
这篇文章我们介绍下使用DolphinScheduler来运行hive的sql,这样子很多定时任务等等都可以在这里运行起来。下面直接开始。
一、创建一个dolphinscheduler的租户
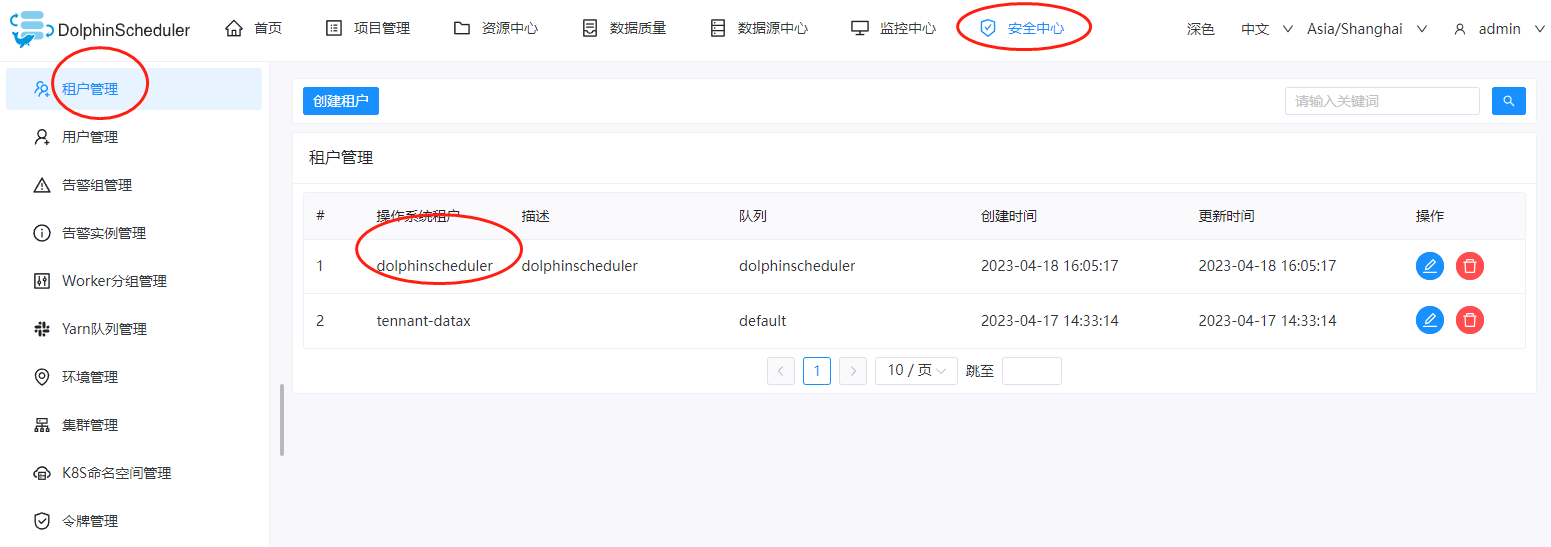
在hive的安装文章里面《Hive安装配置篇(二)配置Hive的jdbc连接使用用户名和密码》我们配置了一个名称为:dolphinscheduler的用户,由于在hive的sql里面经常会运行mapreduce,因此这里需要一个名称和hive配置里面一模一样的用户提交任务到yarn上,因此这里hive中我们创建了一个dolphinscheduler用户,那么我们就需要在linux节点上创建一个dolphinscheduler的用户,为了方便期间,我们直接在dolphinscheduler上创建一个名为dolphinscheduler的租户,这样子系统运行的时候,会自动在linux节点上创建一个名为dolphinscheduler的用户。