
在前面的文字我们介绍了很多hadoop相关的内容,这篇文字我们来演示下编写mapreduce的实战案例。这里实现的第一个案例是大家非常熟悉的wordcount计数程序,总体来说比较简单。下面我们直接演示:
一、创建一个wordcountsource.txt文本
这里创建的这个wordcountsource.txt文本,我们主要是从网上摘抄的一篇英文作文,示例如下:
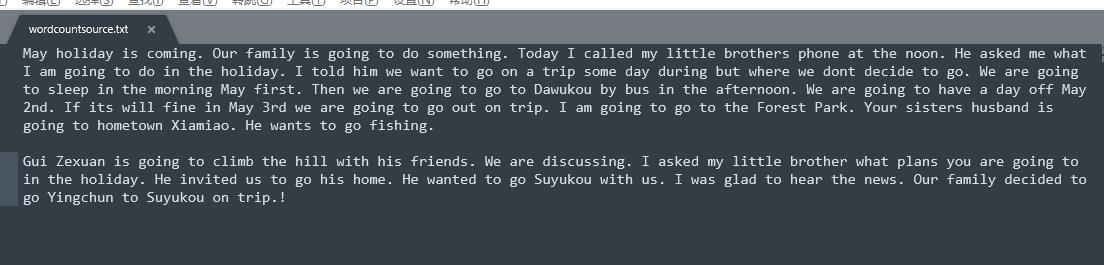
然后我们把这个文本上传到hdfs系统上,如下图:
二、我们创建一个MRDemo的项目
这里的话,我们编写mapreduce程序主要是使用java语言编写,因此这里我们还是创建maven项目。如下图:
三、在maven中引入如下的依赖:
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.5</version> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>3.3.5</version> </dependency>
这里我们主要使用到一个hadoop-client,这个是用来直接操作hdfs的,下面的hadoop-mapreduce-client-core的依赖是用来编写mapreduce的。
四、创建一个map类,实现读取wordcountsource文本里面的内容
这里我们创建一个WordCountMapper的类,主要是实现读取wordcountsource里面的内容,这里主要的业务就是读取每一行的内容,然后把里面的单词进行切割开来,示例代码如下:
package com.mr.demo.map;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
/**
* 从hdfs上读取文本内容的时候,这里使用mapper需要如下的几个输入值:
*<输入键类型,输入值类型,输出键类型,输出值类型> 这种进行类型的对标,对于<输入键类型,输入值类型>我们可以统一使用<Object, Text>即可
*
* 备注:对于上诉的<Object, Text>,仅限于text文本类型,不适合其他类型
*
*
* @author Administrator
*
*/
public class WordCountMapper extends Mapper<Object, Text, Text, IntWritable>{
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountMapper.class);
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
protected void cleanup(Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
LOGGER.info("当前解析到的行内容是:{}",value.toString());
//这里的value就是我们接受到的每一行的内容,我们主要针对于每一行的内容进行解析
StringTokenizer words = new StringTokenizer(value.toString());
while(words.hasMoreTokens()) {
word.set(words.nextToken());
context.write(word, one);
}
//上诉我们的输出内容是: this 1,is 1,a 1,word 1 这种一个单词,数量为1
}
@Override
public void run(Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
super.run(context);
}
