
在实际的情况下,我们经常会涉及到做数仓,那么数据同步就是一个很大的事情,目前基于数仓的产品的话,大部分都是使用doris来进行做数仓的构建,因此这里的话我们来演示下案例,就是从Doris的jdbc的catalog多数据源目录中导入数据。
在前面《Doris系列(三十六)Multi-Catalog 功能》我们介绍过doris的多数据源目录,当我们在doris中建立起来jdbc的多数据源目录之后,我们就可以直接在doris上查询对应的mysql里面的数据了,但是其实这样子的话对于我们做数据应用来说,一般我们不会这么来操作,主要是因为像这种多数据源,他得数据其实还是存在mysql里面的,相对应来说mysql可以看作是doris的外部表,虽然可以查询,但是查起来很慢,所以真正在做数仓的时候,我们会涉及到把数据同步到doris中,利用doris的存储引擎和查询引擎来构建数仓。
今天这个案例的背景是这样的:
我们有一个刷卡消费的系统,会涉及到有一些账户扣费的情况,也就是刷卡的时候会生成一次刷卡消费记录,同时还会产生一条账户扣费支付的记录。 在这个应用场景中,我们每天会产生大量的数据,预估一天在20W到50W左右的数据,然后在相关的业务系统中存在对于这些表做统计的需求。 在业务系统中我们的数据时直接存储在mysql中的,但是随着这些数据的日积月累,数据量存储会越来越多,那么如何在统计相关的业务中使得查询不那么慢就成了问题,所以我们基于这个需求点来进行改造。 本文仅演示基础部分,不演示业务相关的处理逻辑。
基于上面的需求,我们来看看实际的情况,在本案例里面,我们线下有一个300多W的数据表,示例如下:
此时我们对这个表做分天简单统计的时候,例如执行如下的sql:
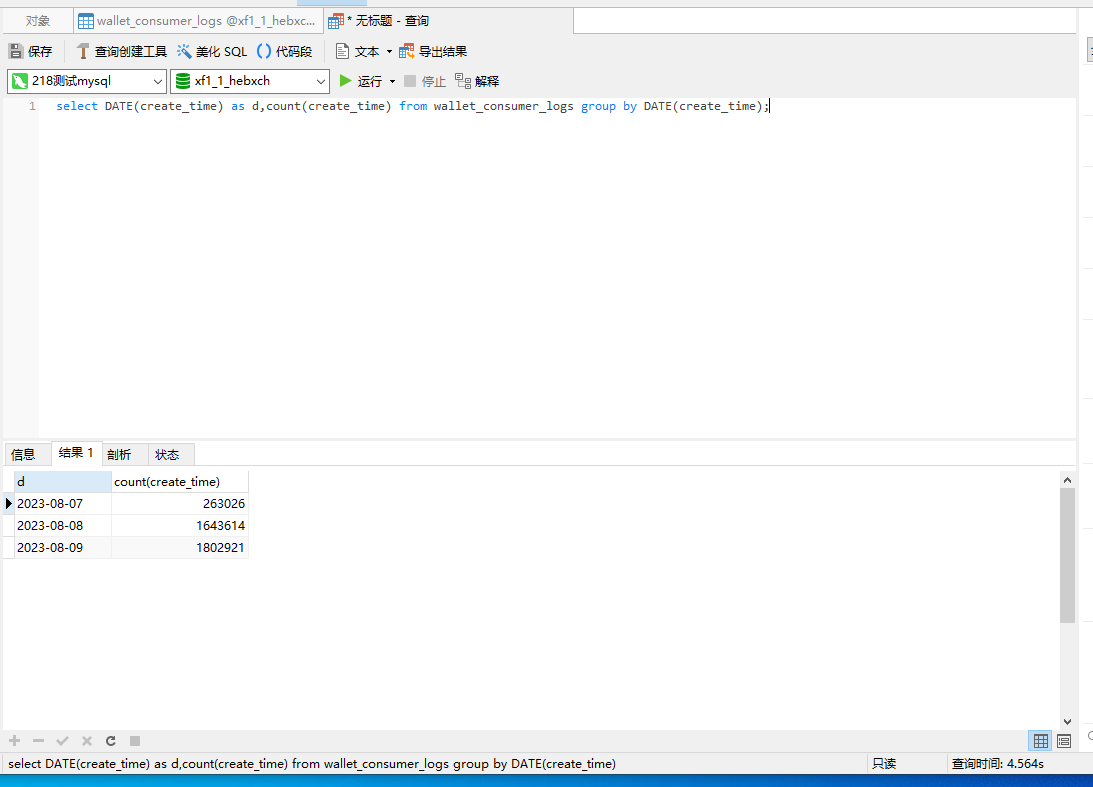
select DATE(create_time) as d,count(create_time) from wallet_consumer_logs group by DATE(create_time);
像上诉的简单sql我们在查询的时候都要耗时4到5秒的样子:
对于熟悉bi的同学来说,一般BI页面上一个页面不止一个统计,同时还会涉及到更加复杂的BI统计,像我们这个3天的数据查询都要花费4-5秒,那么整个做出来的系统查询是不是得更慢了。严重的印象客户的体验。所以在这里我们准备的方案是把数据先放到doris的ods层,先做第一次的简单优化,提升统计页面的查询显示速度。下面我们直接开始。
准备一个doris
这里我们演示的doris版本是2.0.1版本,演示的环境是单机环境。
