
上一篇文章《Doris系列(四十二)Doris的倒排索引介绍》我们对doris的倒排索引做了简单的介绍,本文的话,我们来演示一下doris中如何使用倒排索引。
在doris中使用倒排索引主要分为两个阶段,第一个阶段是创建索引,第二个阶段是查询。下面我们分开来介绍下。
创建索引
在doris中创建倒排索引的话,整体语法示例如下:
CREATE TABLE table_name
(
columns_difinition,
INDEX idx_name1(column_name1) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
INDEX idx_name2(column_name2) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese")] [COMMENT 'your comment']
INDEX idx_name3(column_name3) USING INVERTED [PROPERTIES("parser" = "chinese", "parser_mode" = "fine_grained|coarse_grained")] [COMMENT 'your comment']
INDEX idx_name4(column_name4) USING INVERTED [PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true|false")] [COMMENT 'your comment']
)
table_properties;从上文的语法中我们可以看到,在前面我们需要列举出来对应的表字段,然后在后面的时候指定index。执行index的话,我们主要是有2个主要信息,分别是:
USING INVERTED PROPERTIES
在这里Using inverted关键词是必须的(使用倒排索引的时候必须的,不用倒排索引没有这个关键词)他是用来标记当前的索引是倒排索引。
properties关键词的话是可选的,可以不选,也可以选择,如果不选的话,则不会进行分词,选的话我们可以指定对应的分词信息,指定分词涉及到的一共有3个关键词,下面挨个介绍下:
1)parser