@Override
protected void setup(Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
super.setup(context);
}
}五、编写了reduce实现统计数量
这里我们需要编写一个WordCountReduce的类,这个类的主要作用是实现所有的单词统计计数。完整的示例代码如下:
package com.mr.demo.map;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> {
private static final Logger LOGGER = LoggerFactory.getLogger(WordCountReduce.class);
private IntWritable _sum = new IntWritable();
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void reduce(Text key, Iterable<IntWritable> value,
Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
// 到这里经过之前的map解析之后,然后经过shuffle传递过来的值样例是:this:[1,2,3,4,1],is:[1,2,2,1,2]
// 所以我们只需要把后面数组里面的值相加即可。
int sum = 0;
for (IntWritable val : value) {
sum += val.get();
}
_sum.set(sum);
LOGGER.info("对应的key:{} 总数量是:{}",key,sum);
context.write(key, _sum);
}
@Override
public void run(Reducer<Text, IntWritable, Text, IntWritable>.Context arg0)
throws IOException, InterruptedException {
super.run(arg0);
}
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.setup(context);
}
}六、创建WordCountJobs类,实现任务的编制
这里我们把map和reduce都编写好了,在mapreduce里面,提交任务的话是以job为单位,因此这里我们需要编写一个job来进行演示,这里整个逻辑我们已经在代码里面有写备注,大家直接看即可,完整的代码示例如下:
package com.mr.demo;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.mr.demo.map.WordCountMapper;
import com.mr.demo.map.WordCountReduce;
/**
* 这里我们首先编写一个计数的job
*
* @author Administrator
*
*/
public class WordCountJobs {
public static void main(String[] args) throws Exception {
// 在运行mapreduce的时候,我们一般都是直接执行hadoop
// -jar的时候会把这个动态的参数传递进来,因此我们还是尽量保持一致,但是这里的话,我们主要是在本地运行测试,因此这里做下判断,在本地运行的时候稍微简化一点。
if (null == args || args.length == 0) {
args = new String[] {
// 这里的输入文件可以是一个文件夹,也可以是一个具体的文件路径
"/wordcount",