mysql的创建语句
刚才提到,我们300W左右的数据是放在mysql里面的,目前我们对应的表是:wallet_consumer_logs,此表的建表语句如下:
CREATE TABLE `wallet_consumer_logs` ( `id` bigint(19) NOT NULL, `order_no` varchar(21) DEFAULT NULL COMMENT '流水号', `transaction_id` varchar(40) DEFAULT NULL COMMENT '第三方支付流水号', `time_bucket_id` bigint(19) DEFAULT NULL COMMENT '时间段id', `device_id` bigint(19) DEFAULT NULL COMMENT '设备id', `costs_consume_log_id` bigint(19) DEFAULT NULL COMMENT '消费机消费记录id', `wallet_user_id` bigint(19) DEFAULT NULL COMMENT '用户钱包id', `wallet_type` int(11) DEFAULT NULL COMMENT '钱包类型,0:余额钱包,1、补贴钱包', `wallet_user_balance` decimal(10,2) DEFAULT NULL COMMENT '扣款前的余额', `op_type` tinyint(1) DEFAULT NULL COMMENT '1:充值;2:减款;3:消费;4:补贴;5:退款;6补扣;7余额清理', `op_user` varchar(30) DEFAULT NULL COMMENT '操作用户', `amount` decimal(10,2) DEFAULT NULL COMMENT '本次操作金额', `user_relation_id` varchar(19) DEFAULT NULL COMMENT '消费者用户id 云校园 用户表字段', `remark` varchar(255) DEFAULT NULL COMMENT '备注', `create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间', `update_time` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间', `school_id` bigint(19) DEFAULT