
Hadoop 分布式系统框架中,⾸要的基础功能就是⽂件系统,在 Hadoop 中使⽤FileSystem 这个抽象类来表示我们的⽂件系统,这个抽象类下⾯有很多⼦实现类,究竟使⽤哪⼀种,需要看我们具体的实现类,在我们实际⼯作中,⽤到的最多的就是HDFS(分布式⽂件系统)以及LocalFileSystem(本地⽂件系统)了。
在现代的企业环境中,单机容量往往⽆法存储⼤量数据,需要跨机器存储。统⼀管理分布在集群上的⽂件系统称为 分布式⽂件系统 。
HDFS(Hadoop Distributed File System)是 Hadoop 项⽬的⼀个⼦项⽬。是 Hadoop的核⼼组件之⼀, Hadoop ⾮常适于存储⼤型数据 (⽐如 TB 和 PB),其就是使⽤ HDFS 作为存储系统. HDFS 使⽤多台计算机存储⽂件,并且提供统⼀的访问接⼝,像是访问⼀个普通⽂件系统⼀样使⽤分布式⽂件系统。
下图是hdfs文件系统的架构图
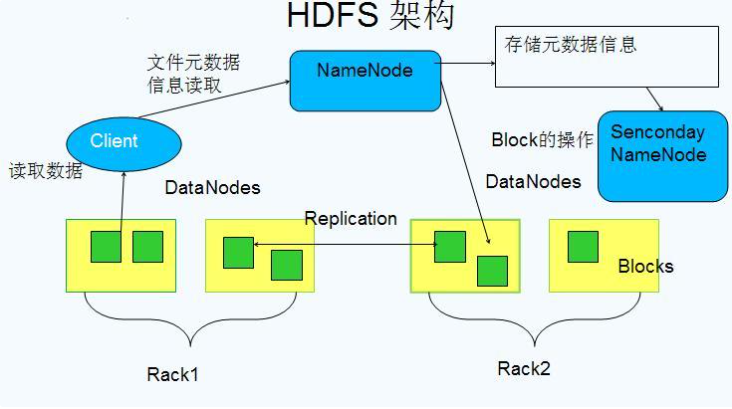
HDFS主要是一个主从的架构,即Master/slave的架构,整个由3部分组成,分别是:
1、SecondaryNamenode 2、NameNode 3、DataNode
在hadoop集群启动之后,我们就可以看到这3个进程,如下图:
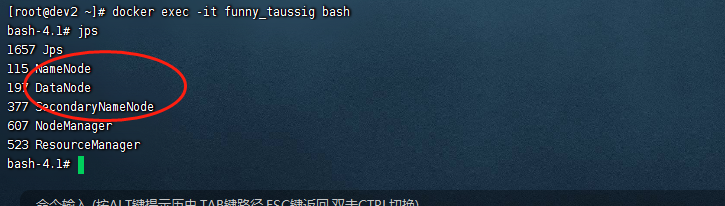
这3个进程启动之后,整个hdfs部分就完整的启动起来了,此时hdfs也就提供了相关的访问端口,例如:
1、50070 2、50075 3、9000

除了9000端口之外,另外两个接口可以直接在浏览器上访问到
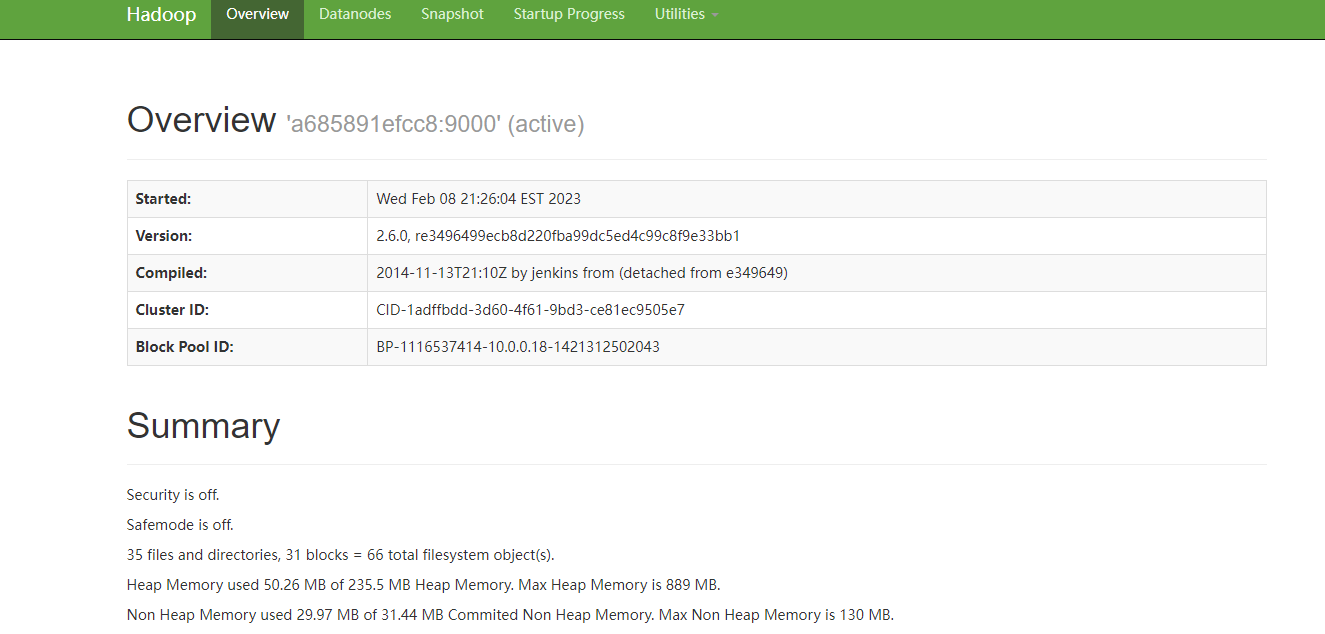
然后我们再分别介绍下这几个进程对应的负责内容:
1)SecondaryNamenode
这个进程主要是用来辅助namenode管理元数据信息的,同时也相当于提供了一个元数据信息的备份,当namenode挂掉之后,我们可以从SecondaryNamenode里面进行恢复。
2)namenode
负责管理整个文件系统的元数据,以及每一个文件所对应的数据块信息。
3)DataNode
负责管理用户的文件数据块,每一个数据块都可以在多个DataNode上存储多个副本,默认的副本是3个。
备注:
1、secondaryNamenode主要是从namenode同步数据过来,会存在一定的延迟,所以如果使用secondary进行元数据恢复的话,可能会导致部分数据丢失。生产上一般我们会做双ha,这样尽量避免手动从secondarynamenode里面恢复元数据信息。








还没有评论,来说两句吧...