三、创建一个工作流
这里我们还是在刚才创建的hive测试项目里面创建一个新的工作流,组件使用hive cli
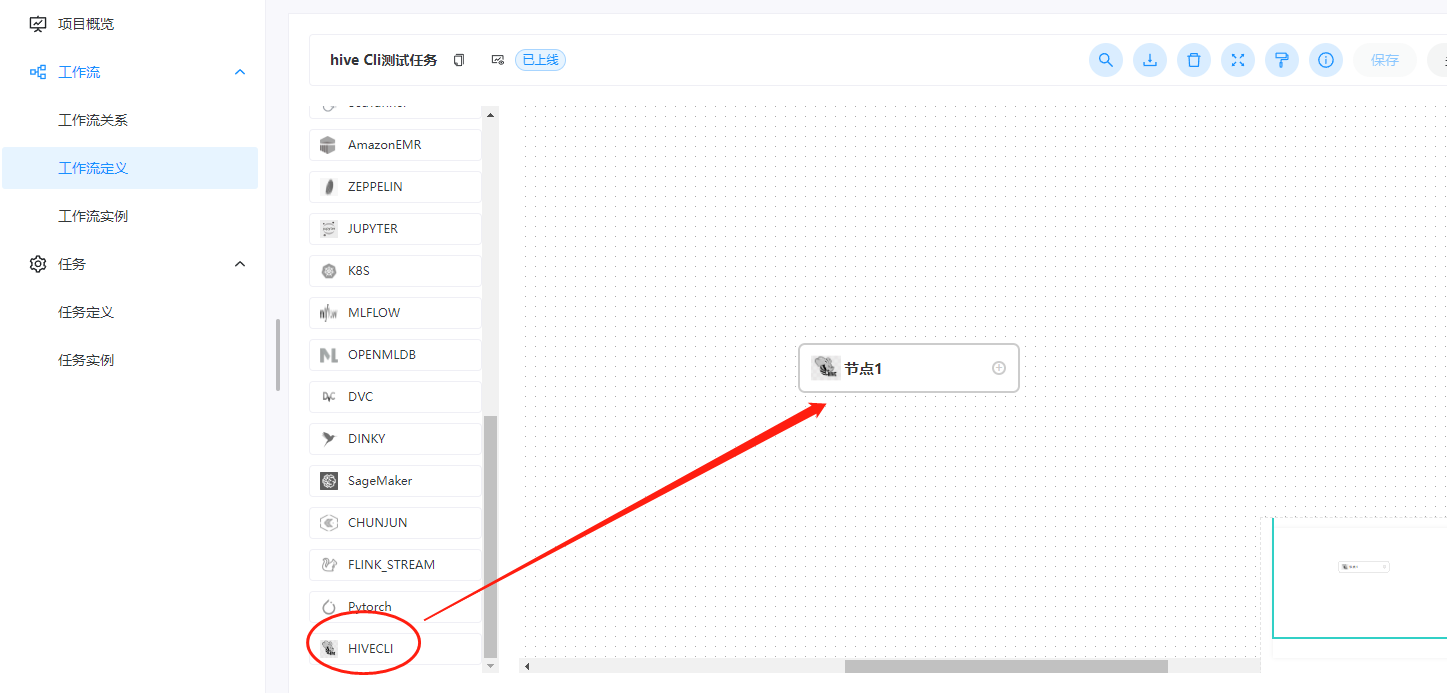
配置信息如下:
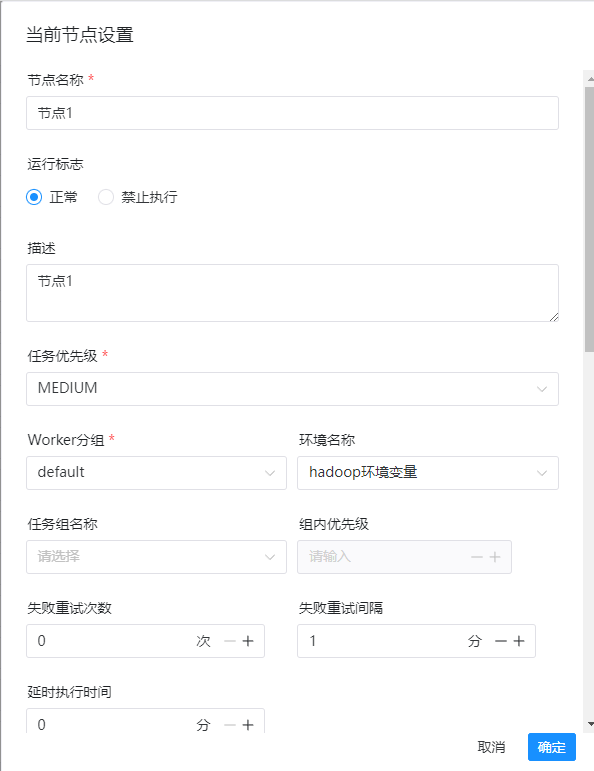
1)节点名称(随便填写)
节点1
2)运行标志
正常
3)环境名称(选择刚才添加的hadoop环境)
hadoop环境变量
4)hive cli任务类型(这里有两种,一种直接是命令,一种是文件,根据实际情况进行选择即可)
from script
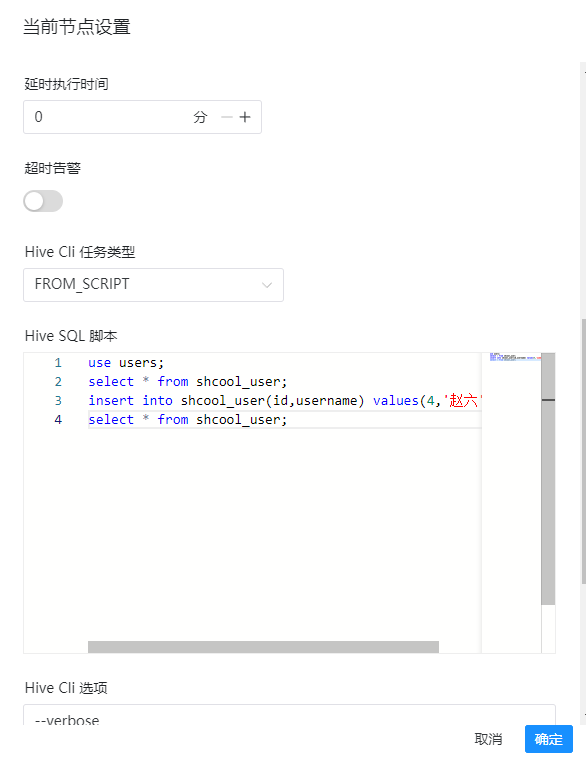