NULL COMMENT '学校id', `branch_id` bigint(19) unsigned DEFAULT NULL COMMENT '校区id', `dept_id` bigint(19) DEFAULT NULL COMMENT '部门id', PRIMARY KEY (`id`) USING BTREE, KEY `idx_school_id` (`school_id`) USING BTREE, KEY `idx_branch_id` (`branch_id`) USING BTREE, KEY `idx_dept_id` (`dept_id`) USING BTREE, KEY `idx_user_relation_id` (`user_relation_id`) USING BTREE, KEY `idx_order_no` (`order_no`) USING BTREE, KEY `idx_costs_consume_log_id` (`costs_consume_log_id`) USING BTREE, KEY `idx_device_id` (`device_id`) USING BTREE, KEY `idx_wallet_user_id` (`wallet_user_id`) USING BTREE, KEY `idx_op_type` (`op_type`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='钱包的所有消费记录日志表';
整张表的数据是:3709561条数据。
方案思考
对于mysql的数据同步到doris中,其实有很多方法,例如我们常见的:
binlog同步 flink-cdc同步 flink-mysql同步 数据湖catalog同步
这里的话,针对上诉几个步骤来说,比较常用的主要还是flink-cdc的同步和catalog同步,像这些数据同步方案来说,代价最小的当然就是catalog同步了,而且基于数据湖来进行数据同步,在doris里面效率是最高的。所以这里的话,我们数据同步的方案选择数据湖catalog的方式进行同步。
创建catalog
我们这里既然选择了catalog数据湖同步,那么我们就需要在doris中创建对应的数据湖,这里我们创建的sql语句如下:
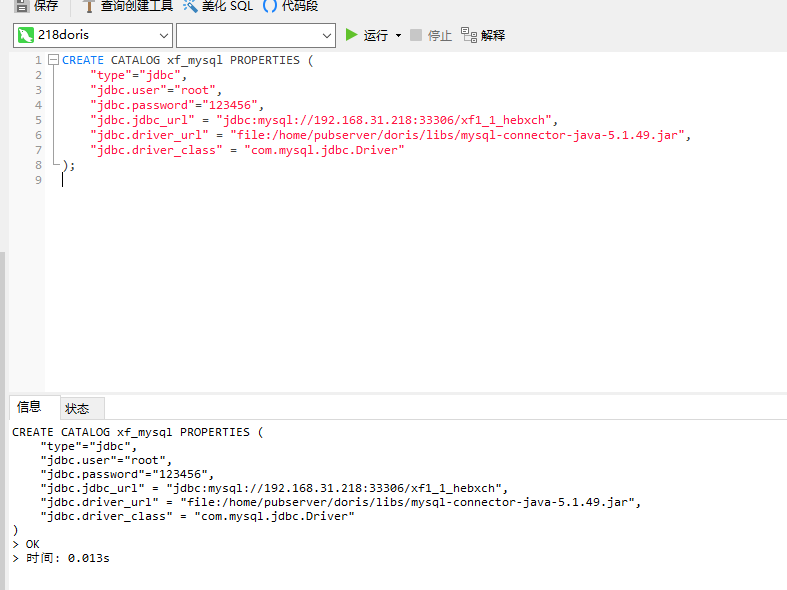
