
在前面两篇文章《Dinky 实时计算平台系列(十九)FlinkSql作业开发之FlinkSql-Kafka》和《Dinky 实时计算平台系列(二十)FlinkSql作业开发之FlinkSql-cdc》。本文的话,我们结合下mysql的cdc和kafka来做一个完整的案例。
我们知道在flink中,对于流式的作业,整个job就会分为3大块,分别是source,func,sink,所以本文的话我们来演示下使用Dinky来操作整个job任务,我们模拟从mysql里面获取变更数据,然后把mysql cdc获取到的数据写入kafka里面。对于这个案例,下面直接开始:
1)首先安装驱动
这里会涉及到kafka和mysql cdc,因此需要安装驱动,具体的安装方法,可参考前面这两篇文章:《Dinky 实时计算平台系列(十九)FlinkSql作业开发之FlinkSql-Kafka》和《Dinky 实时计算平台系列(二十)FlinkSql作业开发之FlinkSql-cdc》。
2)测试下kafka的接收和发送信息
这里对于kafka的话,我们需要把数据写入kafka,所以本文的话,我们使用kafka的测试端来测试下kafka是否是通的,具体的测试可参考:《生产者测试》和《消费者测试》。这里我们测试没有问题,如下图:
生产者:

消费者:

以上kafka测试没有问题,我们就用这个user2这个topic来进行演示flink的job任务。
3)编写flinksql任务
我们进入到dinky平台的数据开发模块,然后创建一个名为test4的作业:
然后把下面的代码复制到作业里面去:
SET execution.checkpointing.interval = 3s; CREATE TABLE IF NOT EXISTS user1 ( id STRING, name STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'mysql-cdc', 'hostname' = '192.168.31.218', 'port' = '3306', 