
这篇文章我们介绍下Doris的Sequence列。这个列的作用主要是相当于给某张表的数据添加一个版本号。类似于我们在做分布式高并发的时候,会在数据库的表里面添加一个version的乐观锁字段。这样子每次插入的时候都需要带上一个版本。高版本会覆盖掉低版本的作用。
所以Sequeunce列可以看做是doris表中的乐观锁版本字段。然后我们在插入的时候会在源表里面添加一个这个字段,这样子版本号高的数据会覆盖掉版本号低的数据,但是版本号低的数据不会覆盖掉版本号高的数据。
doris中Sequeunce列目前数据类型只支持整型和时间类型(DATE,DATETIME)
下面我们来演示一下
一、首先创建一张user表
CREATE TABLE `user` ( `id` int(11) NOT NULL COMMENT "", `name` varchar(20) NULL COMMENT "姓名", `age` tinyint(4) NULL COMMENT "年龄", `version` int(11) not null comment '乐观锁版本号' ) ENGINE=OLAP UNIQUE KEY(`id`) COMMENT "OLAP" DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_allocation" = "tag.location.default: 1", "in_memory" = "false", "storage_format" = "V2", "function_column.sequence_type" = 'int' );
在创建表的时候,我们只需要在properties里面添加
"function_column.sequence_type" = 'int'
这列就可以了,这里可以是int,也可以是DATE或者是DATETIME。
这里的意思就是在本表里面开启使用Sequeunce列。
备注:
如果是以前的表,需要使用版本控制的话,则可以直接修改下表信息用来开启当前表支持Sequeunce列。修改sql示例如下:
ALTER TABLE example_db.my_table ENABLE FEATURE "SEQUENCE_LOAD" WITH PROPERTIES ("function_column.sequence_type" = "Date")二、制作一份user.txt的数据,使用stream load的方式导入
2.1、创建的users.txt
数据如下
1,zhangsan,25,1 2,lisi,26,1 3,wangwu,27,1
2.2、使用streamload的方式导入
curl --location-trusted -u root -T D:\\aaa\\users.txt -H "label:loaduser" -H "column_separator:," -H "function_column.sequence_col: version" -XPUT http://121.37.103.180:8040/api/demo/user/_stream_load
备注:
这里主要是在heade头里面添加一个指定那一列是Sequeunce列,这里我们的参数是:-H "function_column.sequence_col: version" 也就是指定version列为Sequeunce列
导入执行情况
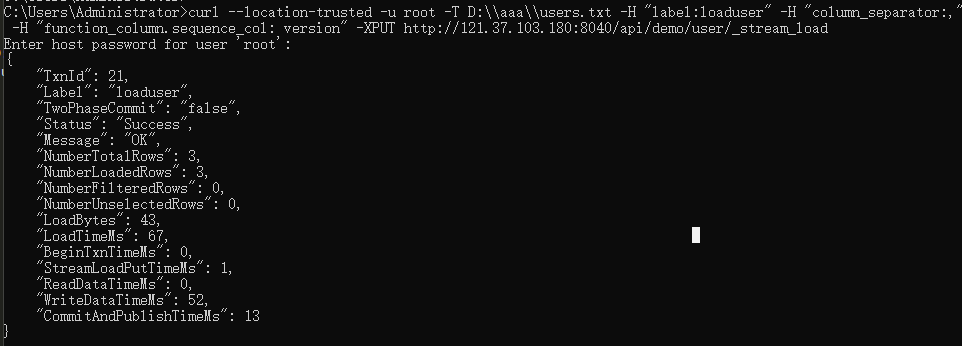
再看下数据进去没有
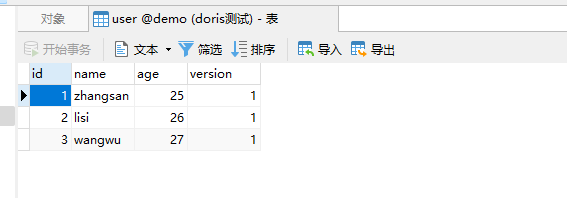
可以看到数据进来了,此时我们再修改下users.txt的数据,修改后如下:
1,wangwu,25,0 2,zhaoliu,26,2 3,tianqi,27,2
按照我们的理解,那么期望的情况就会是:id为1的数据不会变,name还是张三,id为2和3的数据会变成新的数据。
然后再执行下streamload,看下具体结果
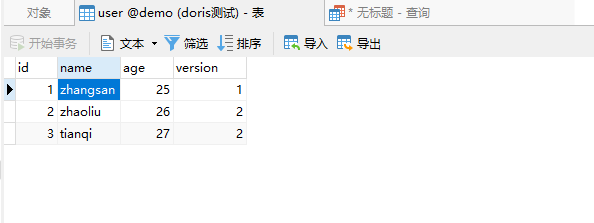
可以看到id为2和3的都变了,主要是id为1的版本号我们修改变成了0,因此这里他版本号低的不会覆盖掉版本号高的。
备注:
1、Sequeunce列可以看做是乐观锁的版本号。
2、Sequeunce列只能在Unique数据模型的表里面生效。
3、Sequeunce列在创建表的时候需要设置下properties,相当于为当前表声明下支持Sequeunce列。
4、Sequeunce列在导入数据的时候再进行映射Sequeunce列,doris会自动根据映射的列进行逻辑处理。
最后在说下各个导入方式如何指定Sequeunce列映射。
1、Streamload导入方式
在http header头里面指定Sequeunce列映射列即可。例如:
-H "function_column.sequence_col: version"
2、Brokerload导入方式
在load 元数据信息里面添加一个order by 列的说明,例如:
LOAD LABEL db1.label1
(
DATA INFILE("hdfs://host:port/user/data/*/test.txt")
INTO TABLE `tbl1`
COLUMNS TERMINATED BY ","
(k1,k2,source_sequence,v1,v2)
ORDER BY source_sequence
)
WITH BROKER 'broker'
(
"username"="user",
"password"="pass"
)
PROPERTIES
(
"timeout" = "3600"
);3、Routineload导入方式
也是添加order by列的说明,例如:
CREATE ROUTINE LOAD example_db.test1 ON example_tbl [WITH MERGE|APPEND|DELETE] COLUMNS(k1, k2, source_sequence, v1, v2), WHERE k1 > 100 and k2 like "%doris%" [ORDER BY source_sequence] PROPERTIES ( "desired_concurrent_number"="3", "max_batch_interval" = "20", "max_batch_rows" = "300000", "max_batch_size" = "209715200", "strict_mode" = "false" ) FROM KAFKA ( "kafka_broker_list" = "broker1:9092,broker2:9092,broker3:9092", "kafka_topic" = "my_topic", "kafka_partitions" = "0,1,2,3", "kafka_offsets" = "101,0,0,200" );








还没有评论,来说两句吧...