CREATE CATALOG xf_mysql PROPERTIES ( "type"="jdbc", "jdbc.user"="root", "jdbc.password"="123456", "jdbc.jdbc_url" = "jdbc:mysql://192.168.31.218:33306/xf1_1_hebxch", "jdbc.driver_url" = "file:/home/pubserver/doris/libs/mysql-connector-java-5.1.49.jar", "jdbc.driver_class" = "com.mysql.jdbc.Driver" );
这里我们使用navicat进行创建即可,示例图如下:
然后我们查看下当前doris中的多数据源目录:
show catalogs;
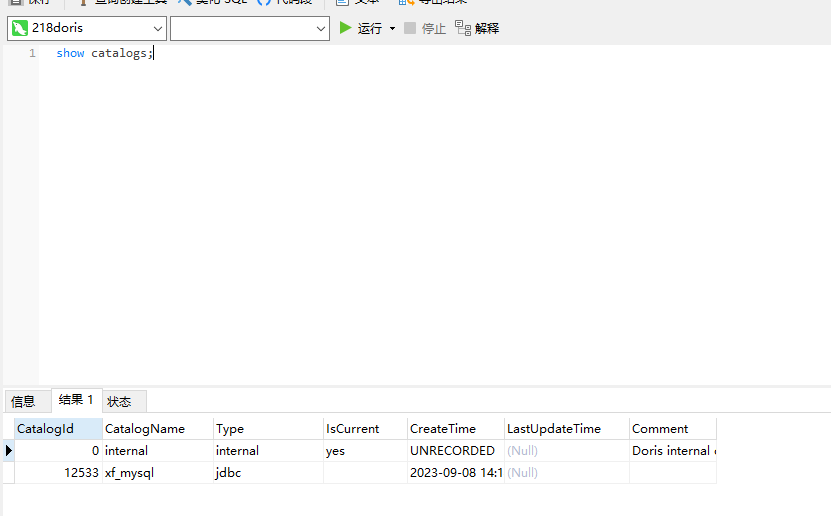
这里我们的catalog创建完毕之后,我们就可以看到doris中带有我们刚才创建的名称为:xf_mysql的catalog多数据源目录了,此时我们的数据湖就创建好了,接着我们就可以直接使用doris来查询刚才这个mysql里面的数据了,示例如下:
1)切换到xf_mysql多数据源目录:
switch xf_mysql;
2)查看当前多数据源目录有哪些数据库:
show databases;
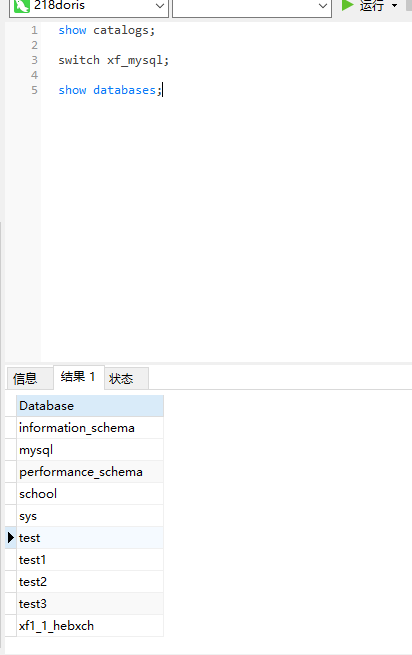
这里就可以看到mysql里面所有的库了。
3)使用xf1_1_hebxch的库
use xf1_1_hebxch;
4)查看当前xf1_1_hebxch库下有哪些表:
show tables;
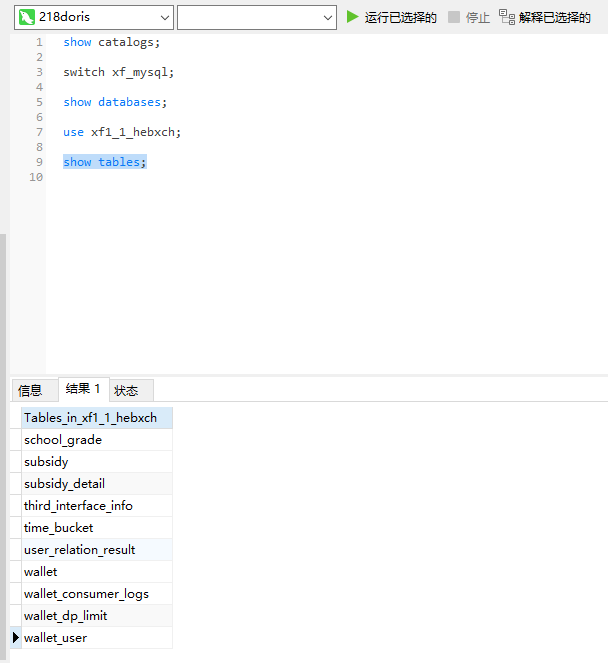
5)查询wallet_consumer_logs表中的数据
select count(*) from `xf_mysql`.`xf1_1_hebxch`.`wallet_consumer_logs`;
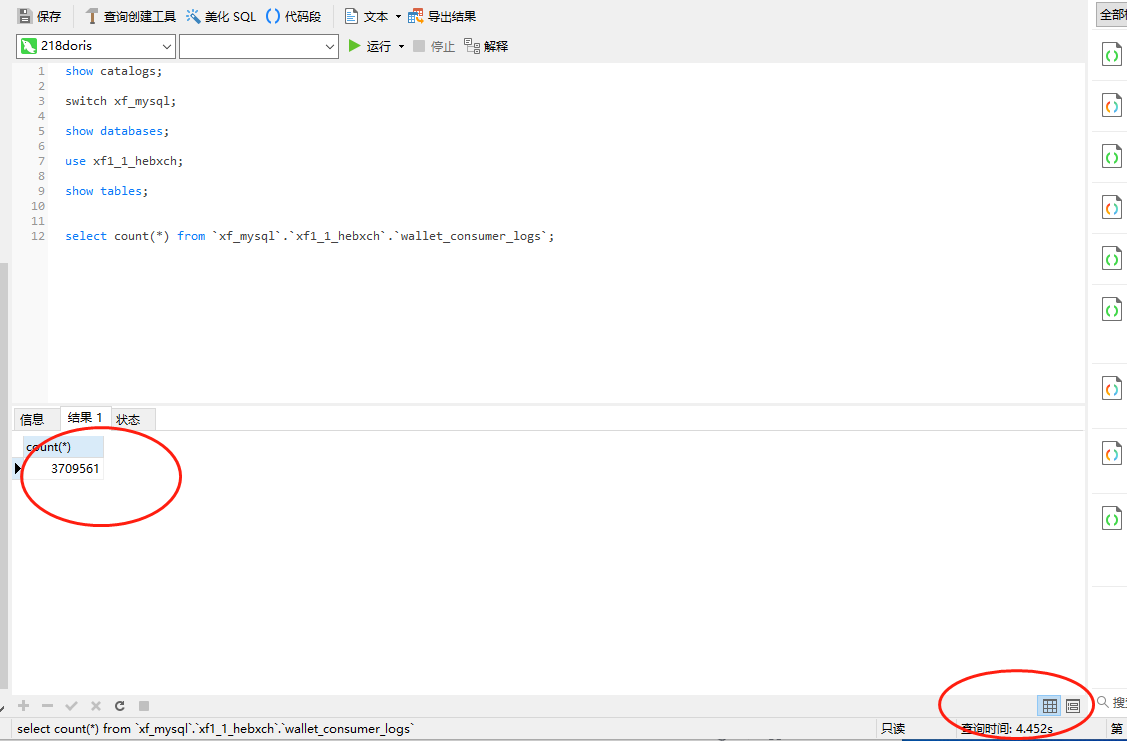
可以看到这里我们直接使用doris查询出来了mysql里面的数据,并且这里查询的时间也是4到5秒,和直接使用mysql进行查询的效率是一样的。查询非常慢。这是因为当前的数据还是在mysql里面,并且mysql算作是doris的外部表,这里doris也只是根据jdbc来进行查询的。
思考方案
