
在flink中,我们可以有很多外部的数据源,例如:文件、集合、网络流、消息队列、数据库等,我们在使用flink操作数据的时候,首先都需要读取数据源,因此本篇文章我们介绍下flink读取csv文件并转换成pojo对象数据结构。
1、定义一个csv文件,这里我们手动做一个简单的示例数据即可
id,name,age 1,张三,15 2,李四,16
然后把这个文件保存成user.csv
2、定义一个user的实体类,用来解析user.csv
package com.flink.demo.model;
import java.io.Serializable;
import com.alibaba.fastjson.JSON;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.EqualsAndHashCode;
import lombok.NoArgsConstructor;
import lombok.experimental.Builder;
@Data
@NoArgsConstructor
@AllArgsConstructor
@EqualsAndHashCode
@Builder
public class UserPoJo implements Serializable{
/**
*
*/
private static final long serialVersionUID = 875901357635731459L;
private Integer id;
private String name;
private Integer age;
@Override
public String toString() {
return JSON.toJSONString(this);
}
}3、编写一个flinkjob读取csv文件并且打印下实体信息。
package com.flink.demo.show;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.io.CsvReader;
import org.apache.flink.api.java.operators.DataSource;
import com.flink.demo.model.UserPoJo;
public class ReadCsvJob {
public static void main(String[] args) throws Exception {
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
DataSource<UserPoJo> source = environment.readCsvFile("D:\\example\\user.csv")
// 所有的csv文件都是以英文逗号进行分割的。
.fieldDelimiter(",")
// 第一行是我们的字段行,不需要进行解析
.ignoreFirstLine()
// 这里是解析第几列的数据,有3列,我们就写3个true,如果有一列不需要囊括进来,则选择false即可。
.includeFields(true, true, true)
// 这里是需要把csv文件里面的字段转换成对应的实体类,同时标记对应的字段名称
.pojoType(UserPoJo.class, new String[] { "id", "name", "age" });
//最后我们把source的内容打印出来
source.print();
}
}4、运行测试一下。
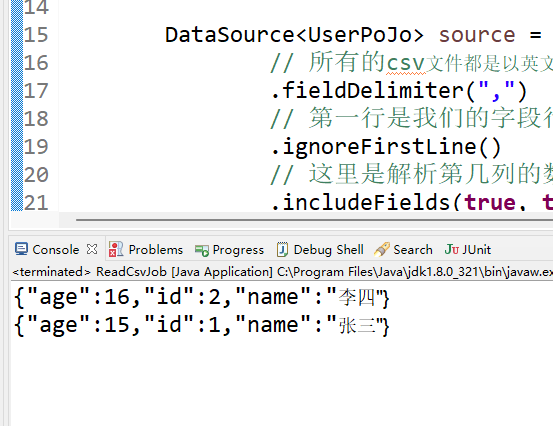
可以看到图中输出了从csv的执行结果。
备注:
1、flink读取csv文件很简单,所有的代码函数的注释都在代码里面,直接看即可。








还没有评论,来说两句吧...