
上一篇文章《分布式调度系统Apache DolphinScheduler系列(五)配置资源管理的文件存储》我们介绍了文件存储的配置,这篇文章我们演示下把mapreduce的job任务提交到DolphinScheduler,然后利用DolphinScheduler来执行mapreduce任务。
一、首先准备一个hadoop集群
在前面的文章里面有相关的介绍。暂时不介绍了。
二、DolphinScheduler添加环境变量
在执行mapreduce的时候,我们需要把hadoop相关的环境变量给添加进来,因此这里我们依次点击:安全中心->环境管理->创建环境
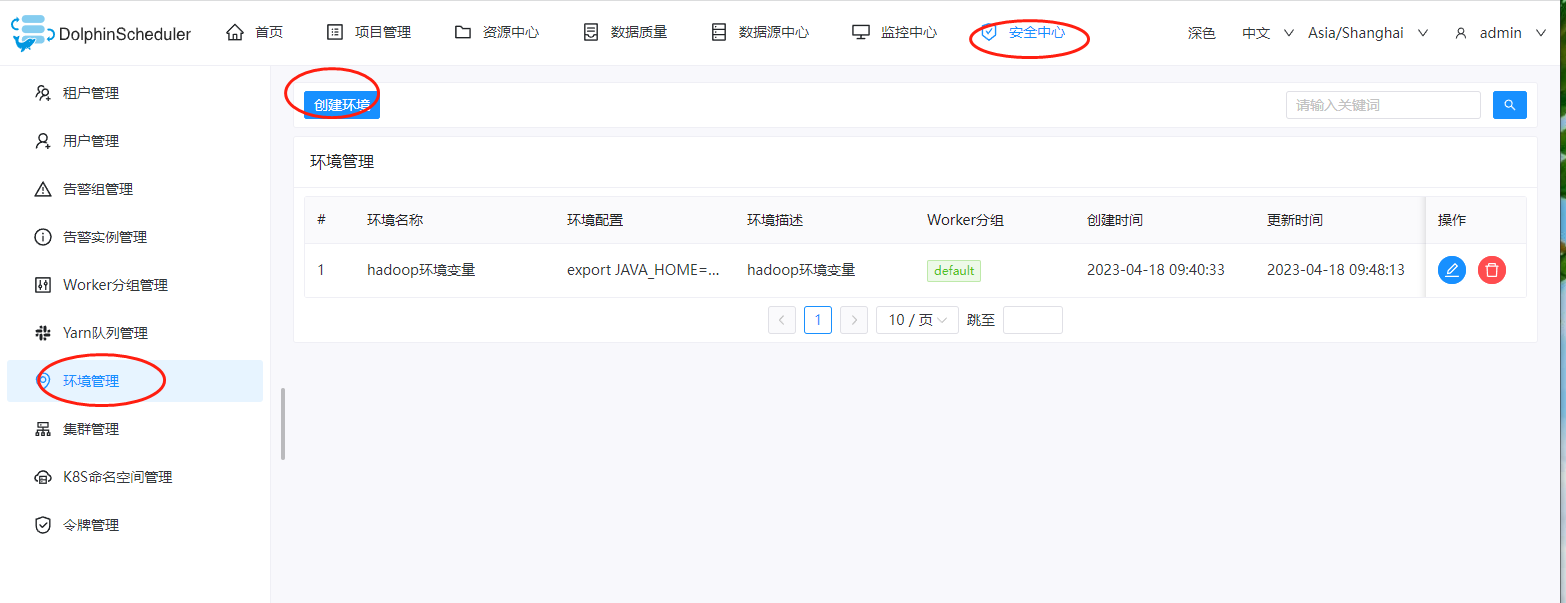
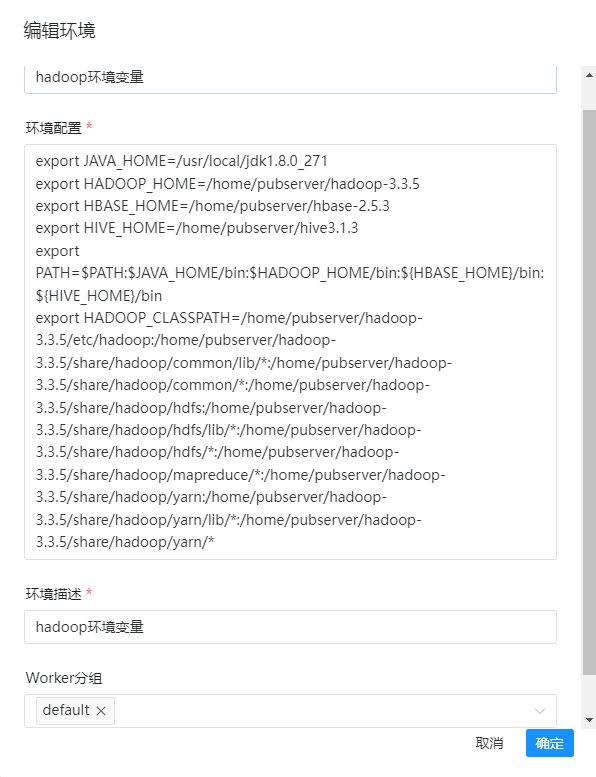
这里我们创建一个hadoop的环境变量,环境配置如下:
export JAVA_HOME=/usr/local/jdk1.8.0_271
export HADOOP_HOME=/home/pubserver/hadoop-3.3.5