到上面为止,我们已经完成了doris中创建mysql的数据湖的操作,此时我们查询数据那么慢,看起来用不用doris都没啥区别是吧?其实不是的,这里我们到目前为止还没有使用到doris的存储和查询特性,所以基于这块的话,我们需要把数据导入到doris中,然后再直接从doris中进行查询,这才是我们想要的方案,因此这里我们需要在doris里面,基于doris的数据结构来创建一张wallet_consumer_logs表。
Doris创建表
这里的话我们就需要在doris中创建表了,这里我们在前面强调过,这里的优化方案是把mysql的数据同步到ods层。
补充说明:
在数仓建设的时候,一般我们原始数据都是同步到ods贴源层的,这里的贴源层几乎和原始数据保持的一模一样。
所以我们需要把mysql创建表的语句转换成doris中创建表的语句。在创建语句之前,我们再思考一下:
1、使用doris的话,我们肯定是要分区的,这里我们分区应该怎么来分呢? 2、doris还有分桶的概念,分桶我们又怎么做呢? 3、这里我们选择doris3个模型里面的哪一个呢?
基于上面3点,我们来思考一下:
1、在这个场景里面是每天会生成很多数据量,那么我们的分区肯定以时间来进行分区对吧?所以这里我们选择天来分区。(这里由于是线下数据演示,所以这里我们按天来进行分区,生产环境中由于机器的配置比较高,同时使集群的环境,所以生产上我们使用的是以月为单位来进行分区)。
2、分桶,这里分桶的话由于业务不一样,涉及到消费,退款等类型,也就是原表中的op_type字段,在实际的业务中有根据这块进行统计的,因此我们决定使用op_type这个字段来进行分桶。
3、选择模型,一般ods贴源层的模型我们99%的选择都是unique模型,这样是为了保证同步过来的数据的准确性。
基于上面的3点思考,我们最后拟订出来的创建表的sql语句如下:
CREATE TABLE `wallet_consumer_logs` ( `id` bigint(19) NOT NULL, `create_time` datetime DEFAULT NULL COMMENT '创建时间', `op_type` tinyint(1) DEFAULT NULL COMMENT '1:充值;2:减款;3:消费;4:补贴;5:退款;6补扣;7余额清理', `order_no` varchar(63) DEFAULT NULL COMMENT '流水号', `branch_id` bigint(19) DEFAULT NULL COMMENT '校区id', `dept_id` bigint(19) DEFAULT NULL COMMENT '部门id', `user_relation_id` varchar(57) DEFAULT