5)hive sql脚本
use users; select * from shcool_user; insert into shcool_user(id,username) values(4,'赵六'); select * from shcool_user;
这里我们执行4条sql,形成一个完整的任务链
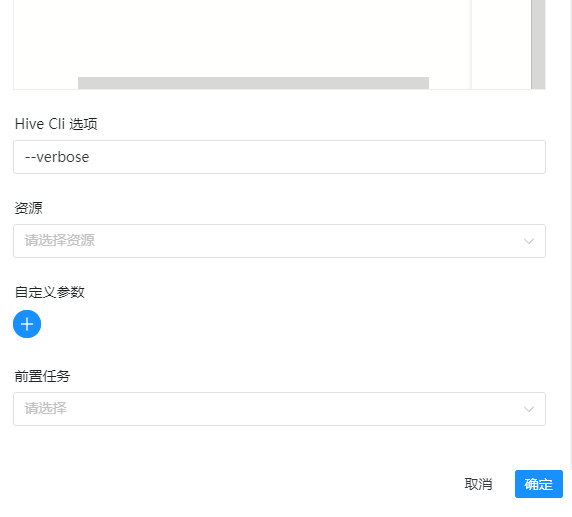
6)hive cli选项(标配加上verbose,主要是为了显示最后的执行结果)
--verbose
完整的配置如下图:
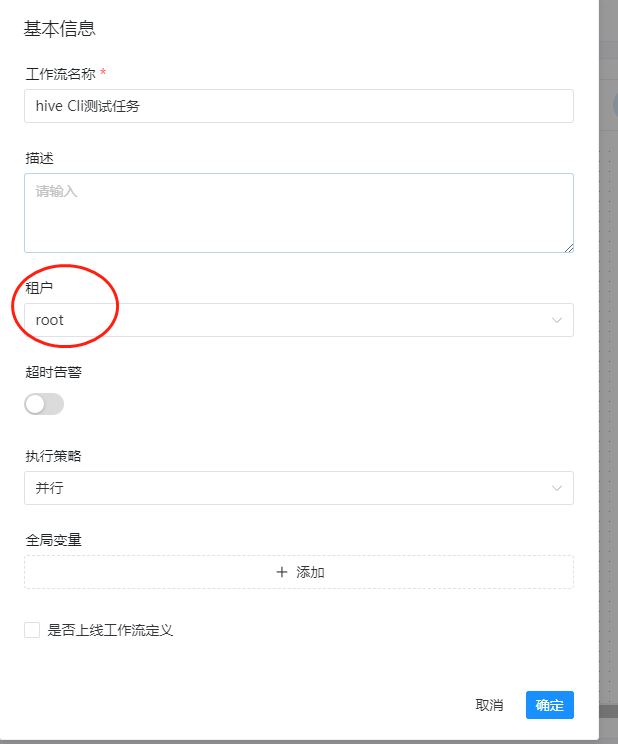