export HBASE_HOME=/home/pubserver/hbase-2.5.3
export HIVE_HOME=/home/pubserver/hive3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin
export HADOOP_CLASSPATH=/home/pubserver/hadoop-3.3.5/etc/hadoop:/home/pubserver/hadoop-3.3.5/share/hadoop/common/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/common/*:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/hdfs/*:/home/pubserver/hadoop-3.3.5/share/hadoop/mapreduce/*:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn/lib/*:/home/pubserver/hadoop-3.3.5/share/hadoop/yarn/*详细的配置如下图:
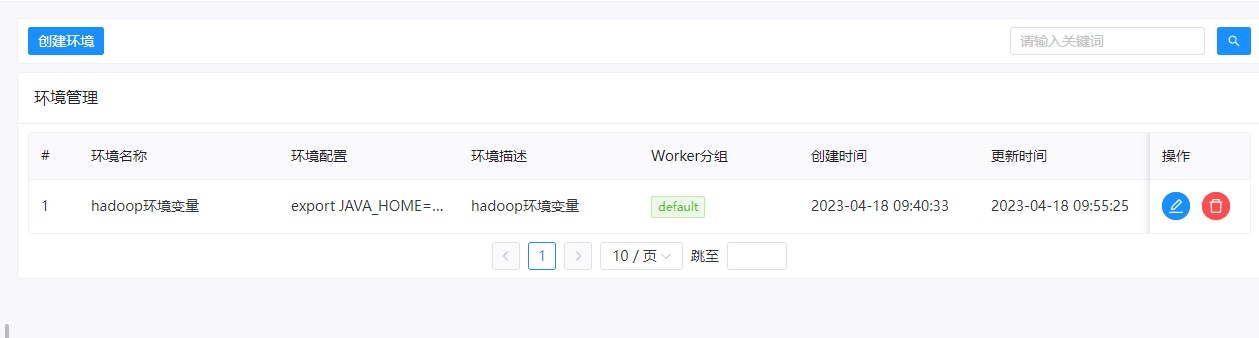
创建完成之后,可以在列表中看到对应的环境变量
三、上传wordcount项目到DolphinScheduler上
在hadoop中,自带有wordcount示例程序,在安装包的如下位置:${hadoop_home}/share/hadoop/mapreduce目录下有一个hadoop-mapreduce-examples-xxx.jar的jar包,我们把他下载下来,再上传到DolphinScheduler上。进入到DolphinScheduler的dashboard上,依次点击:资源中心->文件管理->上传文件
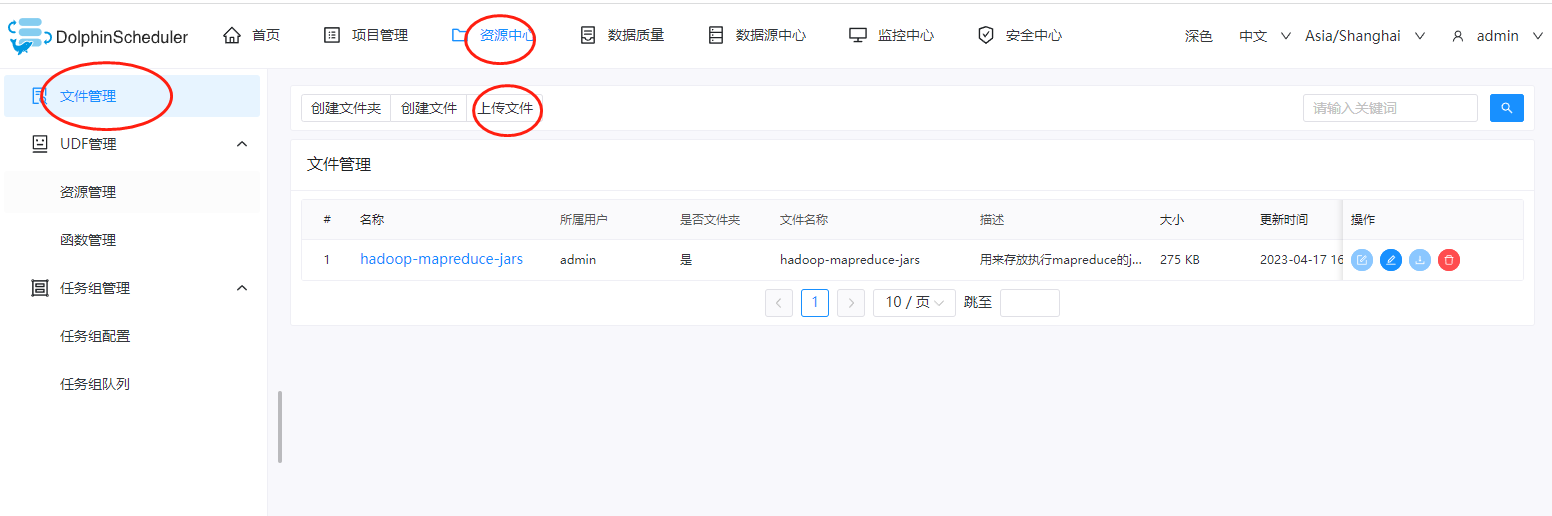
然后在这里上传刚才的example文件

四、创建一个项目
在DolphinScheduler上执行任务都是以项目为基础,因此这里我们创建一个名称为hadoop测试项目的项目
五、创建工作流