NULL COMMENT '消费者用户id 云校园 用户表字段', `transaction_id` varchar(120) DEFAULT NULL COMMENT '第三方支付流水号', `time_bucket_id` bigint(19) DEFAULT NULL COMMENT '时间段id', `device_id` bigint(19) DEFAULT NULL COMMENT '设备id', `costs_consume_log_id` bigint(19) DEFAULT NULL COMMENT '消费机消费记录id', `wallet_user_id` bigint(19) DEFAULT NULL COMMENT '用户钱包id', `wallet_type` int(11) DEFAULT NULL COMMENT '钱包类型,0:余额钱包,1、补贴钱包', `wallet_user_balance` decimal(10,2) DEFAULT NULL COMMENT '扣款前的余额', `op_user` varchar(90) DEFAULT NULL COMMENT '操作用户', `amount` decimal(10,2) DEFAULT NULL COMMENT '本次操作金额', `remark` varchar(765) DEFAULT NULL COMMENT '备注', `update_time` datetime DEFAULT NULL COMMENT '更新时间', `school_id` bigint(19) DEFAULT NULL COMMENT '学校id' ) ENGINE=OLAP UNIQUE KEY(`id`,`create_time`,`op_type`) PARTITION BY RANGE(`create_time`) ( ) DISTRIBUTED BY HASH(`op_type`) BUCKETS 8 PROPERTIES ( "replication_num" = "1", "dynamic_partition.replication_allocation" = "tag.location.default: 1", "dynamic_partition.enable" = "true", "dynamic_partition.time_unit" = "DAY", "dynamic_partition.end" = "5", "dynamic_partition.prefix" = "p", "dynamic_partition.buckets" = "8" )