依次点击:安全中心->租户管理->创建租户
二、进入到hive创建库和表
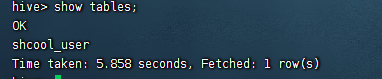
我们使用命令行进入到hive,创建库表
#进入到hive的shell中 cd /home/pubserver/hive3.1.3/bin ./hive #创建一个users的数据库 create database users; #使用users数据库 use users; #创建一张shcool_user的表 CREATE TABLE `shcool_user`( `id` int, `username` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'field.delim'=',', 'serialization.format'=',') STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' LOCATION 'hdfs://192.168.31.218:8020/user/hive/warehouse/users.db/shcool_user'
这里创建的库表主要是为了做数据演示。
三、创建一个hive的数据源
这里我们运行hive sql的时候,我们不是运行的hive cli,而是走的sql,因此这里我们需要创建一个数据源,依次点击:数据源中心->创建数据源,这里我们创建一个hive的数据源,示例图如下:
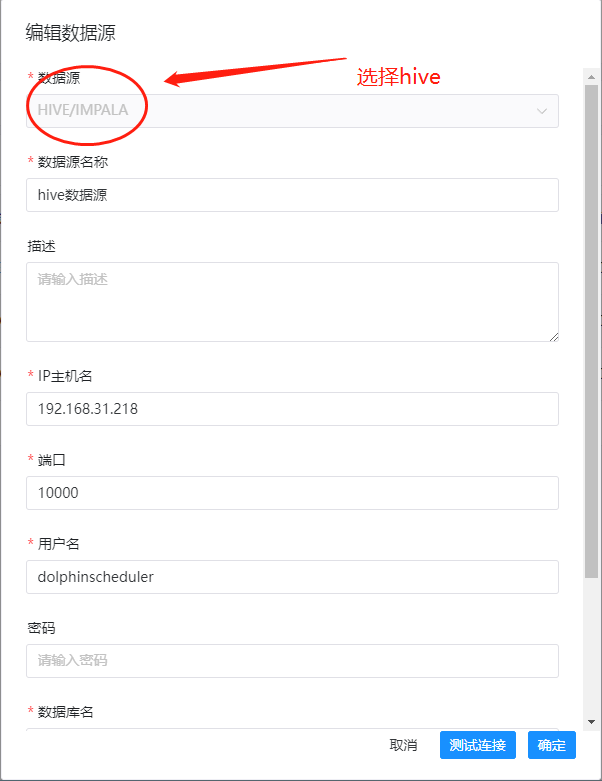
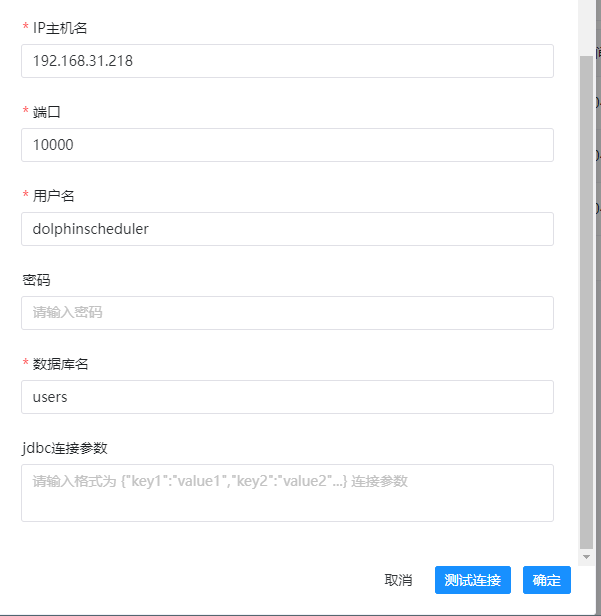
创建完成之后,我们就可以看到一个hive的数据源了

