
我们在使用flink 开发应用程序的时候,有时候会涉及到这样的一些应用场景:
假设从mq中获取到的数据里面只有用户id,没有用户的其他信息,但是我们的目的需要分析当前人的个人画像,那这个时候怎么办呢?
看上面的需求,我们从mq,也就是flink的source里面只能获取到当前的用户id,相当于前端告诉咱们,需要重新跑一下当前用户的个人画像。这时候从source里面只能拿到用户的id,没有用户其他的信息,那么这个时候我们就需要涉及到去数据库里面查询出来用户的当前个人信息。
在flink中,所有的richfunction都有一个open和close方法,我们可以在这里去初始化数据库连接等等信息,然后按照正常的流程执行。
此时我们就会有一个疑问了,这样子的话来一条数据就要去查询执行,属于同步信息,这里会涉及到大量的连接浪费时间,导致任务执行过慢。那有没有什么好的方法去执行呢,其实有的,就是本文介绍的异步I/O,也就是flink处理的时候正常处理flink的任务,需要去查数据库的话就用异步现成等待返回结果即可。这有点类似于java里面的feture。下面我们来演示一下:
1)创建一个异步function
这里的话,我们需要把查询数据库等的逻辑写入一个单独的异步function里面去。这里的function需要集成自RichAsyncFunction,下面我们列举下具体的代码示例:
package org.example.func;
import lombok.extern.slf4j.Slf4j;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.async.ResultFuture;
import org.apache.flink.streaming.api.functions.async.RichAsyncFunction;
import org.example.model.UserPoJo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.util.Arrays;
@Slf4j
public class UserAsync extends RichAsyncFunction<UserPoJo, UserPoJo> {
private Connection connection;
@Override
public void open(Configuration parameters) throws Exception {
this.initJdbc();
super.open(parameters);
}
/**
* 使用jdbc的方式初始化数据库连接段
*/
private void initJdbc() {
try {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://192.168.31.218:33306/school?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai";
//Connection接口 实际返回的mysql的实现类对象
connection = DriverManager.getConnection(url, "root", "123456");
} catch (Exception e) {
log.error(e.getMessage(), e);
}
}
@Override
public void asyncInvoke(UserPoJo user, ResultFuture<UserPoJo> resultFuture) throws Exception {
Integer userId = user.getUserId();
PreparedStatement preparedStatement = connection.prepareStatement("select name from users where id = ?");