对于这个sql的说明如下:
1、我们调整了字段的位置。 2、这里使用了动态分区的概念,这样子所有的分区都不需要我们手动来执行,他会自动创建分区。 3、buckets我们一般使用双数来定义
这里我们创建一下:
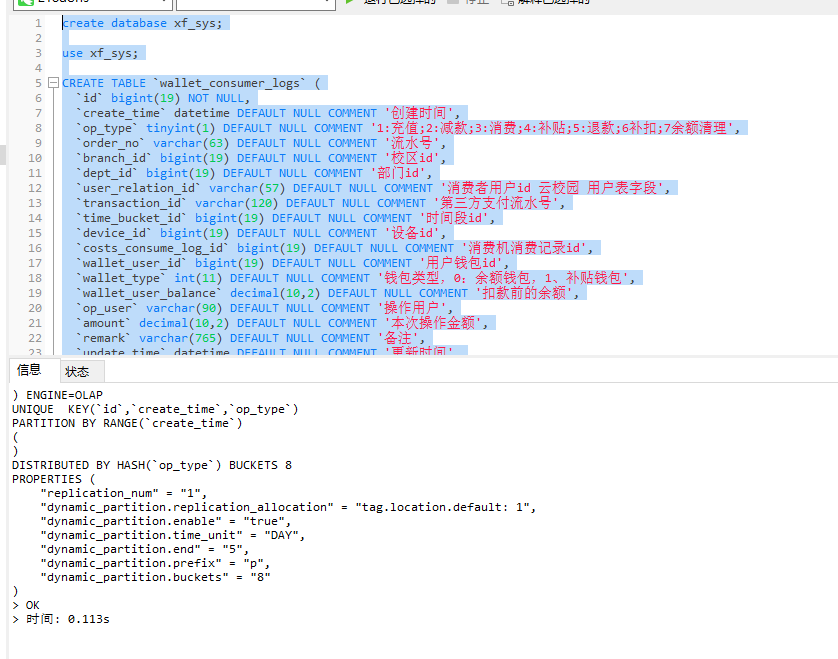
此时我们的doris中就创建好了这张表:
缺陷
前面我们使用自动分区的方式在doris中创建了wallet_onsumer_logs这张表,此时我们看看他创建的分区:
show partitions from wallet_consumer_logs;
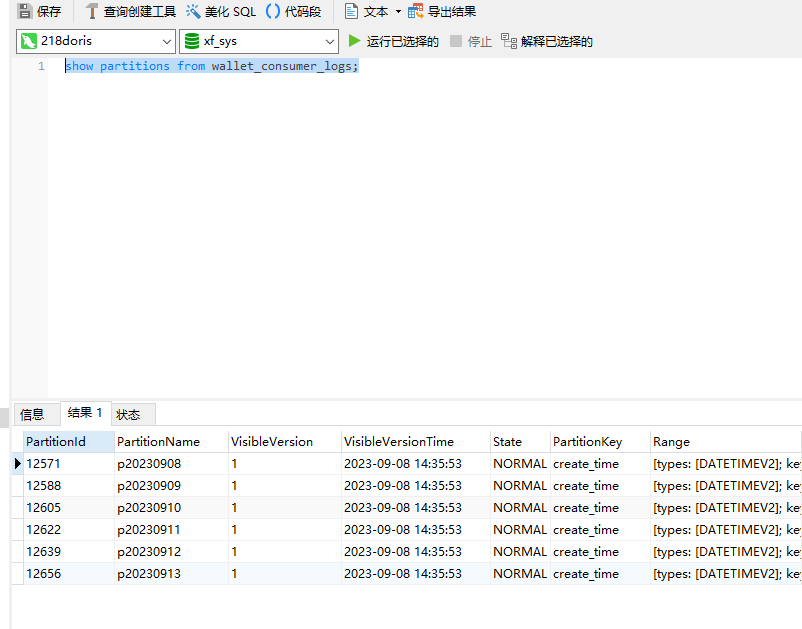
可以看到这里目前创建的分区值9月份的,但是mysql中的数据确实8月份的:
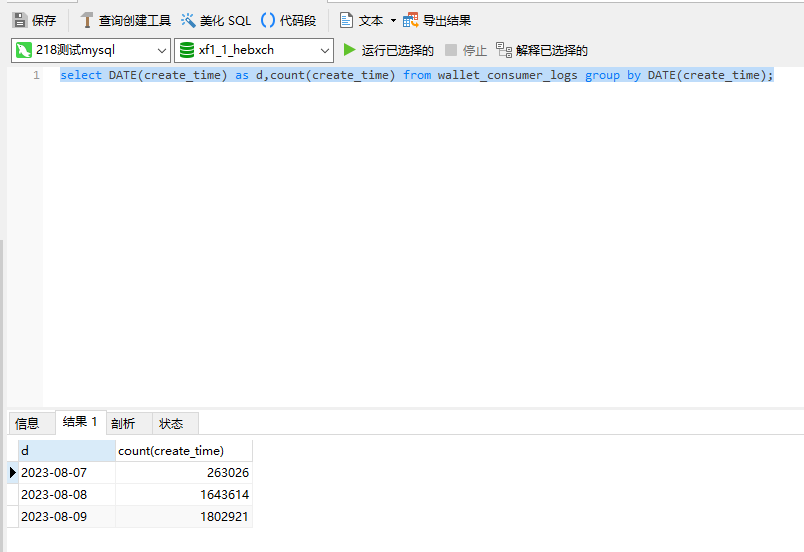
所以此时我们把数据导入到这个动态表里面的时候,就导入不进来,因为没有找到对应的分区,那此时怎么解决呢?我们需要手动的添加这3个日期的分区:
#暂停动态分区
ALTER TABLE `wallet_consumer_logs` SET ("dynamic_partition.enable" = "false");
#添加新的分区
ALTER TABLE `wallet_consumer_logs` ADD PARTITION p20230807 VALUES LESS THAN("2023-08-08 00:00:00");
ALTER TABLE `wallet_consumer_logs` ADD PARTITION p20230808 VALUES LESS THAN("2023-08-09 00:00:00");
ALTER TABLE `wallet_consumer_logs` ADD PARTITION p20230809 VALUES LESS THAN("2023-08-10 00:00:00");
#恢复动态分区
ALTER TABLE `wallet_consumer_logs` SET ("dynamic_partition.enable" = "true");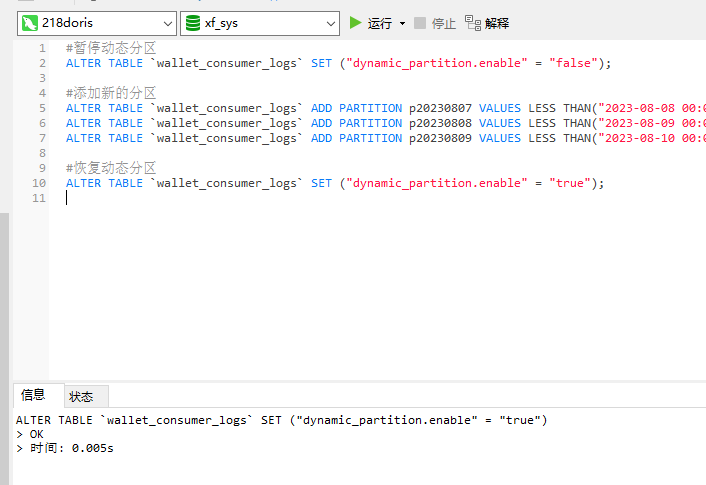
执行完毕之后,我们再看看这个wallet_consumer_logs表的分区:
show partitions from wallet_consumer_logs;