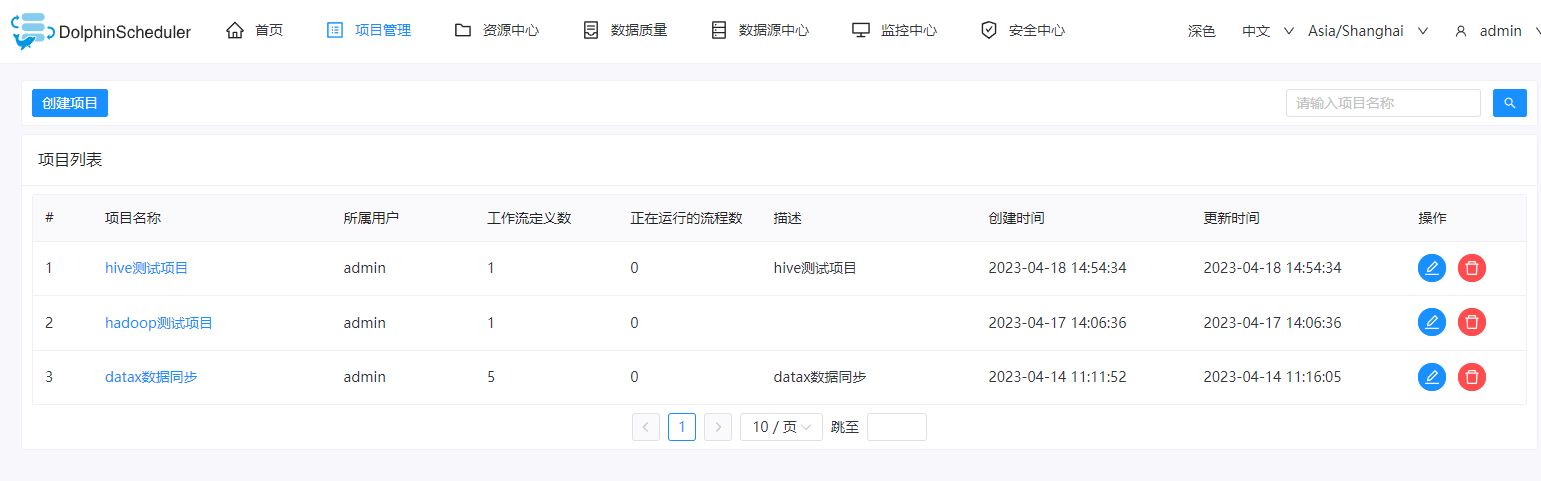
四、创建一个项目
这里我们创建一个名称为hive测试项目的项目
五、创建一个工作流定义
这里我们创建的工作流是选择sql,而不是hive cli,千万不要选择错了。
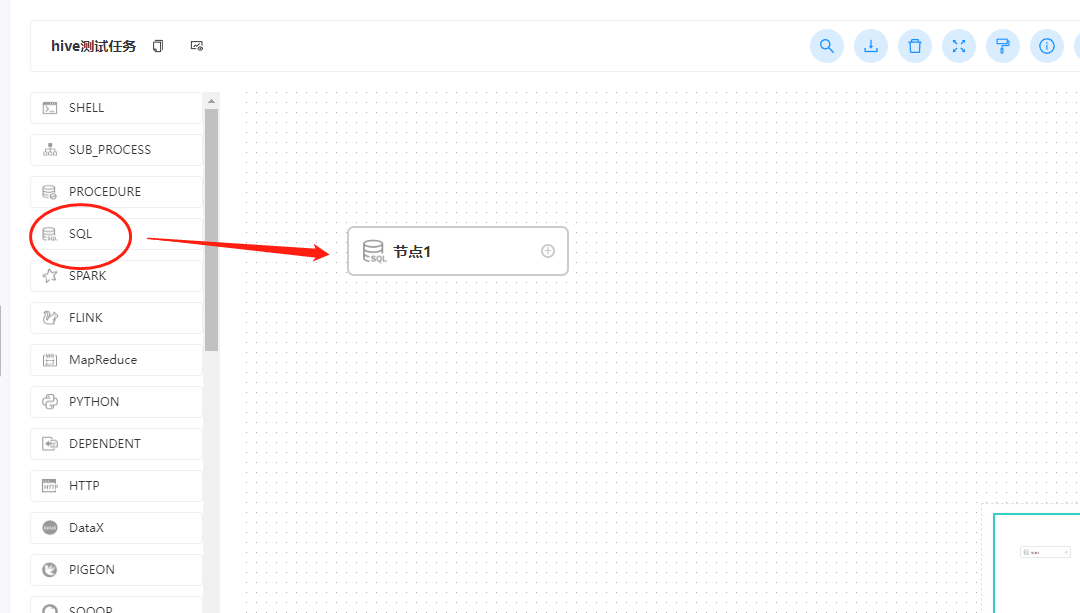
具体的配置信息如下:
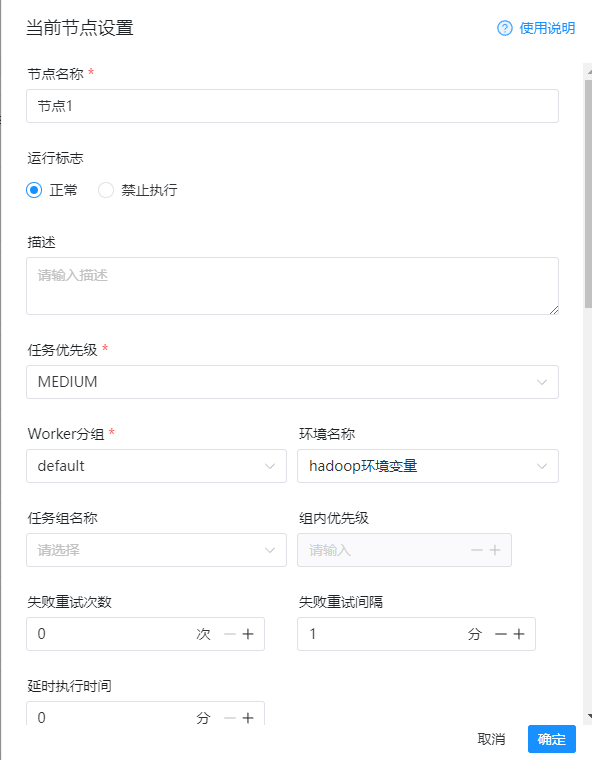
1)节点名称(随便填写)
node1
2)运行标志
正常
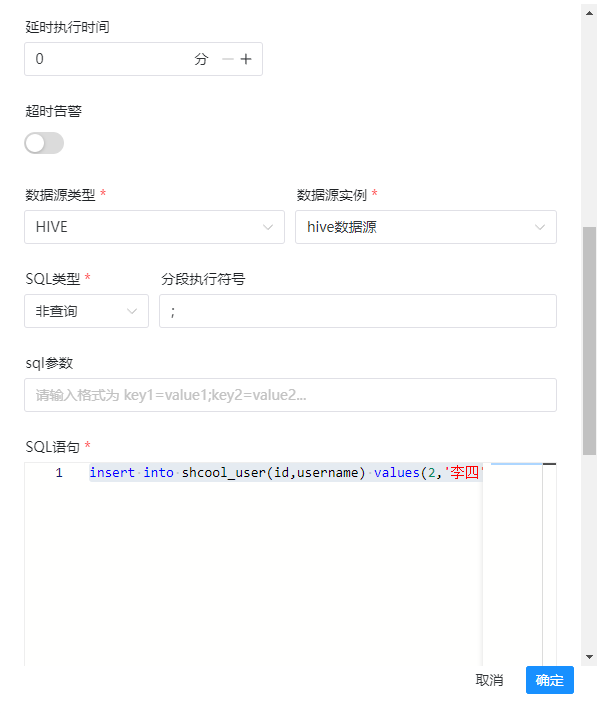
3)数据源类型
hive
4)数据源实例(刚才添加的数据源)
hive数据源
5)sql类型(随便选择)
非查询
6)sql语句
insert into shcool_user(id,username) values(2,'李四')
所有的配置如下图:
