
在hadoop集群里面,我们一般会使用yarn做资源管理器,所以这里的话,我们需要为hadoop集群配置调度器,在hadoop上,有三种调度器,分别是:
FIFO 先进先出调度器 Capacity 容量调度器 FairScheduler 公平调度器
对于我们现在来说,在生产环境使用的是公平调度器,所以这篇文章我们介绍下配置FairScheduler公平调度器。
一、修改yarn-site.xml
<property> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value> <description>配置使用公平调度器</description> </property> <property> <name>yarn.scheduler.fair.allocation.file</name> <value>/home/pubserver/hadoop-3.3.5/etc/hadoop/fair-scheduler.xml</value> <description>指明公平调度器队列分配配置文件</description> </property> <property> <name>yarn.scheduler.fair.preemption</name> <value>false</value> <description>禁止队列间资源抢占</description> </property>
二、配置fair-scheduler.xml
在/home/pubserver/hadoop-3.3.5/etc/hadoop/这个目录下,我们新创建一个名称为:fair-scheduler.xml的空白文件,然后把下面的内容复制进去
<?xml version="1.0"?> <allocations> <!-- 单个队列中Application Master占用资源的最大比例,取值0-1 ,企业一般配置0.1 --> <queueMaxAMShareDefault>0.5</queueMaxAMShareDefault> <!-- 单个队列最大资源的默认值 test atguigu default --> <queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault> <!-- 增加一个队列dolphinscheduler --> <queue name="dolphinscheduler"> <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认50,根据线程数配置 --> <maxRunningApps>4</maxRunningApps> <!-- 队列中Application Master占用资源的最大比例 --> <maxAMShare>0.5</maxAMShare> <!-- 该队列资源权重,默认值为1.0 --> <weight>1.0</weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 增加一个队列datax--> <queue name="datax" > <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认50,根据线程数配置 --> <maxRunningApps>4</maxRunningApps> <!-- 队列中Application Master占用资源的最大比例 --> <maxAMShare>0.5</maxAMShare> <!-- 该队列资源权重,默认值为1.0 --> <weight>1.0</weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 任务队列分配策略,可配置多层规则,从第一个规则开始匹配,直到匹配成功 --> <queuePlacementPolicy> <!-- 提交任务时指定队列,如未指定提交队列,则继续匹配下一个规则; false表示:如果指定队列不存在,不允许自动创建--> <rule name="specified" create="false"/> <!-- 提交到root.group.username队列,若root.group不存在,不允许自动创建;若root.group.user不存在,不允许自动创建 --> <rule name="nestedUserQueue" create="false"> <rule name="primaryGroup" create="false"/> </rule> <!-- 最后一个规则必须为reject或者default。Reject表示拒绝创建提交失败,default表示把任务提交到default队列 --> <rule name="reject" /> </queuePlacementPolicy> </allocations>
以上我们的配置就配置完了,接着我们提交个job测试下:
hadoop jar hadoop-mapreduce-jars/hadoop-mapreduce-examples-3.3.5.jar wordcount -Dmapreduce.job.name=wordcount -Dmapreduce.job.queuename=default -Dmapreduce.framework.name=yarn hdfs://192.168.31.218:8020/test hdfs://192.168.31.218:8020/output
运行之后,我们可以看到如下的错误信息:
java.io.IOException: org.apache.hadoop.yarn.exceptions.YarnException: Failed to submit application_1681799429604_0003 to YARN : Reject application application_1681799429604_0003 submitted by user tennant-datax application rejected by placement rules. at