
做过大数据行业的同学,应该都对hadoop不陌生,曾经2011年左右,Hadoop在国内开始火爆,至今已经走过了10多个年头,但是他目前仍是大家做大数据相关不可或缺的一部分。所以从这篇文章开始我们介绍下hadoop相关的情况。
首先来看看hadoop的整体框架图
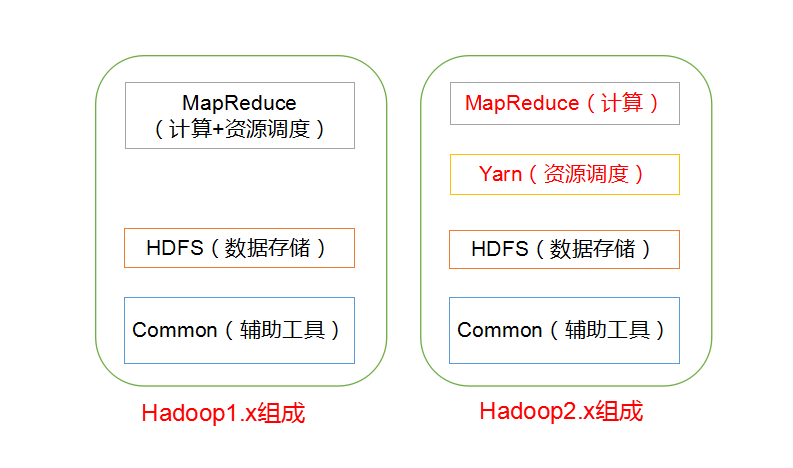
这张图是在网上找的,目前为止hadoop已经发展到3.x的版本了,但是很多公司内部的系统还扔保留大量的2.x版本的生产示例,所以对于hadoop相关的介绍目前都主要基于2.x来介绍,后面我们会提到3.x相关的内容。
在整个hadoop内部的话,他主要由3部分组成,分别是:
1、hdfs(文件存储) 2、MapReduce(分布式计算框架) 3、Yarn(资源调度器)
这3部分构成了整个hadoop的系统框架。
关于hadoop的安装,目前有单机模式和集群模式两种,后面我们的演示主要基于单机模式给大家做演示,这里在早期提供了单机版本的docker版本部署,大家在学习这一系列的时候可以直接快速部署一个docker版本的hadoop单机系统用于做测试使用。 --------《使用docker简单的安装一个hadoop单机演示环境》
暂时简单给大家介绍到这里,后续的文章我们尽量把hadoop的每一个知识点给大家讲到。








还没有评论,来说两句吧...