'username' = 'slave1', 'password' = 'slave1', 'database-name' = 'test', 'table-name' = 'users' ); CREATE TABLE user2 ( `id` STRING, `name` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'user2', 'properties.bootstrap.servers' = '192.168.31.218:9092', 'properties.group.id' = 'user-1', 'scan.startup.mode' = 'earliest-offset', 'format' = 'debezium-json', 'debezium-json.ignore-parse-errors'='true' ); insert into user2 select * from user1;
这里主要分为了4个func,分别是:
1、设置检查点 2、创建一个读取mysql的表 3、创建一个写入kafka的表 4、把读取的mysql表结果写入kafka
4)运行作业测试
这里的话,我们运行下整个table,进行测试一下:
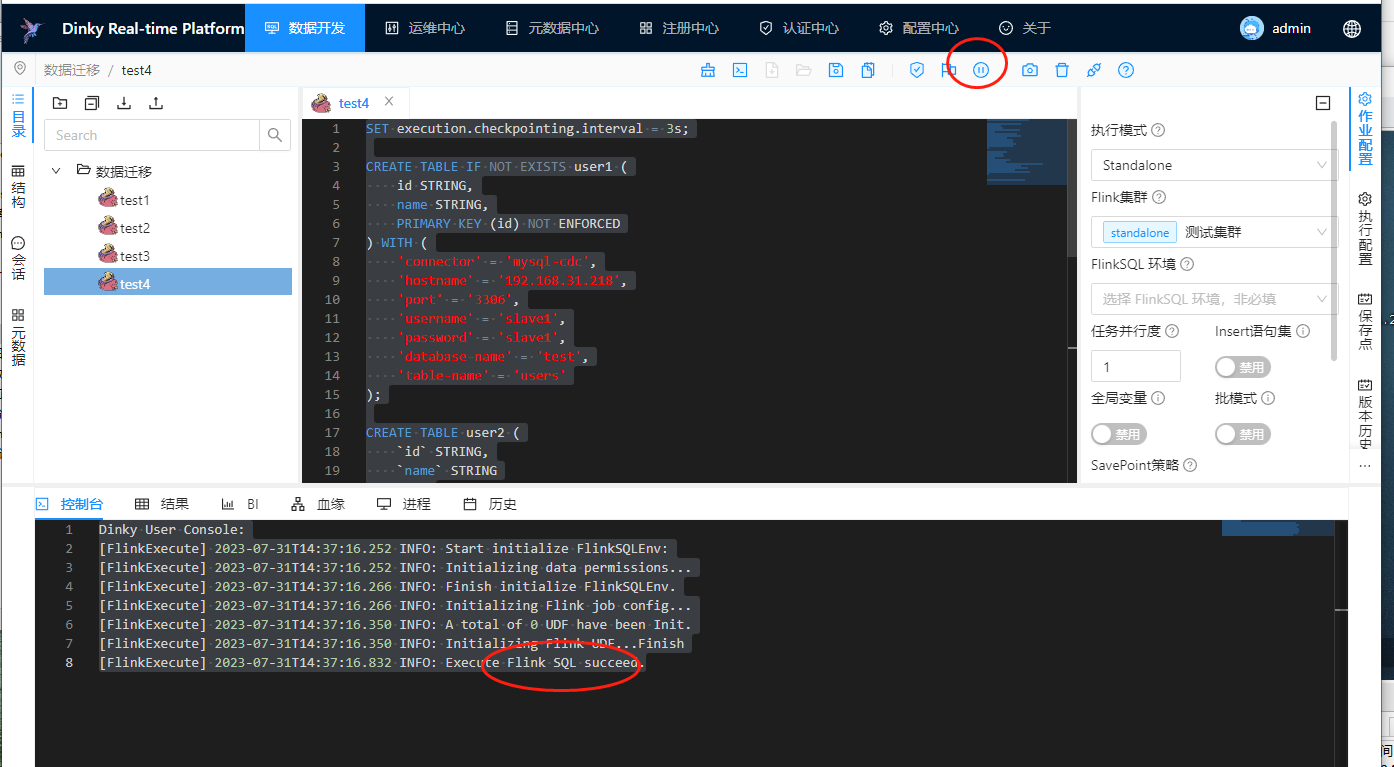
可以看到执行任务是成功的,然后我们去mysql数据库里面添加一条张七的数据:
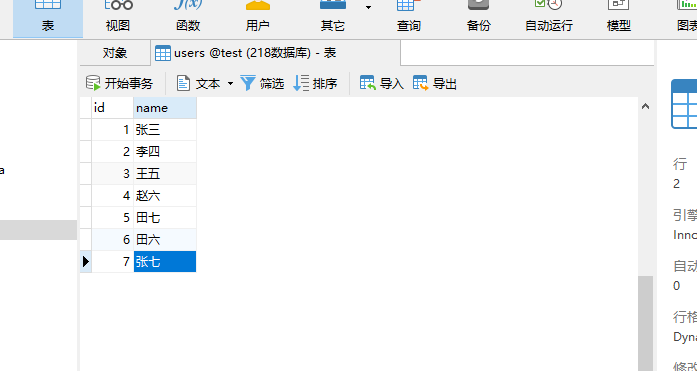
然后再看看kafka的消费者是否接收到了对应的数据:
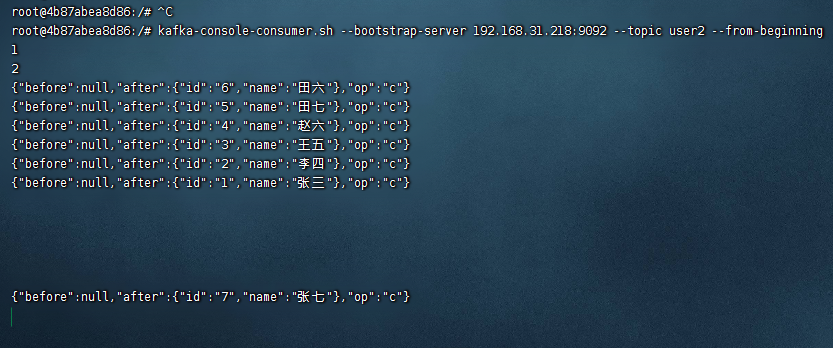
可以看到数据进入到了kafka上,整个job完美的运行了。
备注:
1、这里的job任务主要是为了掩饰使用dinky编写一个完整的flink-sql任务。 2、这里切记需要添加依赖。 3、所有的connector依赖,既可以做connector的连接器,也可以做sink的连接器。








还没有评论,来说两句吧...