
在前面我们介绍了很多flink的基础知识,这篇文章我们实战演示下flink的滚动时间窗口函数示例。
时间窗口函数在我们的日常工作中使用场景是非常多的,例如:双十一的大盘,5分钟报数一次,股票的每分钟变化分析等。大家可以根据实际情况进行操作。不多数,直接上代码。
需求:
某个数据源源源不断的发送单词,我们需要对3内接收的单词进行计数求和。
一、模拟一个数据源,源源不断的生产数据。
package com.flink.demo.sources;
import java.util.Random;
import java.util.concurrent.TimeUnit;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
/**
* 由于是demo,所以这里我们自定义一个source,然后自动向source发送数据
*
* @author Administrator
*
*/
public class MySources implements SourceFunction<String> {
private boolean running = Boolean.TRUE;
private static final String[] words = new String[] { "this", "is", "flink", "DataStream", "API", "test" };
private static final Random RANDOM = new Random();
private static final long serialVersionUID = -5258863350761775561L;
public MySources() {
}
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (running) {
this.sendDatas(ctx);
TimeUnit.MILLISECONDS.sleep(100);
}
}
/**
* 随机发送数据
* @param ctx
*/
private void sendDatas(SourceContext<String> ctx) {
String word = words[RANDOM.nextInt(words.length)];
System.out.println("发送了:"+word);
ctx.collect(word);
}
@Override
public void cancel() {
running = Boolean.FALSE;
}
}二、分割下数据源的数据
在前面的数据源里面,生产的数据都是一个个单词,那么我们需要把单词进行切割成(word,num)。
package com.flink.demo.function;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
/**
*
* @author Administrator
*
*/
public class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>>{
private static final long serialVersionUID = -5874538656857236727L;
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
out.collect(new Tuple2<String, Integer>(value, 1));
}
}三、编写flink job。
package com.test.demo;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import com.flink.demo.function.Splitter;
import com.flink.demo.sources.MySources;
public class FlinkTimeWindow {
public static void main(String[] args) throws Exception {
//初始化一个DataStream API得到执行环境
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
//由于是需要使用到时间窗口,因此这里我们需要设置下时间语义,如果没有设置这个时间语义,就会报错
environment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime);
//添加一个数据源
DataStreamSource<String> source = environment.addSource(new MySources());
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = source.
//接收到的是单个单词,这里需要转换一下,即 word - (word,1)
flatMap(new Splitter())
//根据word进行聚合
.keyBy(0)
//设置滚动时间窗口的间隔是3秒钟一次
.timeWindow(Time.seconds(3))
//在每3秒钟一次的情况下,对word聚合的结果进行求和。
.sum(1);
//这里其实是一个真实的业务逻辑处理,我们在这里主要是把滚动时间窗口类的逻辑处理结果打印出来做演示而已。
sum.print();
environment.execute("FlinkTimeWindow");
}
}运行下看看结果
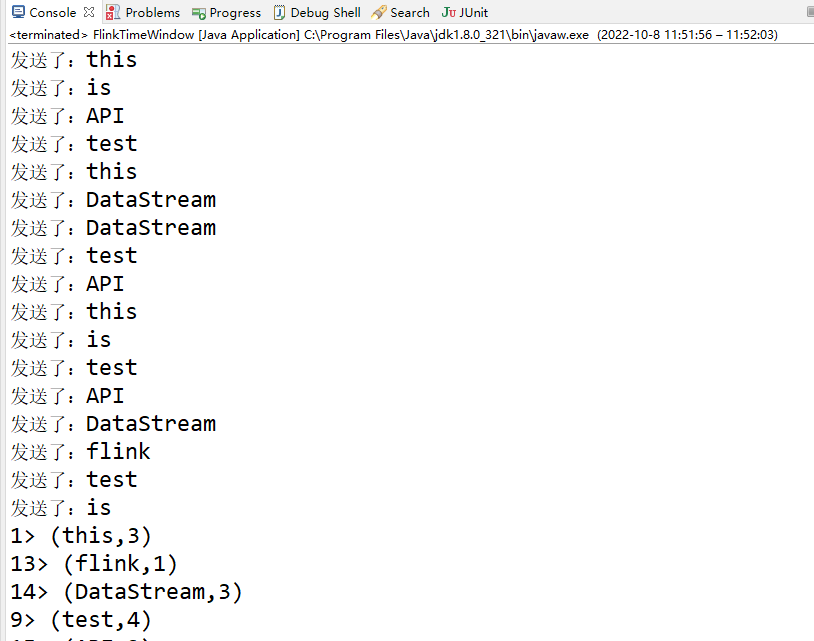
备注:
1、在这个案例里面,由于日志输出的顺序看起来统计结果是不正确的,这主要是由于日志输出的时间有不一样,因此这里可以忽略掉,最终的统计结果是正确的。如果不信的话,可以把mysource替换成mq,然后producer生产固定数量的数据再进行运行即可看到最终结果。








还没有评论,来说两句吧...