
在Doris中我们如果使用倒排索引的话,那么对应部分字段我们会涉及到分词,本文的话,我们来介绍下分词的使用测试案例。
1)测试中文细粒度分词
SELECT TOKENIZE('中华人民共和国','"parser"="chinese","parser_mode"="fine_grained"');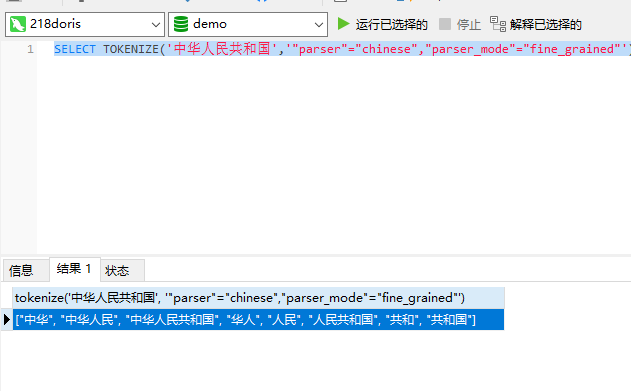
2)测试中文粗粒度分词
SELECT TOKENIZE('中华人民共和国','"parser"="chinese","parser_mode"="coarse_grained"');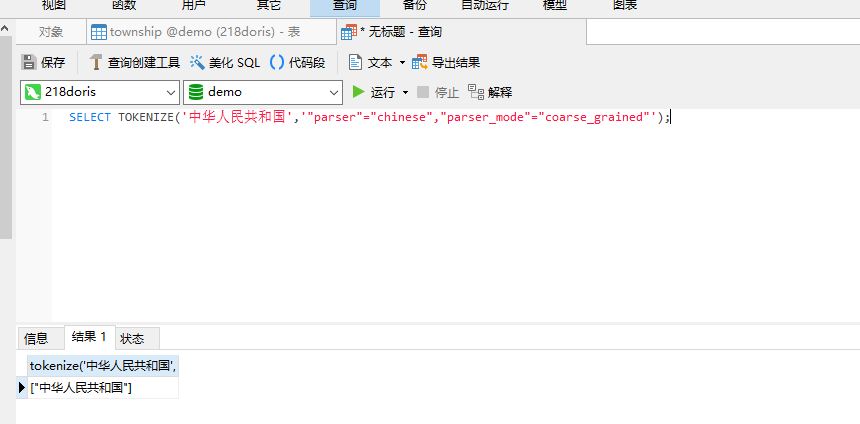
3)测试英文分词
SELECT TOKENIZE('I love CHINA','"parser"="english"');
4)测试中英文混合分词
SELECT TOKENIZE('I love CHINA 中华人民共和国','"parser"="unicode"');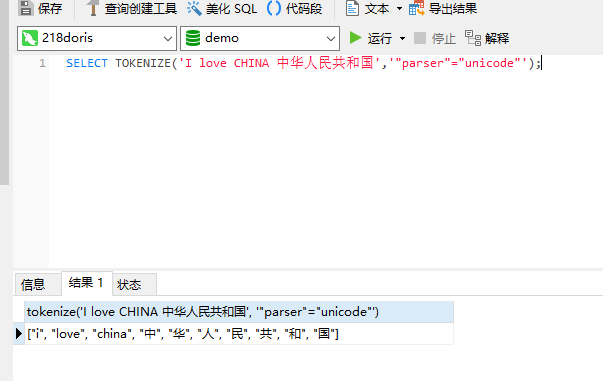
从上面的分词测试结果可以看出,混合分词和英文分词的效果都差不多,如果是中文的话,还是建议使用中文分词。








还没有评论,来说两句吧...