让我们在工作流定义里面创建一个wordcount的工作流
在工作流里面我们拖动一个mapreduce的选项进去
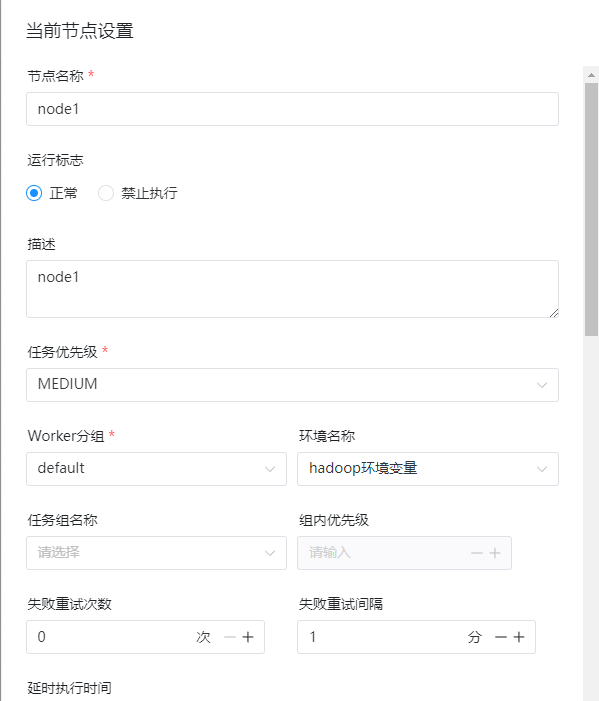
这里的配置如下:
1、节点名称(这个随便填写即可)
node1
2、运行标志
正常
3、描述(随便填写)
node1
4、任务优先级(保持默认即可)
MEDIUM
5、wordker分组(根据情况选择)
default
6、环境名称(选择刚才添加的hadoop环境变量)
hadoop环境变量
7、程序类型
java
8、主函数的class
wordcount
9、主程序包(选择刚才上传的example的jar包)
example-xxxx.jar
10、任务名称(随便填写)
wordcount
11、主程序参数(这里一个是输入文件,一个是输出文件,我们选择hdfs上即可)
hdfs://192.168.31.218:8020/test hdfs://192.168.31.218:8020/output
12、选项参数(添加一个yarn,不添加的话,执行成功后,mapreduce不会再yarn的8088 UI上显示)