org.apache.hadoop.mapred.YARNRunner.submitJob(YARNRunner.java:346) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:251) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1678) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1675) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1899) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1675) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1696) at org.apache.hadoop.examples.WordCount.main(WordCount.java:87) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71) at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144) at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.hadoop.util.RunJar.run(RunJar.java:328) at org.apache.hadoop.util.RunJar.main(RunJar.java:241)
这里主要是由于我们只创建了两个队列,分别是:
dolphinscheduler datax
在配置了公平调度器之后,这里提交的job默认的队列是:root.${username}。
由于我们这里的租户是tenant-datax,所以匹配到的队列是root.tenant-datax。在公平调度器里面匹配不到,并且我们又不允许自动创建队列,因此这里我们就会直接报错,被拒绝提交。
下面我们修改为正常的配置,继续修改fair-scheduler.xml文件,完整内容如下:
<?xml version="1.0"?> <allocations> <!-- 单个队列中Application Master占用资源的最大比例,取值0-1 ,企业一般配置0.1 --> <queueMaxAMShareDefault>0.5</queueMaxAMShareDefault> <!-- 单个队列最大资源的默认值 test atguigu default --> <queueMaxResourcesDefault>4096mb,4vcores</queueMaxResourcesDefault> <!-- 增加一个队列dolphinscheduler --> <queue name="dolphinscheduler"> <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认50,根据线程数配置 --> <maxRunningApps>4</maxRunningApps> <!-- 队列中Application Master占用资源的最大比例 --> <maxAMShare>0.5</maxAMShare> <!-- 该队列资源权重,默认值为1.0 --> <weight>1.0</weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 增加一个队列datax--> <queue name="datax" > <!-- 队列最小资源 --> <minResources>2048mb,2vcores</minResources> <!-- 队列最大资源 --> <maxResources>4096mb,4vcores</maxResources> <!-- 队列中最多同时运行的应用数,默认50,根据线程数配置 --> <maxRunningApps>4</maxRunningApps> <!-- 队列中Application Master占用资源的最大比例 --> <maxAMShare>0.5</maxAMShare> <!-- 该队列资源权重,默认值为1.0 --> <weight>1.0</weight> <!-- 队列内部的资源分配策略 --> <schedulingPolicy>fair</schedulingPolicy> </queue> <!-- 任务队列分配策略,可配置多层规则,从第一个规则开始匹配,直到匹配成功 --> <queuePlacementPolicy> <!-- 提交任务时指定队列,如未指定提交队列,则继续匹配下一个规则; false表示:如果指定队列不存在,不允许自动创建--> <rule name="specified" create="false"/> <!-- 提交到root.group.username队列,若root.group不存在,不允许自动创建;若root.group.user不存在,允许自动创建 --> <rule name="nestedUserQueue" create="true"> <rule name="primaryGroup" create="false"/> </rule> <!-- 最后一个规则必须为reject或者default。Reject表示拒绝创建提交失败,default表示把任务提交到default队列 --> <rule name="reject" /> </queuePlacementPolicy> </allocations>
配置完毕之后,我们重新启动下yarn,再提交job任务
hadoop jar hadoop-mapreduce-jars/hadoop-mapreduce-examples-3.3.5.jar wordcount -Dmapreduce.job.name=wordcount -Dmapreduce.job.queuename=default -Dmapreduce.framework.name=yarn hdfs://192.168.31.218:8020/test hdfs://192.168.31.218:8020/output
然后我们可以看到mapreduce正常执行了,同时创建了root.${username}的队列,如下图:
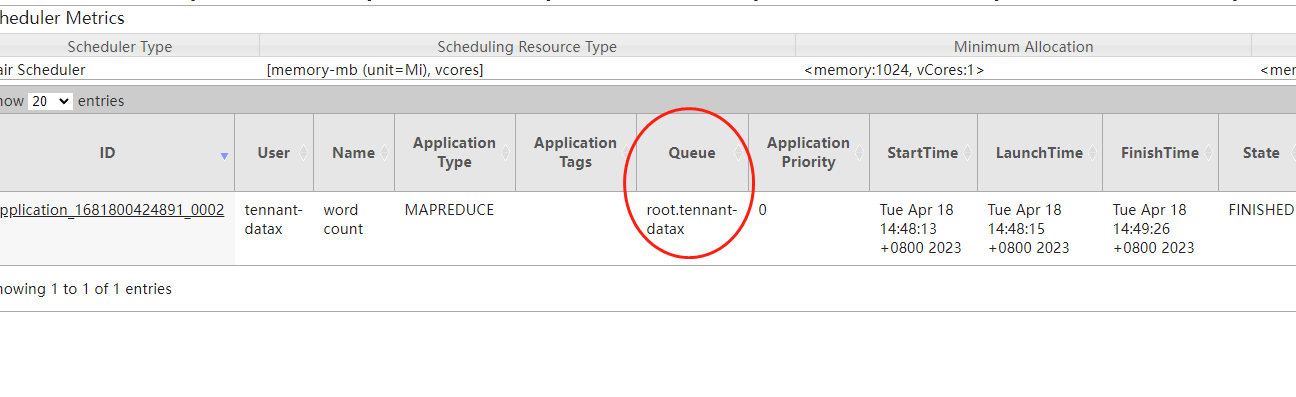
这里我们可以看到,及时我们没有配置对应的队列,他也会自动创建对应的队列,这主要是来源于fair-scheduler.xml里面配置的规则。
备注:
1、在公平调度器里面建议使用第一种的规则配置,也就是不允许自动创建,这样子对于不同的用户,我们使用不同的调度器进行配置,这样子也方便统一管理。
2、第二种配置,如果队列不存在的话,会自动创建队列,适用于一些宽松的环境。








还没有评论,来说两句吧...