
在前面我们介绍了flink相关的知识点,从本文开始我们着重介绍下flink里面的流处理。因为在flink里面,他的流处理使用范围是最广的,主要是由于他相对于spark来说,这里的流处理是准实时的,可以实现毫秒级别处理百万的数据量。因此flink目前在流处理方面相对来说算是最流行的。
在介绍flink的流处理系列里面,我们还是按照老规矩,先编写一个helloword给大家演示一下。
一、创建一个maven项目,并且在pom文件里面引入相关的依赖:
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-connector-kafka_2.11</artifactId> <version>1.14.0</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-clients</artifactId> <version>1.16.0</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-java</artifactId> <version>1.16.0</version> <scope>provided</scope> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-api</artifactId> <version>1.7.29</version> </dependency> <dependency> <groupId>org.slf4j</groupId> <artifactId>slf4j-log4j12</artifactId> <version>1.7.29</version> </dependency>
二、创建一个StreamingJob.java的类
在这个类里面我们主要实现的就是flink对接kafka-connector的流处理任务,这里我们主要的逻辑就是统计wordcount。具体代码如下:
package com.poortoys.examples;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.util.serialization.SimpleStringSchema;
import com.poortoys.examples.filter.LineSplitter;
public class StreamingJob {
public static void main(String[] args) throws Exception {