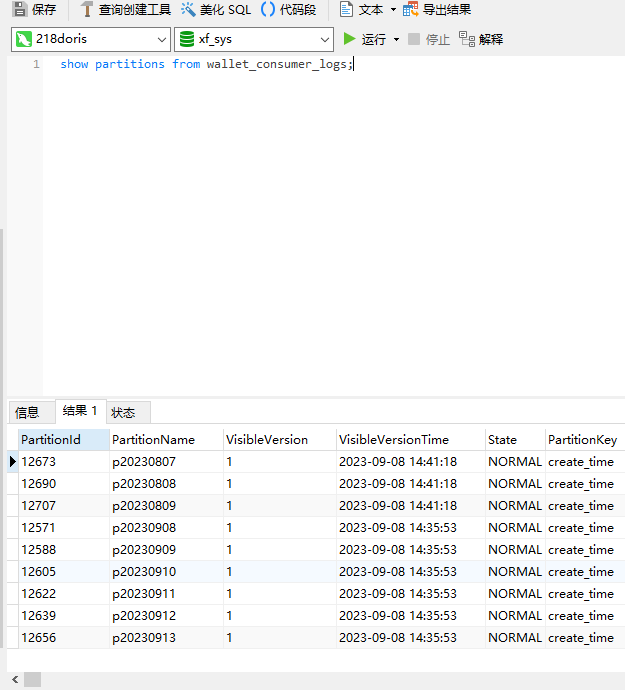
可以看到我们8月份的分区就创建好了。
导入数据
接着我们就需要从catalog中把mysql的数据导入到doris中的wallet_consumer_logs的表中了:
insert into internal.xf_sys.wallet_consumer_logs select `id`,`create_time`,`op_type`,`order_no`,`branch_id`,`dept_id`,`user_relation_id`,`transaction_id`,`time_bucket_id`,`device_id`,`costs_consume_log_id`,`wallet_user_id`,`wallet_type`,`wallet_user_balance`,`op_user`,`amount`,`remark`,`update_time`,`school_id` from xf_mysql.xf1_1_hebxch.wallet_consumer_logs;
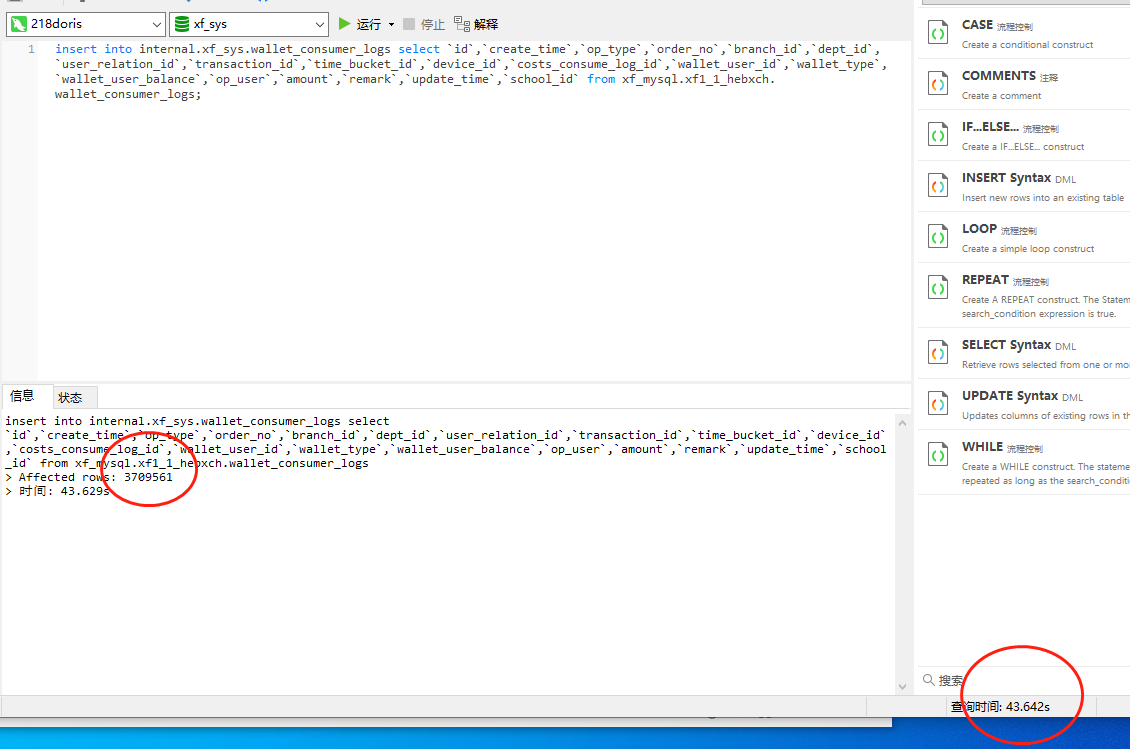
可以看到这里300多W的数据,40多秒就导入进来了,此时我们就可以在doris中查询导入到doris的wallet_consumer_logs表中的数据了,示例如下:
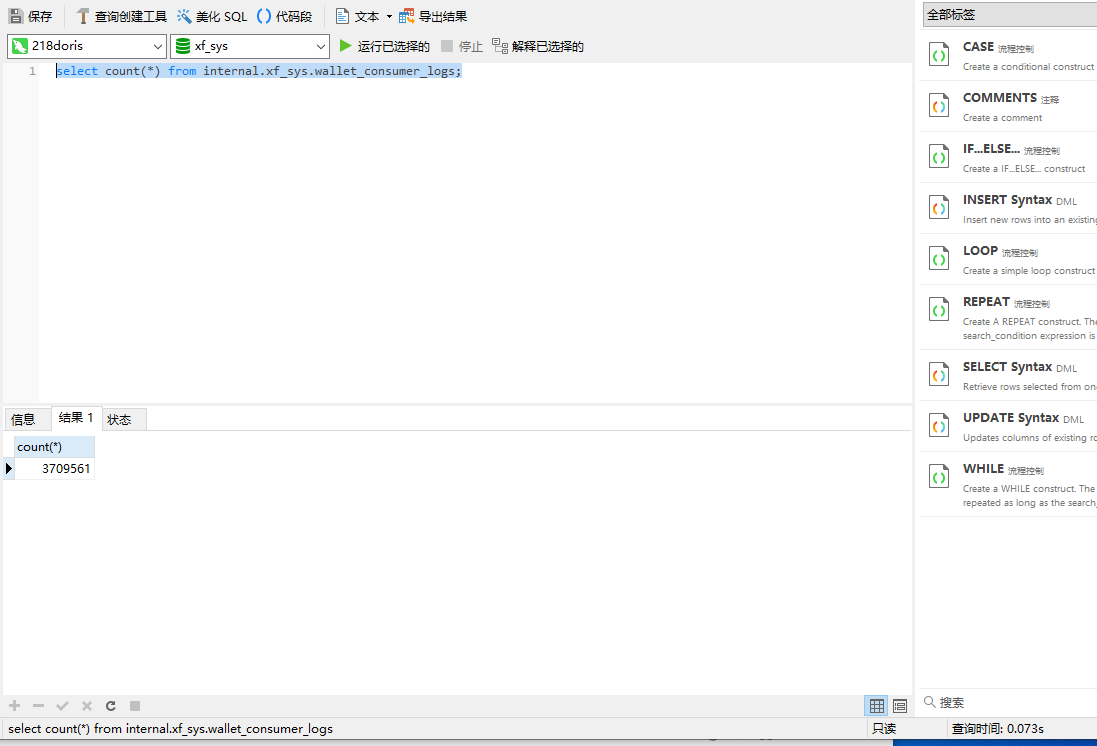
这里我们可以看到还是查询count,在mysql中我们需要4到5秒的执行时间,但是在doris中只需要0.073秒,这效率的提升是不是很快。下面我们再来几个sql查询的对比图:
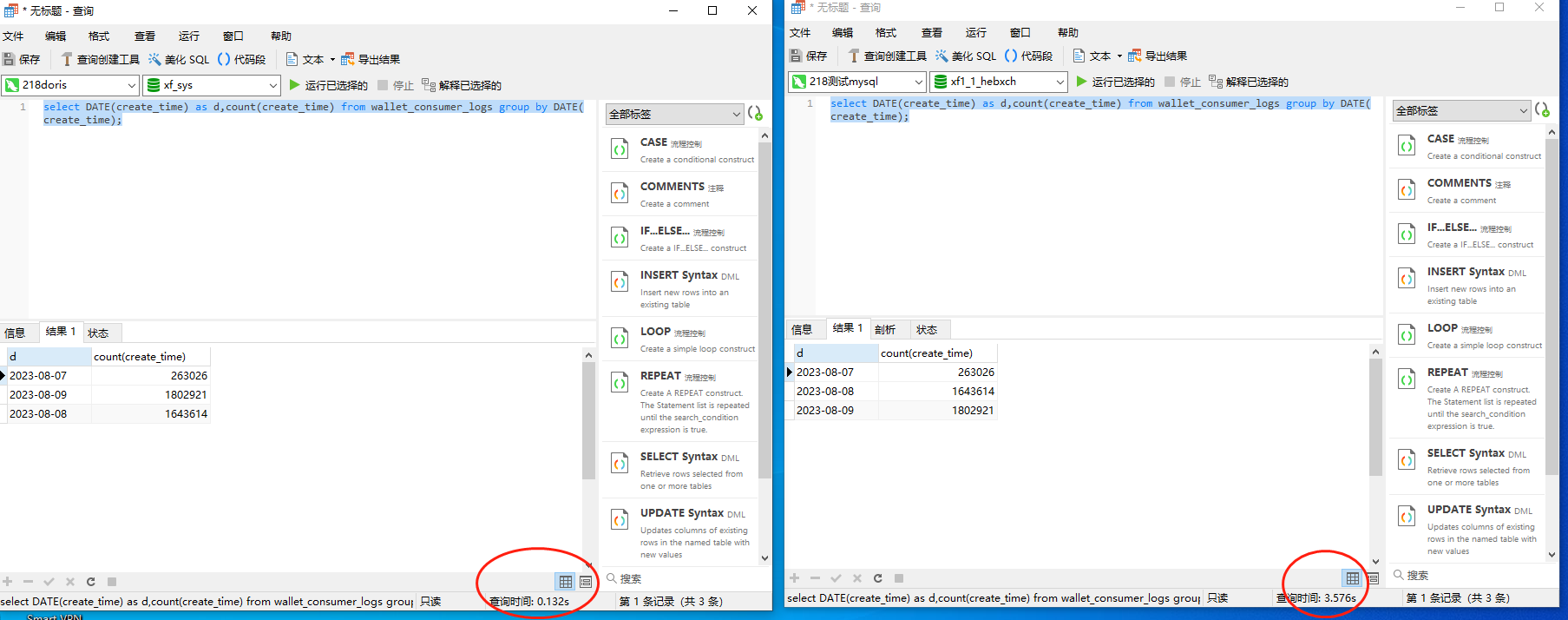
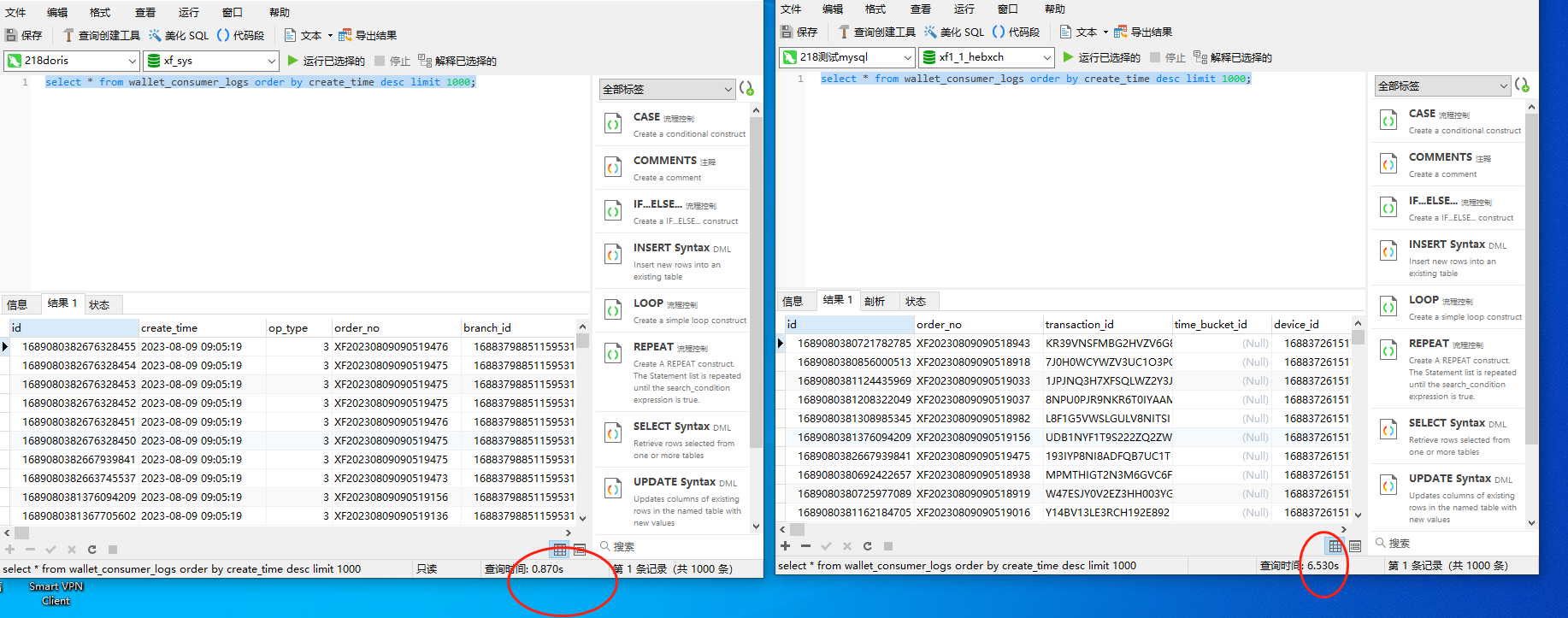
以上就是我们演示从catalog把数据导入到doris中,并且可以看到明显的数据查询提升效果。
备注:
1、这里由于团队规模比较小,所以我们使简单操作,使用catalog来演示数据导入,在真实的环境中还会搭配DolphinScheduler来使用。
2、如果团队规模比较大的话,我们一般还是会采用flink-cdc的方式来导入数据。
3、对于导入数据的方案来说,一般根据实际情况来进行导入,这里我们使用catalog来导入的话有延迟,这是业务可以容许的。用flink-cdc会更近实时一些。








还没有评论,来说两句吧...