这个parser主要是指定分词器,指定分词器的话一般主要是3个,分别是:english,chinese,unicode,具体示意如下:
english是英文分词,适合被索引列是英文的情况,用空格和标点符号分词,性能高 chinese是中文分词,适合被索引列主要是中文的情况,性能比english分词低 unicode是多语言混合类型分词,适用于中英文混合、多语言混合的情况。它能够对邮箱前缀和后缀、IP地址以及字符数字混合进行分词,并且可以对中文按字符分词。
2)parser_mode
用于指定分词的模式,目前这个分词主要是针对于中文,有两个选择,分别是:fine_grqained和coarse_grained,具体示意如下:
fine_grained:细粒度模式,倾向于分出比较短的词,比如 '武汉市长江大桥' 会分成 '武汉', '武汉市', '市长', '长江', '长江大桥', '大桥' 6个词 coarse_grained:粗粒度模式,倾向于分出比较长的词,,比如 '武汉市长江大桥' 会分成 '武汉市' '长江大桥' 2个词 默认coarse_grained
3)support_phrase
这里是用于指定索引是否支持MATCH_PHRASE短语查询加速
true为支持,但是索引需要更多的存储空间 false为不支持,更省存储空间,可以用MATCH_ALL查询多个关键字 默认false
下面我们做一个案例来创建倒排索引,示例sql如下:
CREATE TABLE `township` (
`id` int(11) NOT NULL,
`province` varchar(60) NULL,
`province_code` varchar(60) NULL,
`city` varchar(60) NULL,
`city_code` varchar(60) NULL,
`area` varchar(60) NULL,
`area_code` varchar(60) NULL,
`town` varchar(60) NULL,
`town_code` varchar(60) NULL,
INDEX idx_name1(town) USING INVERTED PROPERTIES("parser" = "chinese", "parser_mode" = "fine_grained", "support_phrase" = "true")
