
从本篇文章开始,我们接下来会介绍各种导入数据的方式,本篇介绍使用StreamLoad方式导入本地数据。
本篇使用的核心其实主要是通过doris提供的http接口进行导入数据。具体对应的节点和端口如下:
1、fe节点提供的http端口主要是8030端口 2、be节点提供的http端口主要是8040端口
下面我们完整的演示一下:
1、在doris中创建一张表
CREATE TABLE `user` ( `id` int(11) NULL COMMENT "学生id", `name` varchar(50) NULL COMMENT "学生姓名", `age` tinyint(4) NULL COMMENT "学生年龄" ) ENGINE=OLAP DUPLICATE KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" );
2、创建一份测试数据
这里的测试数据我们使用csv的格式,例如创建users.txt,具体内容如下:
1,zhangsan,25 2,lisi,26 3,wangwu,27
3、使用本地命令进行导入
使用的具体命令是:
curl --location-trusted -u root:123456 -T D:\\aaa\\users.txt -H "label:loaduser" -H "column_separator:," -XPUT http://1.13.179.82:8040/api/test/user/_stream_load
当出现如下界面的时候,就代表数据被导入了。
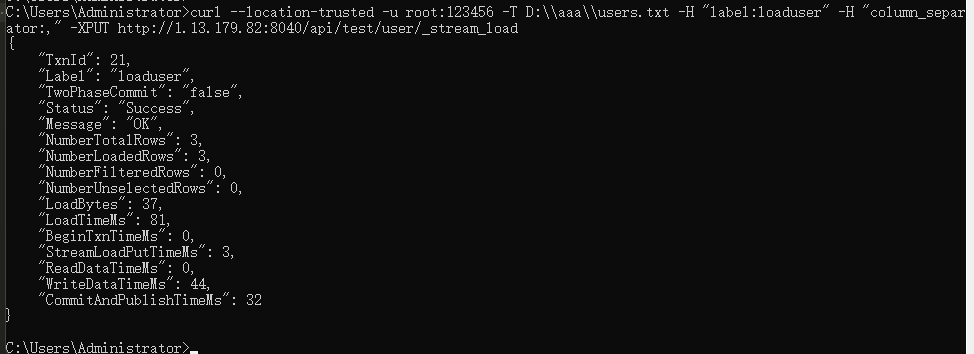
然后我们查看下数据库的数据
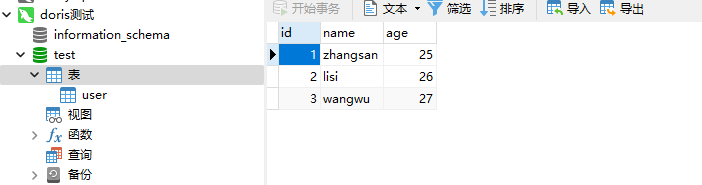
数据已经进来了。下面分别介绍下上面的命令:
1)-u root:123456
这里代表的是doris的登录用户和登录密码。并且当前账户需要对对应的库表有权限。
2)-T D:\\aaa\\users.txt
这里代表的是本地的文件路径
3)-H "label:loaduser"
这里相当于给此次导入添加一个标签,所有的导入都需要一个唯一的标签,不能出现重复,如果出现重复,则会直接报错
4)-H "column_separator:,"
这里指的是文件的分隔符是逗号,因为txt文件里面需要进行分割
5)-XPUT http://1.13.179.82:8040/api/test/user/_stream_load
这里是对应的服务器端的库表,此处的test是库,user是test库里面的表。8040是be节点提供的端口。
备注:
1、使用StreamLoad导入本地数据的时候,需要文件可以在执行curl的服务器上能被访问到。
2、使用StreamLoad导入本地数据的时候,一定要记得添加文件的每一行的分隔符。
3、使用StreamLoad导入本地数据的时候,如果出现错误,会直接返回一个json,里面有对应的ErrorMessage提示或者ErrorURL显示错误的信息,例如:
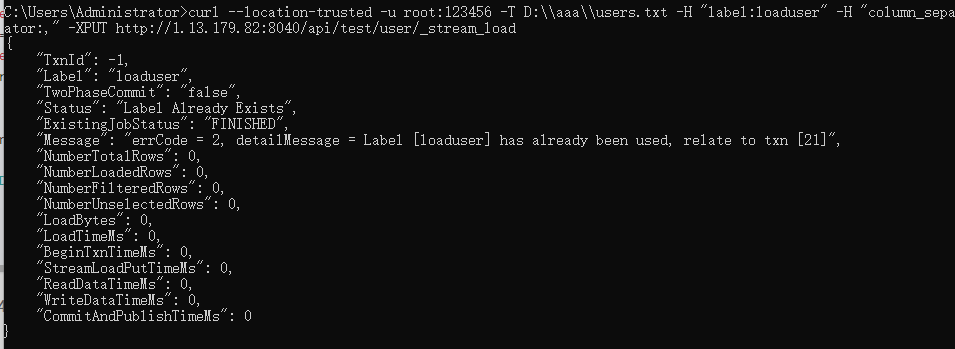
上图是显示错误的信息
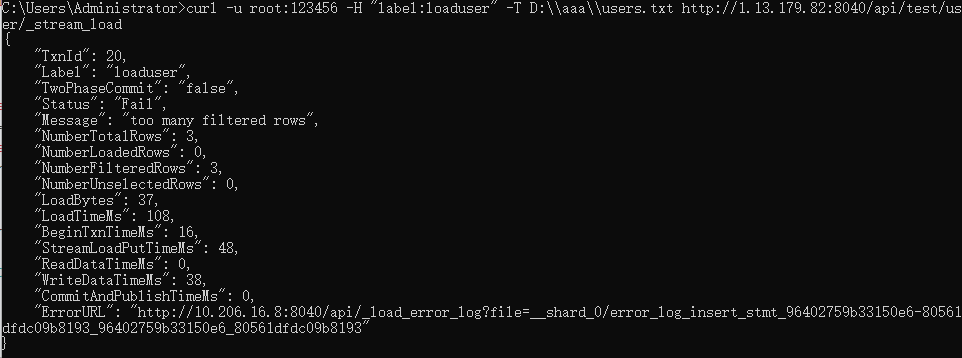
上图是显示对应的错误页面,访问这个地址即可看到对应的错误信息
4、使用StreamLoad导入本地数据的时候,如果数据量较大,则等待的时间较长。但是此方式导入数据的速度还是非常快的。
5、使用StreamLoad导入本地数据的实现方式有如下几种:
1、使用doris的dashboard里面的dataimport模块进行可视化填写导入 2、使用curl命令的方式进行导入 3、程序编写代码,执行http请求导入数据
以上三种方式的实现最终都是通过http的方式进行数据导入。
备注:
1、使用streamload方式导入数据的话,doris每次会生成一个数据文件,然后再后期compaction的时候再进行小文件的合并和数据的排序。同时删除掉旧版的数据








还没有评论,来说两句吧...