然后我们就配置完了,在保存的时候,记得租户选择root(因为服务端使用root账户安装的,使用其他账户,运行的时候会提示无权限)
四、运行测试
我们把工作流上线,然后再运行一下
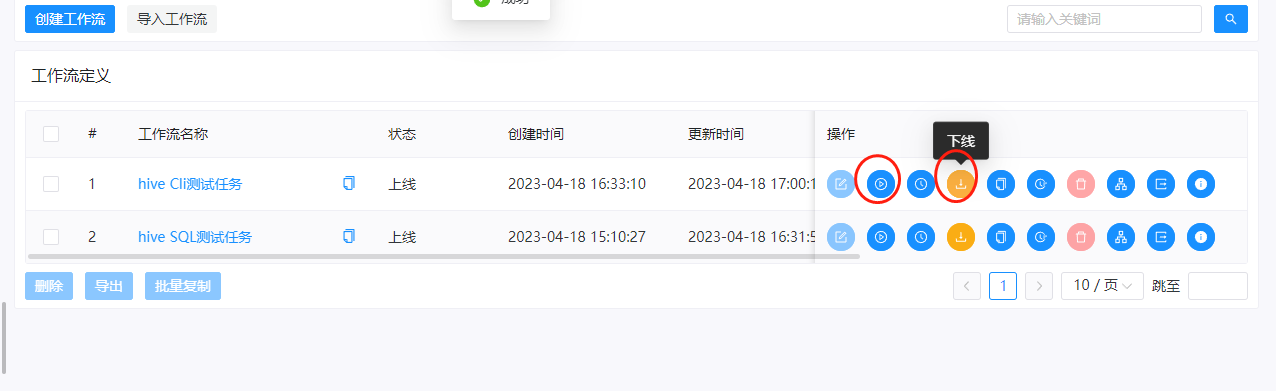
可以看到运行是成功的
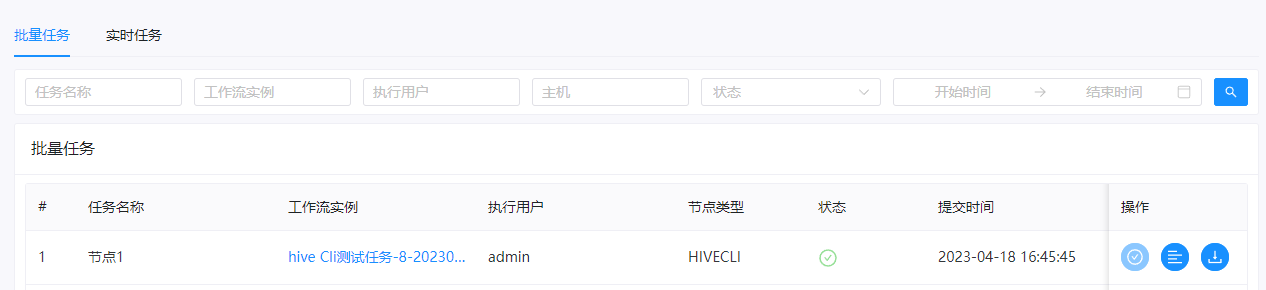
然后我们看下日志:
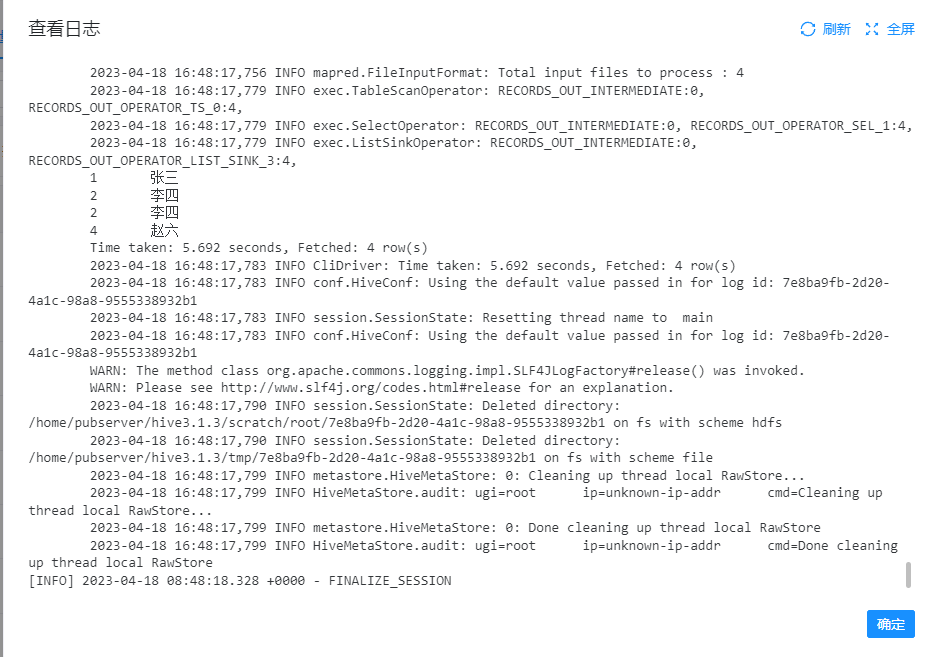
以上就是使用hive cli配置hive sql的运行教程。








还没有评论,来说两句吧...