) ENGINE=OLAP
Duplicate KEY(`id`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"is_being_synced" = "false",
"storage_format" = "V2",
"light_schema_change" = "true",
"disable_auto_compaction" = "false",
"enable_single_replica_compaction" = "false"
);这里我们给town字段添加了倒排索引。然后我们再插入一条数据进去:
INSERT INTO `township`(`id`, `province`, `province_code`, `city`, `city_code`, `area`, `area_code`, `town`, `town_code`) VALUES (1, '河北省', '130000', '石家庄市', '130100', '新华区', '130105', '合作路街道', '130105007');
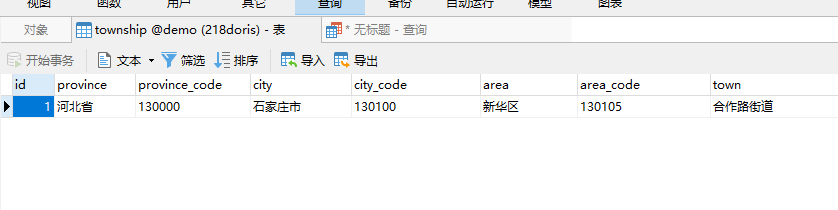
查询
在doris中如果用查询的话,我们可以使用like或者match_all或者match_any函数。使用like的话不会走倒排索引,使用match_all或者match_any的时候会使用倒排索引,效率比like高很多,下面我们来演示下查询:
1)使用like查询,示例sql如下:
select * from township where town like "%作路%"
结果如下图:
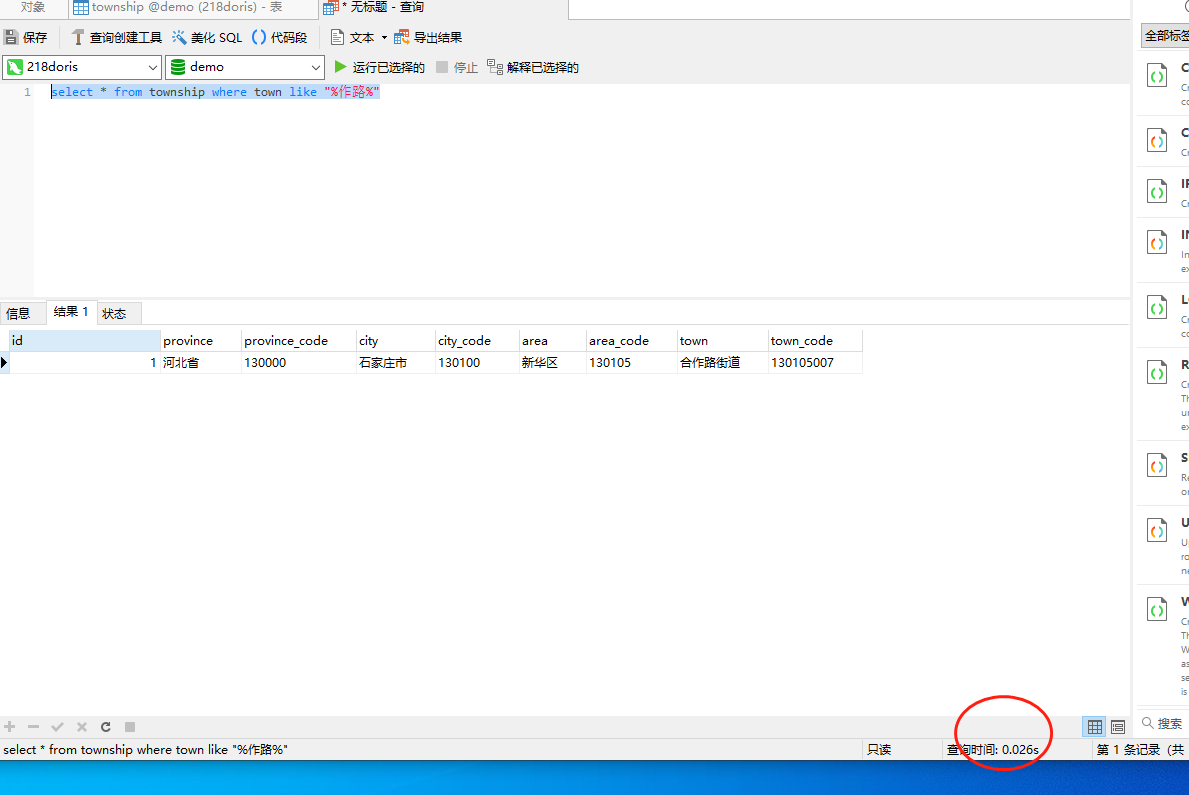
可以看到查询时间花了0.026s。
2)使用match_any查询,示例sql如下:
select * from township where town match_any "作路"
效果图如下:
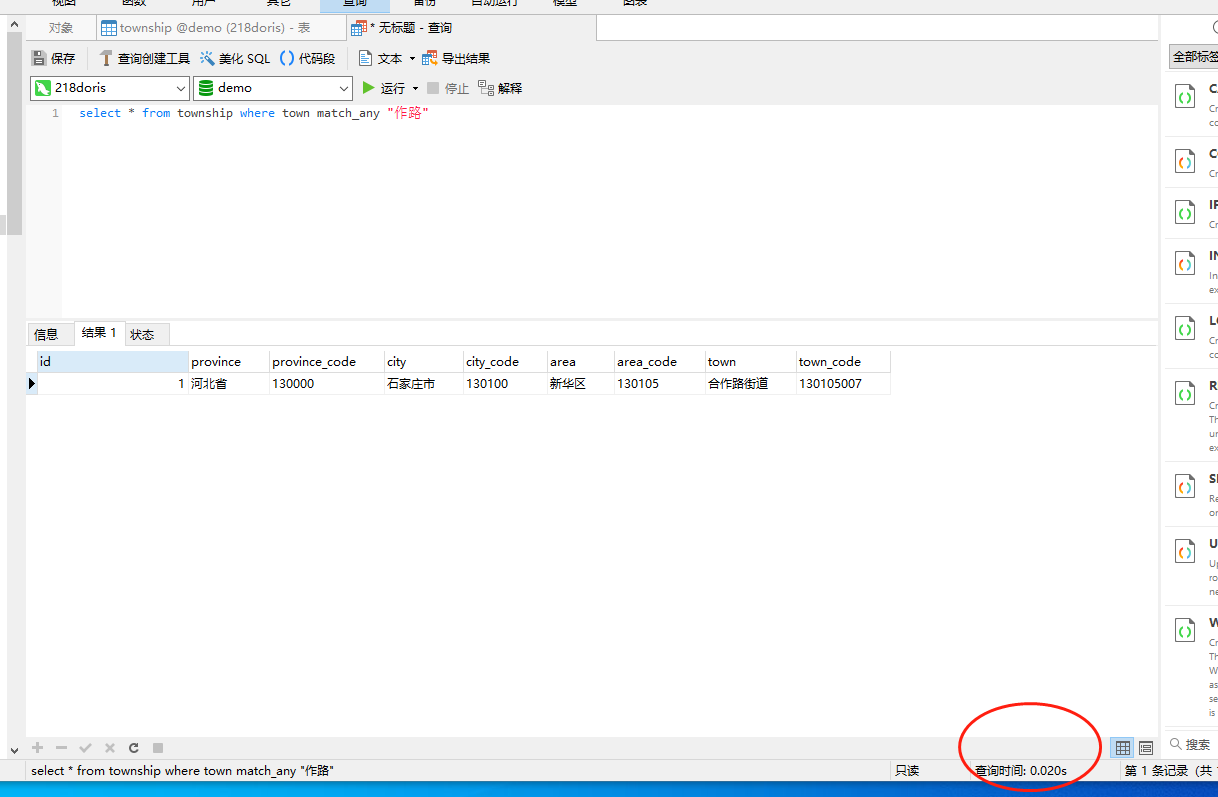
可以看到这里查询只用了0.020s,在数据量非常大的情况下,查询时间会更有显著的效果。
以上就是在doris2.x版本里面使用倒排索引的案例。








还没有评论,来说两句吧...