if (null == args || args.length != 2) {
// 一般我们在运行的时候,这里的参数都是直接传入进来的,但是我们在本地进行测试,因此这里我们暂时写死一下。
args = new String[] { "43.156.84.225:9092", "test", "t1" };
}
// 由于参数是的传进来的,所以我们需要动态获取一下。
String brokers = args[0];
String consumerTopic = args[1];
String consumerGroup = args[2];
// 初始化本地运行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 初始化kafka connector信息
KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers(brokers).setTopics(consumerTopic)
.setGroupId(consumerGroup).setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema()).build();
// 开始从kafka里面进行监听
DataStreamSource<String> dataStreamSource = env.fromSource(source, WatermarkStrategy.noWatermarks(),
"Kafka Source");
// 计数
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = dataStreamSource.flatMap(new LineSplitter()).keyBy(0)
.sum(1);
sum.print();
env.execute("WordCount Example");
}
}在这里我们使用到了一个LineSplitter的切割类,代码如下:
package com.poortoys.examples.filter;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
private static final long serialVersionUID = 1L;
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] tokens = value.toLowerCase().split(" ");
for (String token : tokens) {
if (token.length() > 0) {
out.collect(new Tuple2<String, Integer>(token, 1));
}
}
}
}以上代码我们就完成了,此时我们运行下看下效果:
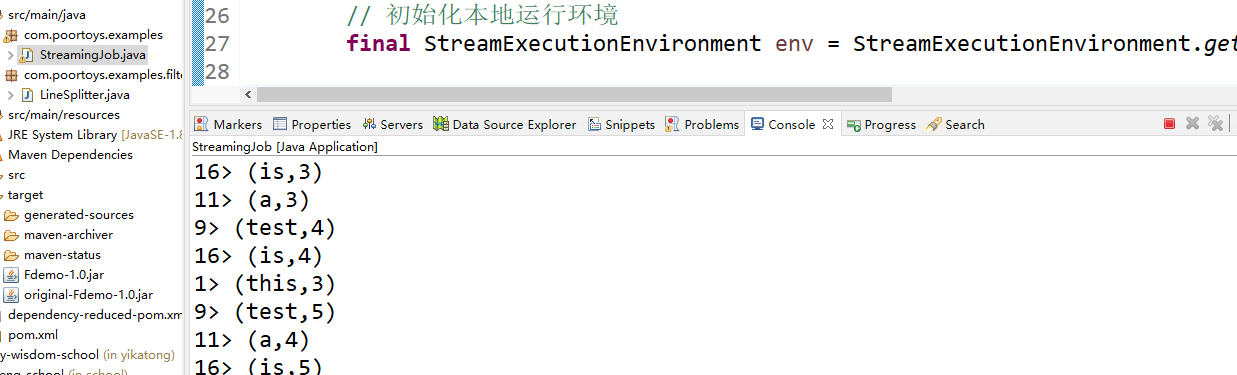
可以看到运行起来正常的,我们通过从kafka里面发送数据,在这个flink的流处理里面,他实现了如下操作:
1、监听kafka对应的topic 2、从kafka对应的topic里面获取到相关的数据 3、把获取到的数据进行切割 4、然后把切割后的单词进行wordcount统计 5、然后把统计结果打印出来。
上面演示了一下在本地进行创建,在这里我们把这个程序打包,放到flink的standalone集群里面运行看看。
三、把这个项目进行maven打包
mvn install
打包完后,可以在项目的target里面看到对应的jar包:
四、把这个jar包放到服务器上
这里我们是把这个jar包放到flink集群的master节点上:
五、把这个job提交到flink集群上
进入到flink的目录里面去,然后执行如下的命令:
./flink run -c com.poortoys.examples.StreamingJob /mnt/Fdemo-1.0.jar
执行完毕后,可以看到job被提交成功了

六、在flink的UI界面查看
job提交成功之后,我们就可以去到flink的WEB UI界面上看到对应的信息了,访问地址是:http:${master_ip}:8081
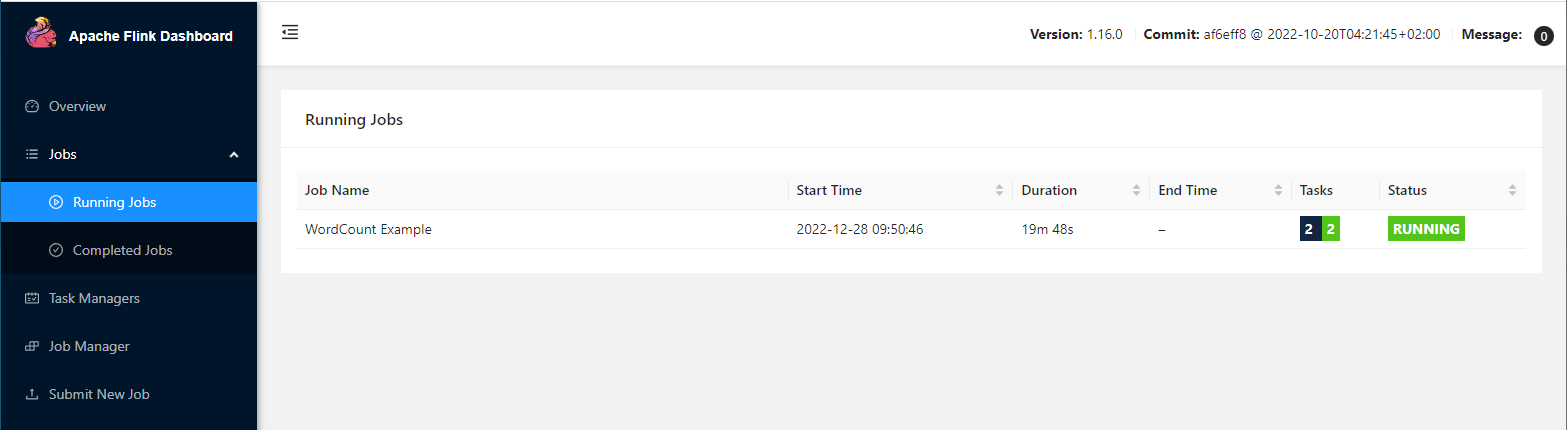
此时我们就可以看到对应的job是running的状态
七、从flink的UI界面看下执行结果
我们再前面是把结果进行打印出来的,因此在stdout的日志里面我们是能看到打印的结果的,此时我们点击TaskManagers
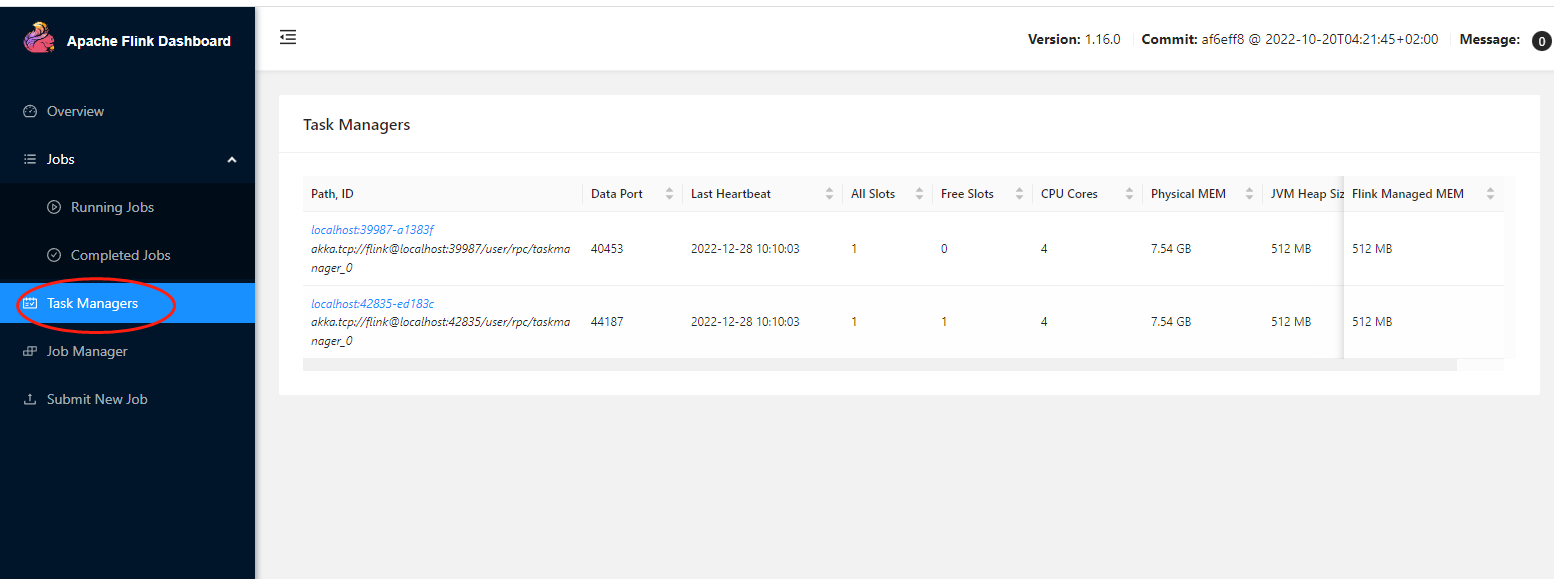
点击进去
再点击这里的stdout
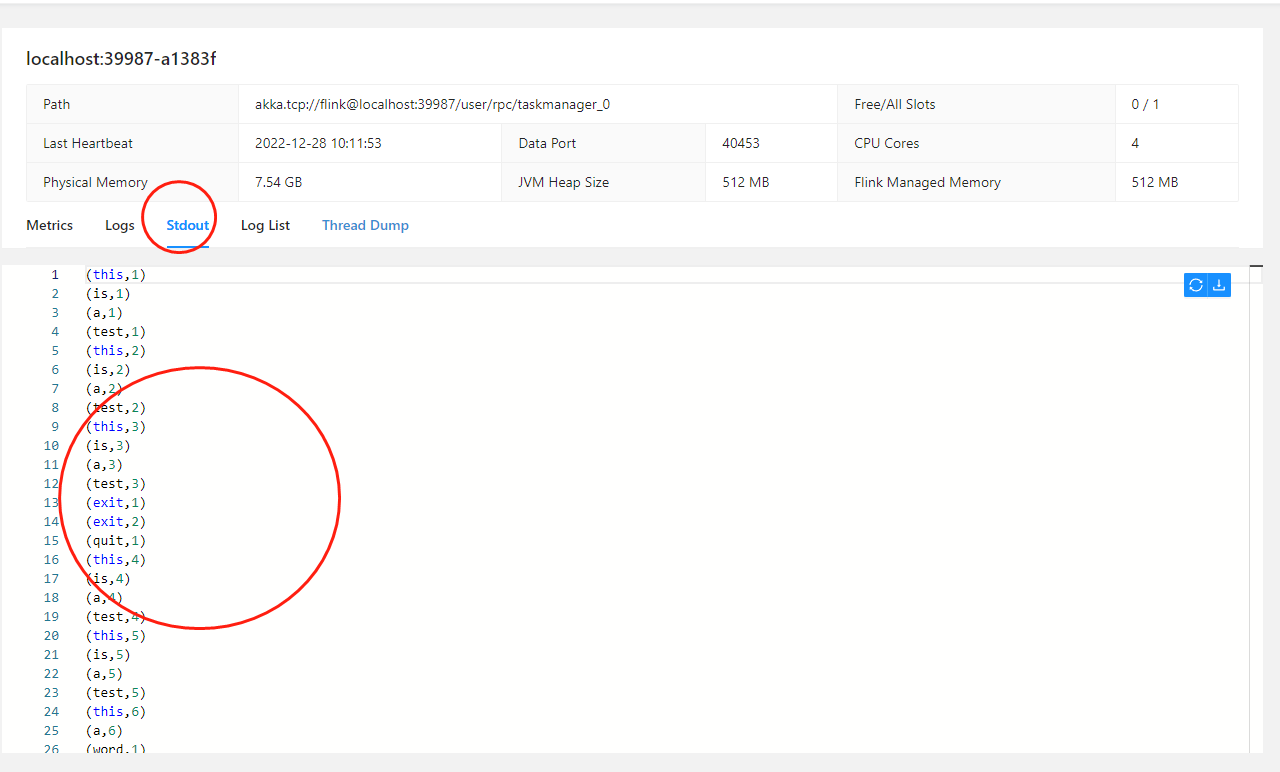
可以看到有正确的执行结果。
以上就是我们flink对接kafka实现wordcount的案例
最后我们附上本案例的源码,登录后即可下载








还没有评论,来说两句吧...