
在前面我们介绍了好几种doris的数据导入方式,本篇文章我们介绍下使用Kafka订阅的方式导入数据。
使用kafka订阅的方式导入数据主要是依靠doris的Routine Load功能。只要用户在doris中创建相关的job,doris就会自动对接到Kafka中,并且订阅某个topic的数据,用户只需要向kafka填写数据即可,数据就会以近实时的方式进行数据的同步。下面我们来演示下具体操作。
一、前提说明
doris订阅kafka的数据主要有两种方式,第一种是csv格式的数据,即每一行的数据以逗号进行分割,第二种是json格式的数据,每一行的数据是json格式的。
二、在服务器上安装一个kafka环境
这里我们已经安装好了,可以参考这篇文章《使用docker安装kafka》。
当前我们安装的kafka是没有配置用户认证访问权限,因此这里我们演示的主要是无kafka认证的kafka订阅。
三、在dori上创建user表
CREATE TABLE `user` ( `id` int(11) NULL COMMENT "学生id", `name` varchar(50) NULL COMMENT "学生姓名", `age` tinyint(4) NULL COMMENT "学生年龄" ) ENGINE=OLAP DUPLICATE KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2" );
这里我们还是使用之前的表,然后我们把数据清空掉。
四、创建一个Routine Load,使用csv格式
上面我们提到过doris可以订阅kafka中csv格式的数据,所以这里我们拟定订阅到kafka中,使用csv格式。
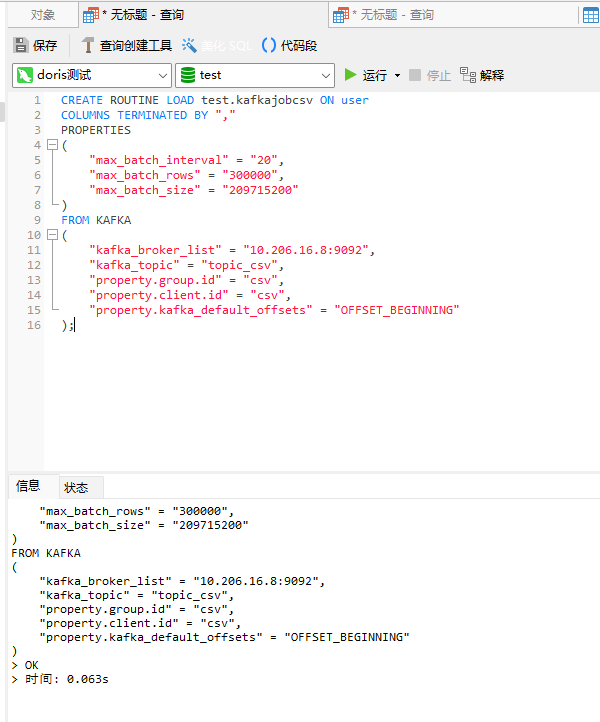
CREATE ROUTINE LOAD test.kafkajobcsv ON user COLUMNS TERMINATED BY "," PROPERTIES ( "max_batch_interval" = "20", "max_batch_rows" = "300000", "max_batch_size" = "209715200" ) FROM KAFKA ( "kafka_broker_list" = "10.206.16.8:9092", "kafka_topic" = "topic_csv", "property.group.id" = "csv", "property.client.id" = "csv", "property.kafka_default_offsets" = "OFFSET_BEGINNING" );
如图创建成功
此时我们进入到kafka里面去发送下数据
kafka-console-producer.sh --topic topic_csv --broker-list 10.206.16.8:9092 1,zhangsan,12
这里我们发送了一条数据,如图:

此时我们再去看看user表里面数据进来没有
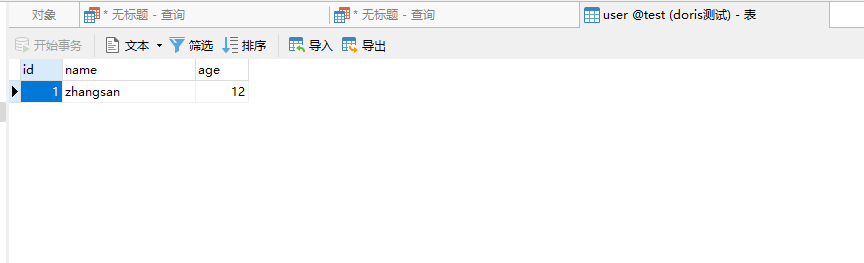
数据已经进来,没有任何问题。说明此次操作是成功的。
下面我们介绍下上面创建routineload的参数:
1)CREATE ROUTINE LOAD test.kafkajobcsv ON user
这里的test.kafkajobcsv 代表的是test这个库,后面的kafkajobcsv 是routineload的名称,on user代表的是test库里面的user表。
2)COLUMNS TERMINATED BY ","
这里我们说过在csv结构里面,使用的是逗号分隔,所以我们需要去定义分隔符。
3)PROPERTIES
这里主要配置的是一些匹配延迟参数,根据实际情况调整即可。
4)FROM KAFKA
主要填写kafka相关的一些连接配置信息。
四、创建一个Routine Load,使用json格式
CREATE ROUTINE LOAD test.kafkajobjson on user PROPERTIES ( "desired_concurrent_number"="1", "strict_mode"="false", "format" = "json" ) FROM KAFKA ( "kafka_broker_list"= "10.206.16.8:9092", "kafka_topic" = "topic_json", "property.group.id" = "json", "property.kafka_default_offsets" = "OFFSET_BEGINNING", "property.enable.auto.commit" = "true" );
如下图:
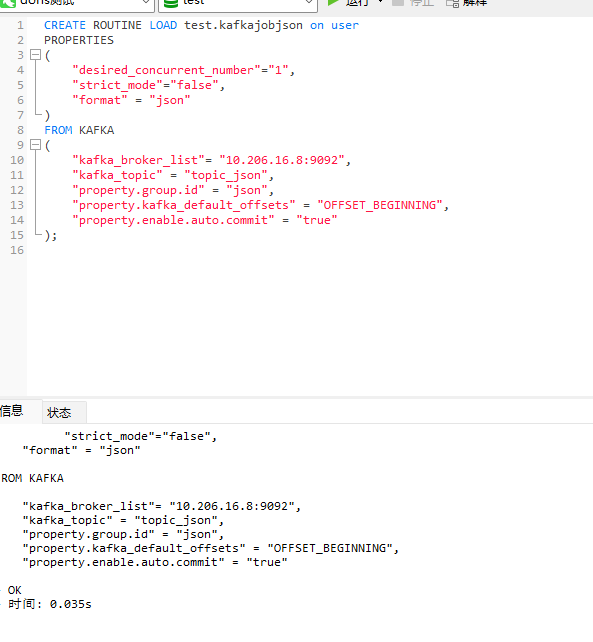
创建成功,再查看下routineload
show routine load;

然后我们去kafka里面发送下数据:
kafka-console-producer.sh --topic topic_json --broker-list 10.206.16.8:9092
{"id":2,"name":"lisi","age":10}此时我们发送一条json数据,然后去doris中看看数据
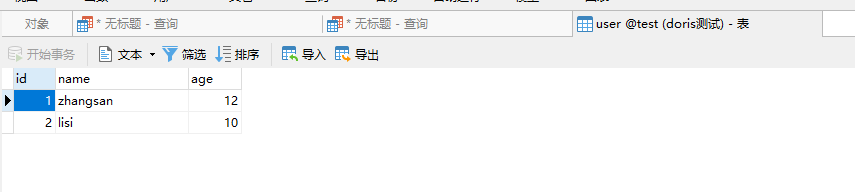
可以看到数据正确的进来了。
这里说下csv和json的区别:
1、kafka生产者生产的数据格式不一样。
2、创建routine load的时候需要显示指定分隔符或者json属性。
备注:
1、在创建Routine Load的时候,需要在kafka集群里面创建对应的topic,不然Routine Load的job会报错:no partition in this topic
2、routineload是创建再库上面的,也就是我们如果需要查看所有的routineload的时候,需要指定对应的库,而不是指定某张表,他可以查看当前库里面的所有routineload任务,不能单独只能查看某张表的routineload。
3、routineload是近实时的数据导入,这边导入数据非常快,在千万级别的数据流导入的话,几乎在秒级别就能导入完成。
4、订阅kafka的数据,如果数据量较多的话,doris不能马上查出相关的数据,可能需要稍等一会才能在doris中查询出最新的数据。
6、在使用kafka导入数据的时候,需要严格判断下生产者即将发送的数据,如果当前topic里面出现了脏数据或者错误的数据类型,那个这个routineload将会停止工作,当数据量较大时,很难及时发现。








还没有评论,来说两句吧...