-Dmapreduce.framework.name=yarn
13、资源(选择刚才上传的example的jar包)
example-xxx.jar
以上就是所有的配置,详情如下图:
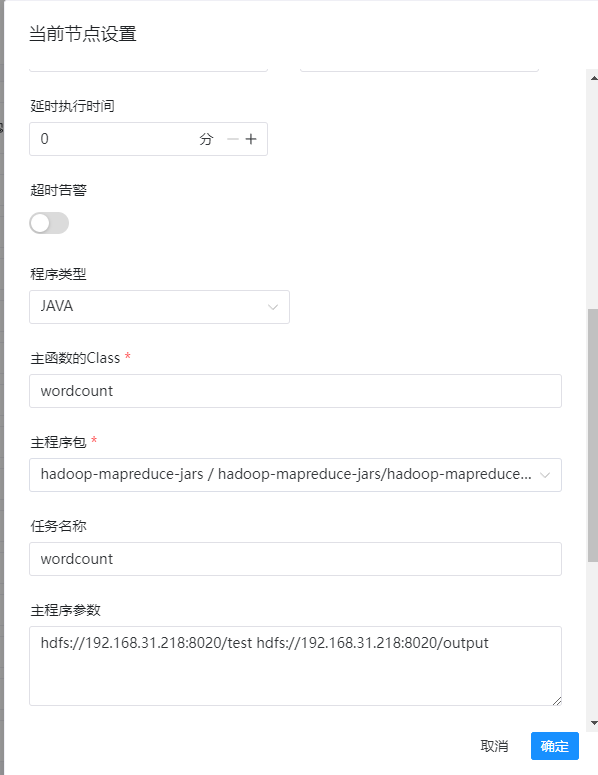
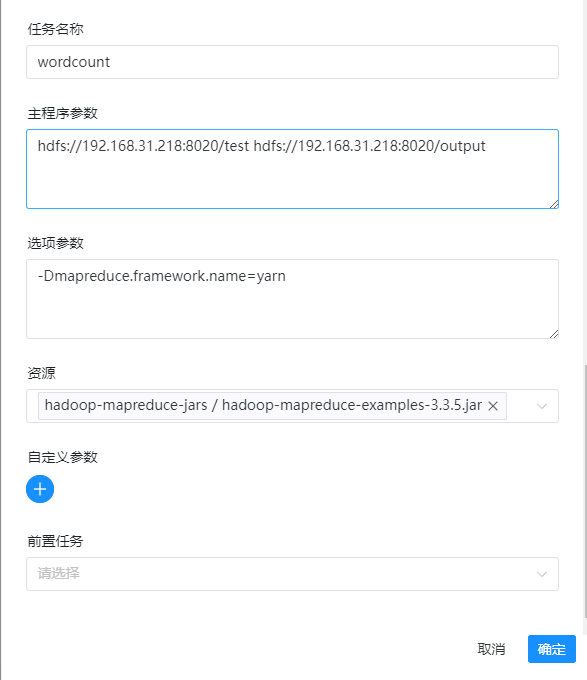
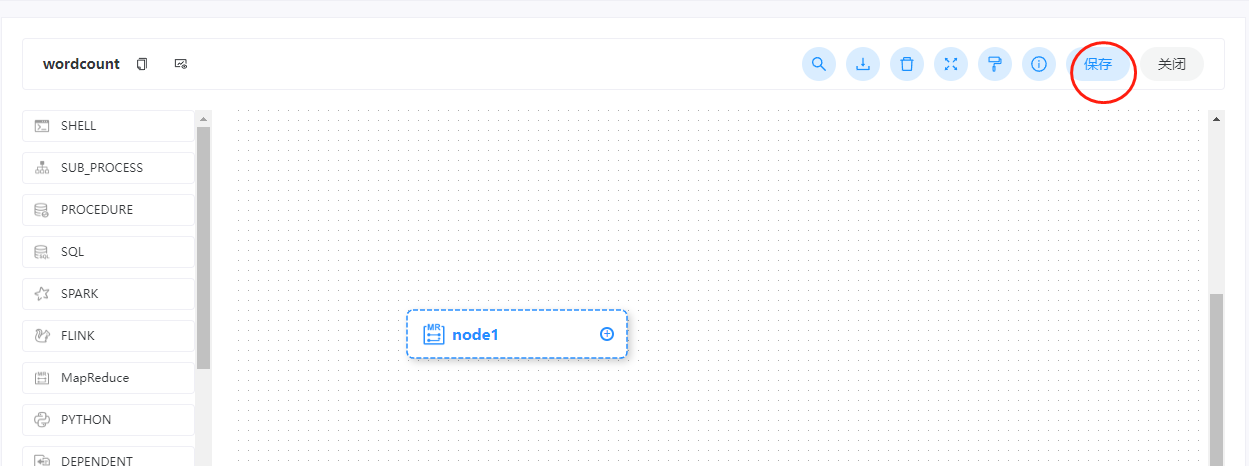
点击确定保存后,再点击右上角的保存按钮。
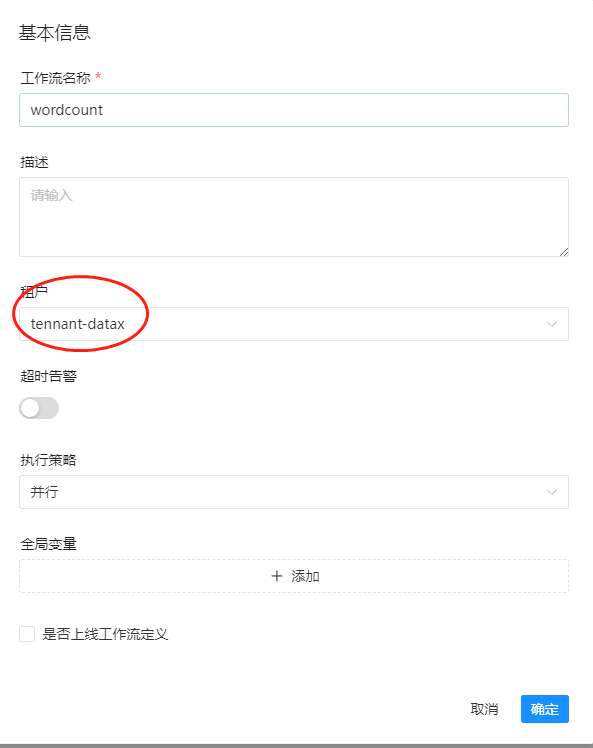
这里主要是定义一个工作流名称和租户即可,根据实际情况选择:
保存完毕之后,我们就可以吧项目上线+运行了
等待片刻,就可以看到运行成功了

然后我们去yarn上看看任务

可以看到mapreduce被成功运行了。
备注:
1、上面wordcount示例需要传入两个参数,一个是输入文件,一个是输出文件,输入文件的话,需要我们提前准备好,并且上传到hdfs文件系统上。








还没有评论,来说两句吧...