
在上一篇文章我们介绍了使用HdfsLoad的方式导入hdfs中的数据,这篇文章我们介绍下使用BrokerLoad的方式导入hdfs中的数据。
BrokerLoad导入数据的方式和hdfsLoad导入数据的方式都差不多,主要还是导入hdfs中的数据。使用BrokerLoad导入数据的话,需要在服务器上启动Broker的进程。下面实战演示下。
一、在服务器上启动Broker的进程
具体的启动教程可以查看这篇文章《doris如何安装apache_hdfs_broker》。
二、在doris中创建表
这里我们还是使用之前创建的user表
CREATE TABLE `user` ( `id` int(11) NULL COMMENT "学生id", `name` varchar(50) NULL COMMENT "学生姓名", `age` tinyint(4) NULL COMMENT "学生年龄" ) ENGINE=OLAP DUPLICATE KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" );
三、制作一份测试数据:users.txt。内容如下
11,bailitusu,22 12,fengqingxue,23 13,ouyangshaogong,24
四、把文件上传到hdfs中
cd /usr/local/hadoop-2.6.0/bin/ ./hadoop dfs -ls / ./hadoop dfs -rmr /users.txt ./hadoop dfs -put /mnt/users.txt /users.txt ./hadoop dfs -cat /users.txt
如图:
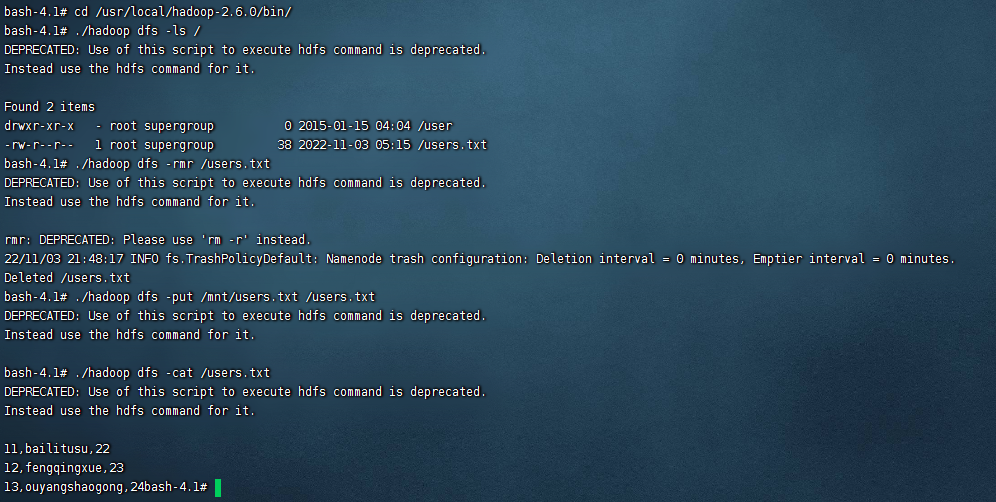
可以看到最新的文件已经上传上去了。
五、使用navicat进入到doris中
使用broker命令导入
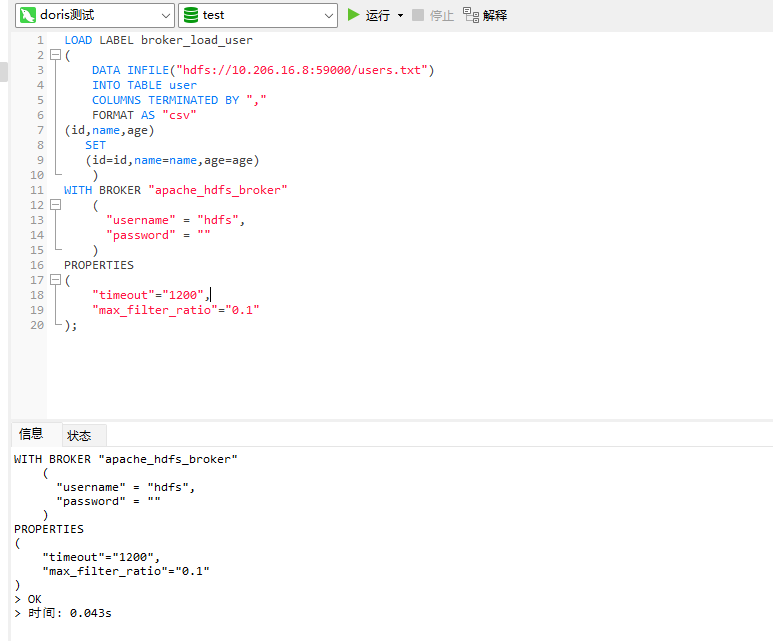
LOAD LABEL broker_load_user
(
DATA INFILE("hdfs://10.206.16.8:59000/users.txt")
INTO TABLE user
COLUMNS TERMINATED BY ","
FORMAT AS "csv"
(id,name,age)
SET
(id=id,name=name,age=age)
)
WITH BROKER "apache_hdfs_broker"
(
"username" = "hdfs",
"password" = ""
)
PROPERTIES
(
"timeout"="1200",
"max_filter_ratio"="0.1"
);
此时我们可以看到命令被正确执行了,然后我们去刷新下数据
