
上一篇我们介绍了使用StreamLoad导入本地的数据,这篇文章我们介绍下使用HdfsLoad导入hadoop中的数据。下面直接开始演示:
一、在doris中创建一张表
CREATE TABLE `user` ( `id` int(11) NULL COMMENT "学生id", `name` varchar(50) NULL COMMENT "学生姓名", `age` tinyint(4) NULL COMMENT "学生年龄" ) ENGINE=OLAP DUPLICATE KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" );
这里可以看出我们还是使用的之前文章演示使用的user表
二、制作数据,编写一个文本txt类型的数据
例如:users.txt,内容如下:
4,zhaoliu,20 5,tianqi,21 6,wangba,22
三、把这个文件上传到hdfs的路径下
hadoop使用的上传命令如下:
/usr/local/hadoop-2.6.0/bin/hadoop dfs -put /mnt/users.txt /users.txt
此时我们去下具体的文件信息
/usr/local/hadoop-2.6.0/bin/hadoop dfs -cat /users.txt
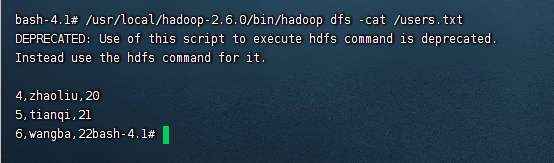
说明文件已经上传上去了,可以看到具体的内容和我们上面的TXT内容是一致的。
四、添加导入hdfs的sql语句
在doris中执行如下的命令
LOAD LABEL test.label_hdfsusers
(
DATA INFILE("hdfs://10.206.16.8:59000/users.txt")
INTO TABLE `user`
COLUMNS TERMINATED BY ","
(id,name,age)
)
with HDFS (
"fs.defaultFS"="hdfs://10.206.16.8:59000",
"hadoop.username"="root"
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);此时我们去数据库查看下数据是否被导入了。
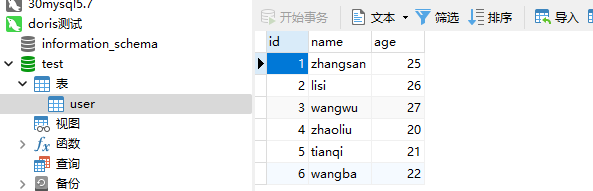
上诉4,5,6的数据都被导入进来了。
如果数据量比较大,那么导入时间会比较长,我们可以使用如下命令查看进度:
show load order by createtime desc;
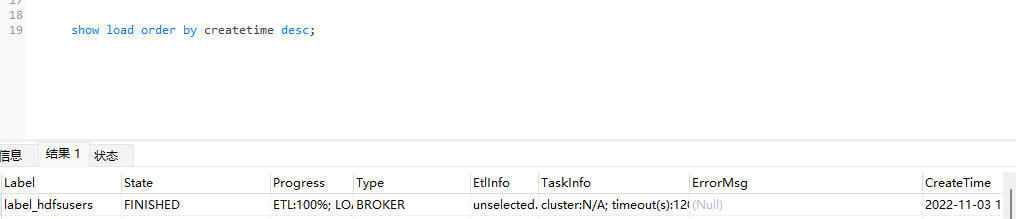
有时候我们一直看不到数据,我们也可以使用此命令查看下是否导入出现了问题,例如:

此时会在ErrorMsg里面显示具体的错误信息,根据错误信息进行修改即可。








还没有评论,来说两句吧...