preparedStatement.setInt(1, userId);
ResultSet resultSet = preparedStatement.executeQuery();
if (resultSet.next()) {
String name = resultSet.getString("name");
user.setUserName(name);
}
preparedStatement.close();
resultSet.close();
resultFuture.complete(Arrays.asList(user));
}
@Override
public void close() throws Exception {
if (null != connection) {
connection.close();
}
super.close();
}
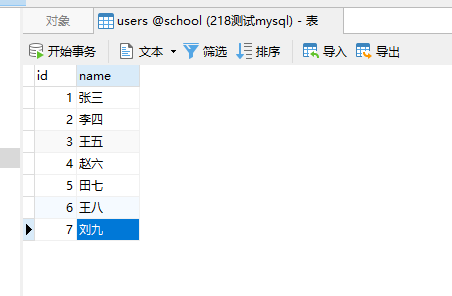
}可以看到这里我们在open方法里面创建了数据库连接,在close方法里面关闭了数据库连接,在asyncInvoke方法中执行具体的查询任务,这里我们的sql数据如下:
2)新建flink任务,添加source
这里我们的source简写了一下,直接从collection里面获取,示例代码如下:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); DataStreamSource<UserPoJo> sources = env.fromCollection(Arrays.asList(new UserPoJo(1), new UserPoJo(2), new UserPoJo(3), new UserPoJo(4), new UserPoJo(5), new UserPoJo(6), new UserPoJo(7) ));
3)使用AsyncDataStream执行异步任务
这里执行异步I/O的话,需要使用AsyncDataStreaml来执行对应的异步任务,同事需要设置异步等待结果的时间,示例代码如下:
SingleOutputStreamOperator<UserPoJo> streamOperator = AsyncDataStream.unorderedWait(sources, new UserAsync(), 1, TimeUnit.SECONDS);
4)输出结果
这里我们把结果打印出来,输出到控制台上去:
streamOperator.print();
这里我们运行一下,看看结果:
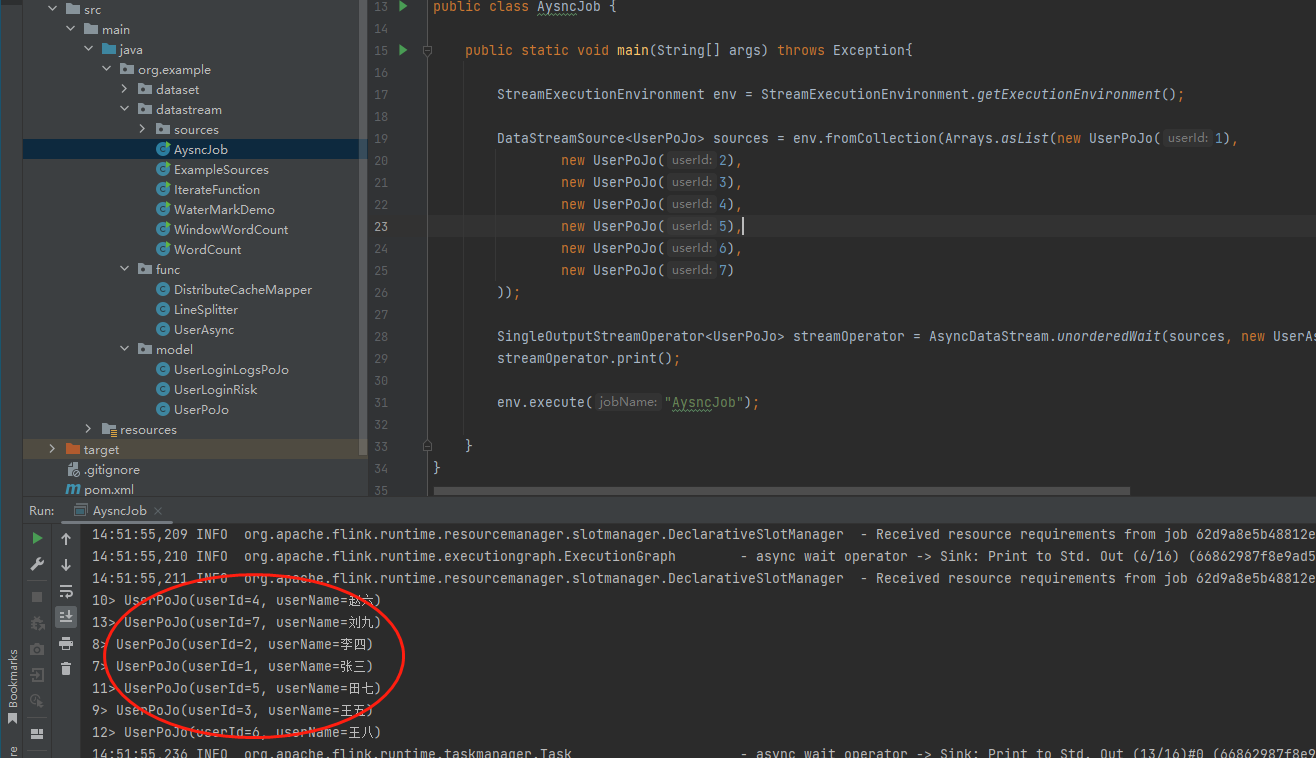
可以看到从数据库中查询到了结果。以上就是我们实现异步I/O的全过程。
备注:
1、异步I/O在实际的etl中使用频率比较高,需要掌握下这个知识点。
2、异步I/O中切记一定要把open和close方法给利用起来。
3、这种异步I/O任务在处理过程中,由于是对接外部的连接,因此可能会出现超时(超过我们设定的超时时间),如果出现超时,那么会抛出异常并且重启整个job作业。如果出现超时,我们不希望他报错的话,可以重写这个asyncFunction里面的timeout方法,示例模块如下图:
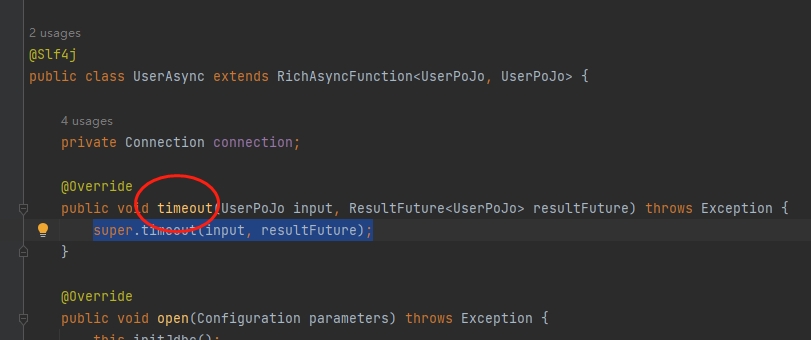
在处理完之后,千万记得调用ResultFuture.complete() 或者 ResultFuture.completeExceptionally(),这样子就相当于告诉flink处理完成,如果没有这两个方法中的任何一个,flink还是会抛出异常并且重启整个job作业。
最后按照惯例,附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...