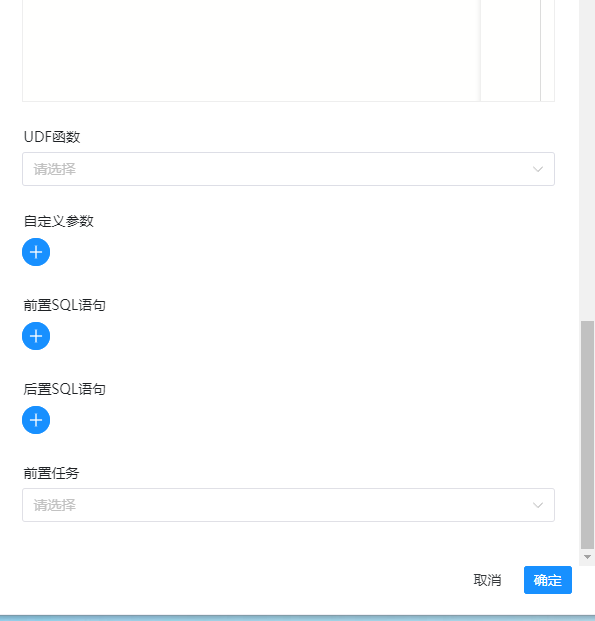
设置完成之后,点击保存,再点击右上角的保存
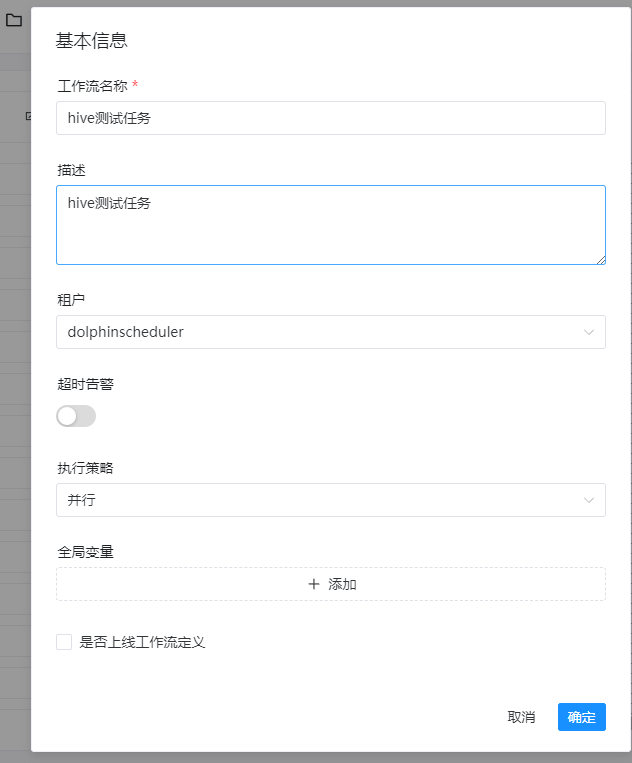
这里的租户记得一样要是hive的jdbc连接的同用户名。
这里的租户记得一样要是hive的jdbc连接的同用户名。
这里的租户记得一样要是hive的jdbc连接的同用户名。
六、运行测试
我们把这个工作流进行上线并且运行
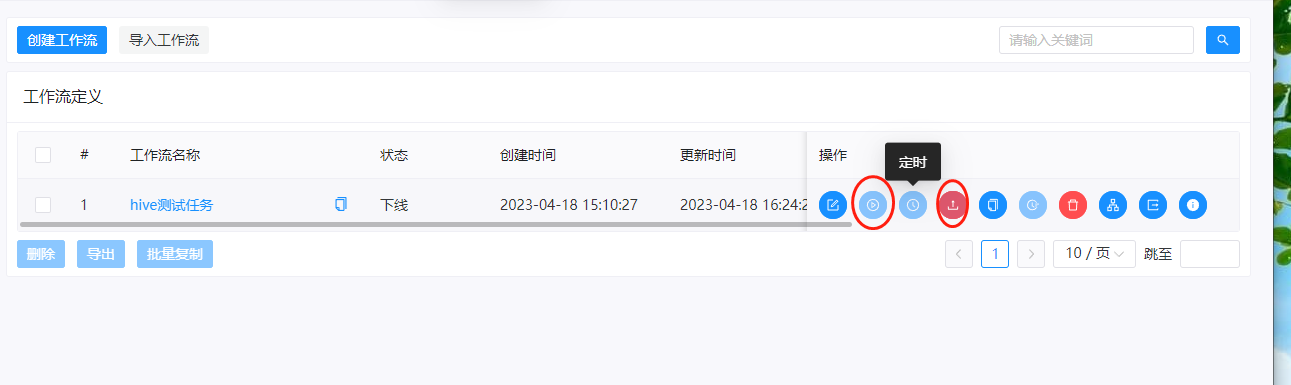
可以看到运行完全没有问题
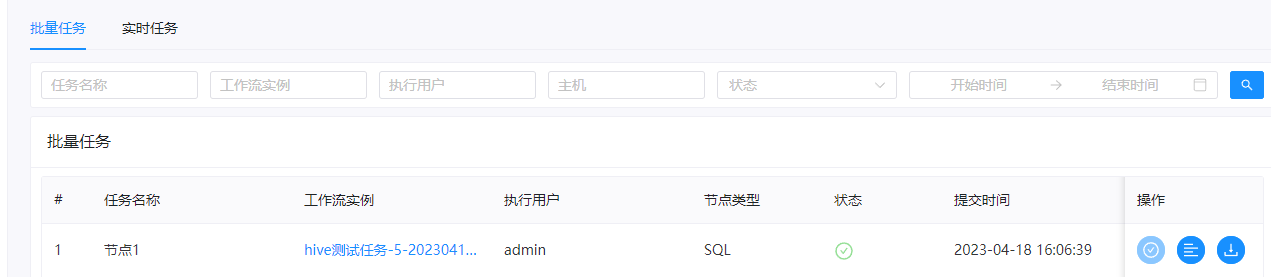
然后我们去hive中查询下数据
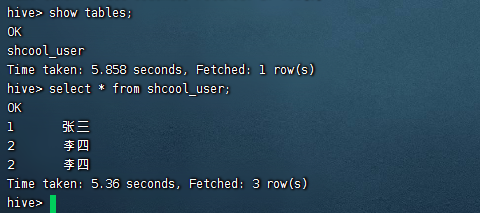
hive执行任务就完成了。








还没有评论,来说两句吧...