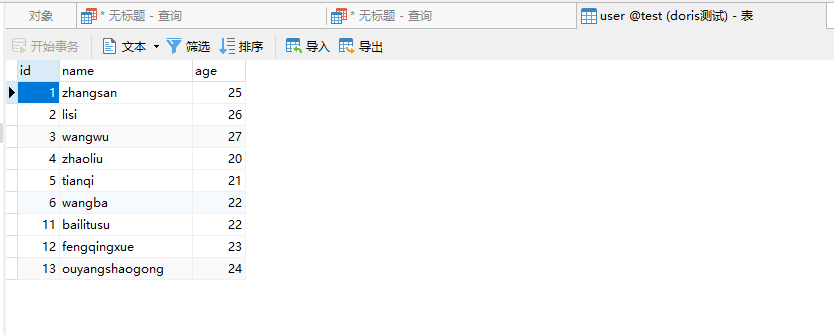
数据也进来了,说明导入是成功的。
这里我们解释下上面的sql的各个参数:
1)DATA INFILE("hdfs://10.206.16.8:59000/users.txt")
这里主要是填写hdfs文件的访问地址,这里可以写单个文件,也可以填写某个目录。
2)INTO TABLE user
代表的是插入到user这张表,一般我们还可以写成${库名}.${表名},例如:test.user
3)COLUMNS TERMINATED BY ","
当前文件每一行的分隔符是逗号分隔
4)FORMAT AS "csv" (id,name,age)
当前我们传的是单个文件,逗号分隔,所以我们格式填写csv,如果是导入hive这样的数据的话,我们可以写orc。这里支持的格式如下:
Parquet,ORC,csv,gzip
一般csv和ORC使用是最多的。
同时括号里面需要给每一个分隔的字段定义一个字段名
5)SET (id=id,name=name,age=age))
这里主要是使用上面第4步的自定义字段名和user表里面的字段名建立映射关系。
6)WITH BROKER "apache_hdfs_broker"
这个brokername需要填写实际doris集群里面部署的broker的名称,不能自定义,这个名称怎么看呢?直接执行如下命令:
show proc "/brokers";
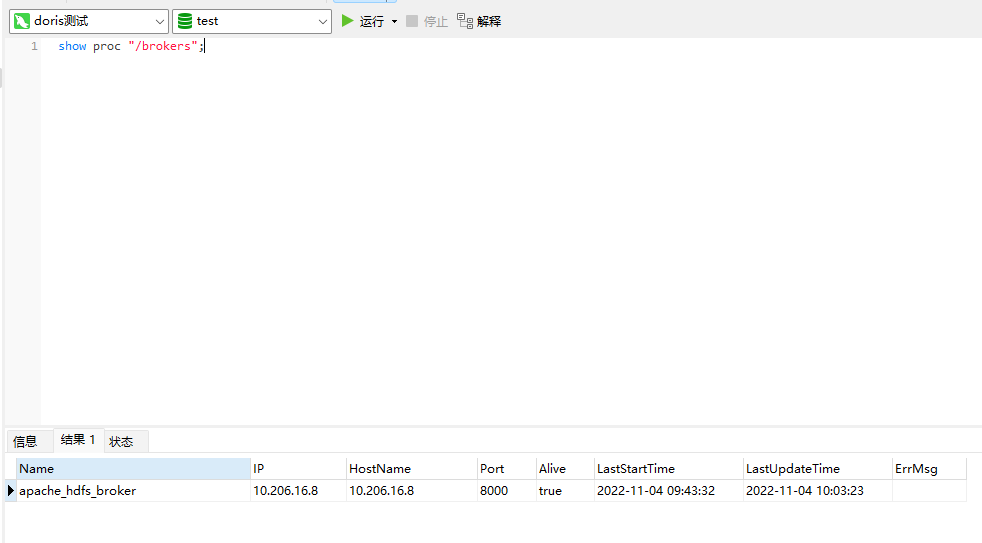
执行完毕后可以看到这里的name。
7)( "username" = "hdfs", "password" = "" )
这里主要是填写hdfs的访问认证信息,如果没有单独设置授权信息,那么写死上面的配置即可。
最后,如果hdfs文件较大的话,一般导入需要一段时间,此时我们可以根据如下的命令查看相关的进度:
show load order by createtime desc limit 1
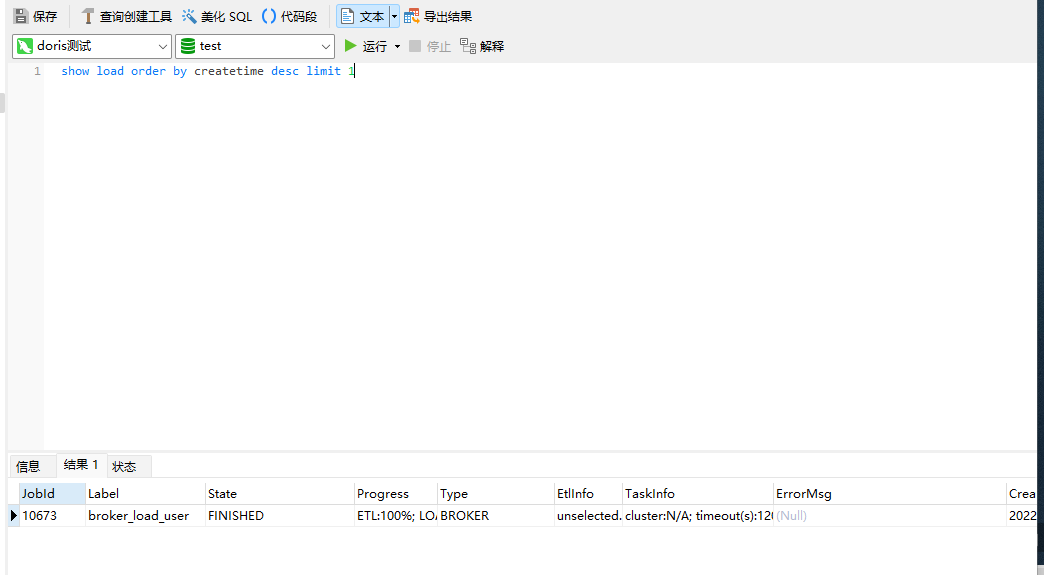
当然如果导入出现错误的话,也可以使用此命令进行查看报错信息,并且对相关的配置进行修改。
备注:
1、使用broker导入和hdfs导入从效果上看都差不多,目前我们建议使用broker的方式进行导入。
2、使用broker导入是异步的导入,非同步导入。
3、使用broker的方式导入一般都是数据量达到几十GB及以上,比较适合大数据量的导入。
4、使用broker导入的时候,会涉及到所有be的联动工作,因为doris中表是进行排序的。所以这个导入任务会被多个BE进行执行。增加集群的压力。
5、如果不想要增加集群的压力的恶化,可以考虑spark的方式导入。
关于broker导入性能说明
1、关于broker导入的默认配置
在broker导入的配置中,默认有如下配置:
参数名:min_bytes_per_broker_scanner, 默认 64MB,单位bytes。 参数名:max_broker_concurrency, 默认 10。 参数名:max_bytes_per_broker_scanner,默认 3G,单位bytes。
这几个参数是什么意思呢?
min_bytes_per_broker_scanner:代表单个BE处理的数据量的最小值
max_broker_concurrency:代表单个BE处理的数据量的最小值
max_bytes_per_broker_scanner:限制一个作业最大的导入并发数。
备注:上诉几个3个配置虽然属于broker的配置,但是他缺不是在broker的安装包配置文件里面配置,而是在fe.conf里面进行配置的。
2、举个例子说明导入数据流的问题。
1、假设现在有3个BE节点组成的doris集群,因此这边导入的数据量默认是3*3G=9G,因此如果当前导入的数据量是9G以下,可以使用broker创建一个作业任务。
2、如果当前导入的数据是10G,也是3个节点的doris集群,那么此时我们需要修改doris的broker配置信息才可以创建任务导入。修改公式如下:
max_broker_concurrency = BE 个数 当前导入任务单个 BE 处理的数据量 = 原始文件大小 / max_broker_concurrency max_bytes_per_broker_scanner >= 当前导入任务单个 BE 处理的数据量 比如一个 100G 的文件,集群的 BE 个数为 10 个 max_broker_concurrency = 10 max_bytes_per_broker_scanner >= 10G = 100G / 10
3、在超大型文件的导入里面,我们还需要调整这个timeout的时间,这个timeout时间的计算公式如下:
当前导入任务单个 BE 处理的数据量 / 用户 Doris 集群最慢导入速度(MB/s) >= 当前导入任务的 timeout 时间 >= 当前导入任务单个 BE 处理的数据量 / 10M/s 比如一个 100G 的文件,集群的 BE 个数为 10个 timeout >= 1000s = 10G / 10M/s
备注:如果根据上面的公式计算出超时时间需要大于4个小时(doris系统默认最大时间为4个小时),那么建议把文件进行切分后再导入。切分公式如下:
期望最大导入文件数据量 = 14400s * 10M/s * BE 个数 比如:集群的 BE 个数为 10个 期望最大导入文件数据量 = 14400s * 10M/s * 10 = 1440000M ≈ 1440G 注意:一般用户的环境可能达不到 10M/s 的速度,所以建议超过 500G 的文件都进行文件切分,再导入。








还没有评论,来说两句吧...