// 这里的输出需要指定一个文件夹
"/wordcounttarget" };
}
// 首先都要创建下这里的configuration,这里我们由于是演示的项目,因此没有特别需要配置configuration的地方,如果没有单独配置,那么所有的配置就直接拿取整个hadoop集群的配置。
Configuration configuration = new Configuration();
// 首先我们看看target目录是否存在,存在的话把他给手动删除一下
deleteOutPut(args[1], configuration);
// 然后我们在这里编写mapreduce,来计数
Job job = Job.getInstance(configuration, "word count");
//设置运行的类,一般都是本类
job.setJarByClass(WordCountJobs.class);
//设置mapper类
job.setMapperClass(WordCountMapper.class);
//设置combine,这里的combine其实主要是在各个服务器上提前执行一次reduce,减少shuffle数据量,这里演示的话,可以加可不加,实际业务环境中根据情况进行处理
job.setCombinerClass(WordCountReduce.class);
//设置reduce类
job.setReducerClass(WordCountReduce.class);
//指定输出的内容key
job.setOutputKeyClass(Text.class);
//指定输出的内容value
job.setOutputValueClass(IntWritable.class);
//添加需要读取的数据源目录
FileInputFormat.addInputPath(job, new Path(args[0]));
//添加需要输出的数据目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* 去服务器上删除掉输出目录,避免输出目录已经存在而报错
*
* @param args
* @throws IOException
*/
private static void deleteOutPut(String path, Configuration configuration) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(new Path(path))) {
fileSystem.delete(new Path(path), true);
}
}
}七、打包MRDemo项目
上面我们的代码都已经编写完了,因此这里的话,我们把项目打包即可,在maven里面我们按照默认打包即可,不需要把依赖都打到最后的jar包上,因为在hadoop集群里面已经存在依赖了,所以这里我们的打包比较简单,打好的包只有9k
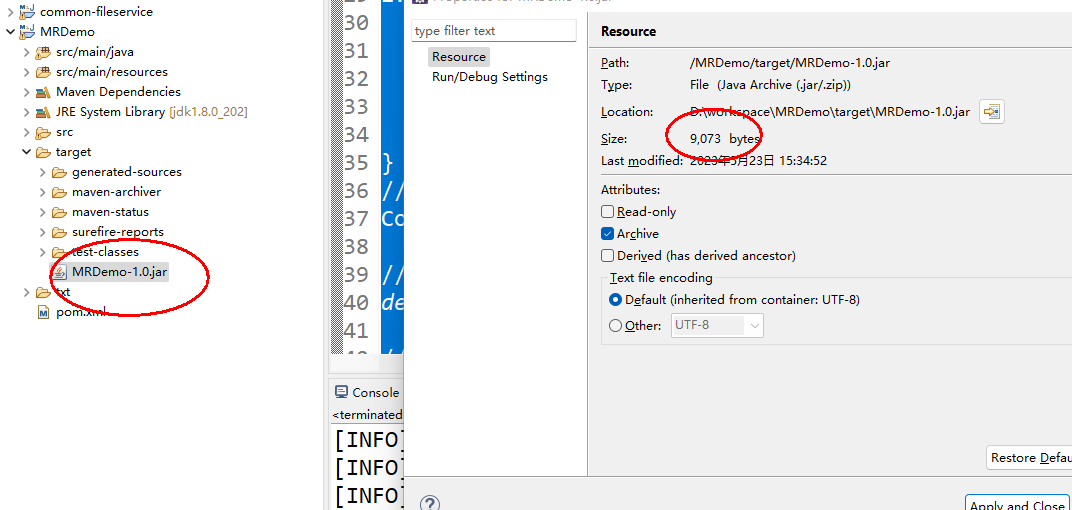
然后我们把这个jar包上传到hadoop集群所在的服务器上,准备执行测试。
八、测试
这里我们测试下运行这个mapredcue任务,看下效果如下,执行的命令如下:
hadoop jar MRDemo-1.0.jar com.mr.demo.WordCountJobs
然后就可以看到任务正在执行了
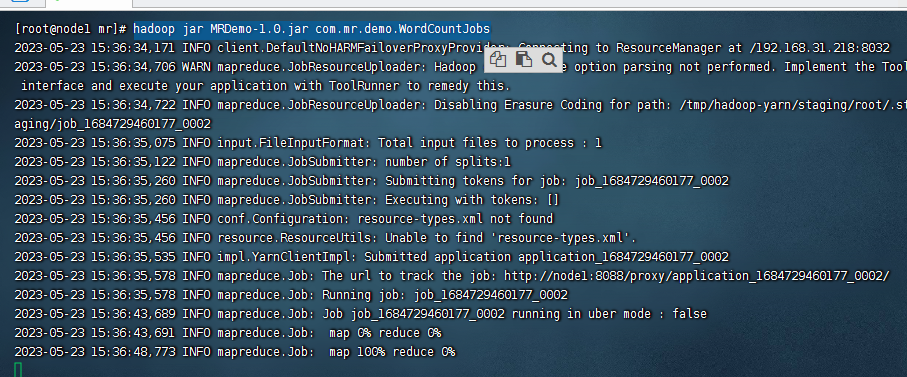
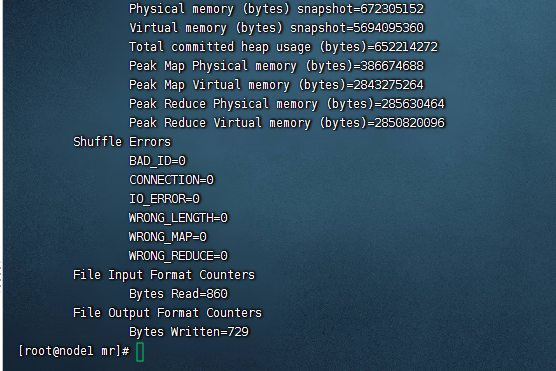
当出现如下的命令就代表执行成功了
然后我们看看hdfs上是否输出了最后的统计结果:
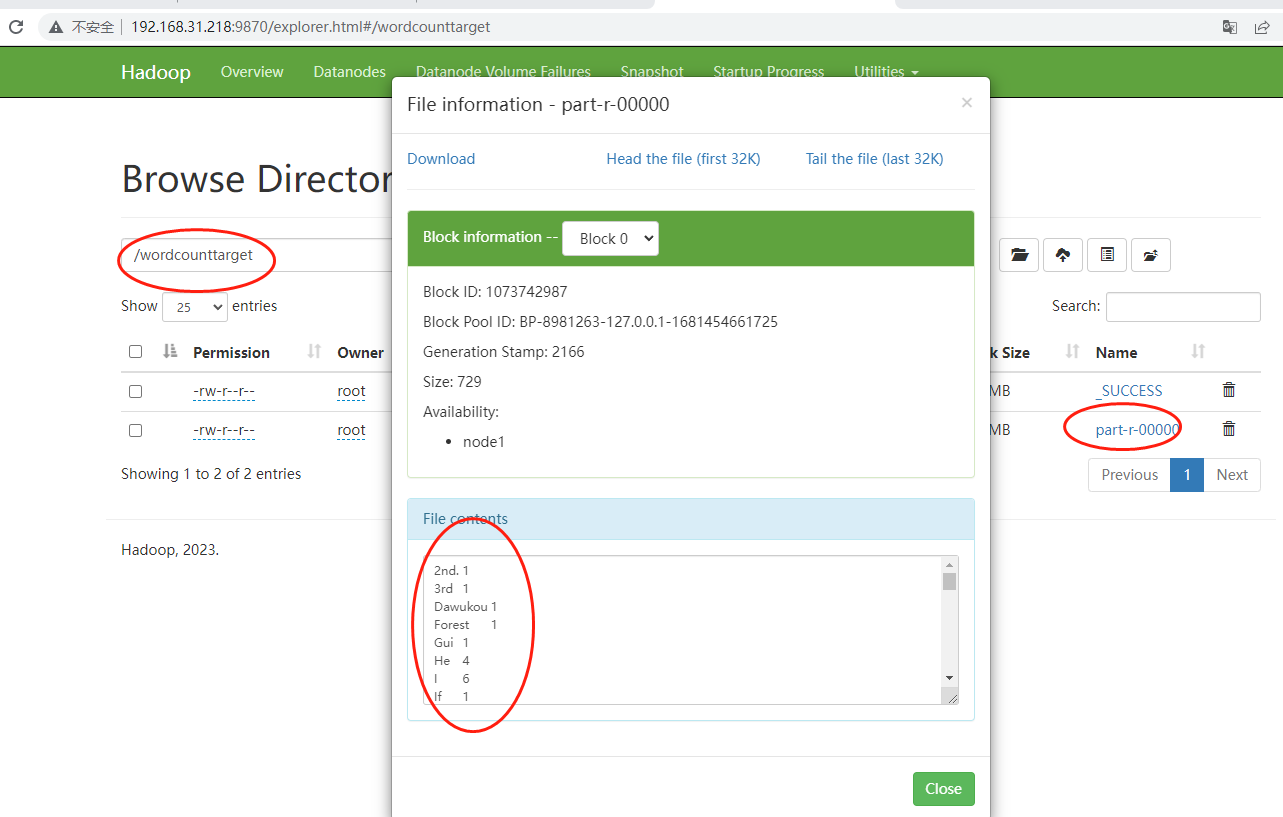
我们得到了想要的结果,说明上面的统计数据是正确的。最后我们来看看yarn的执行情况:
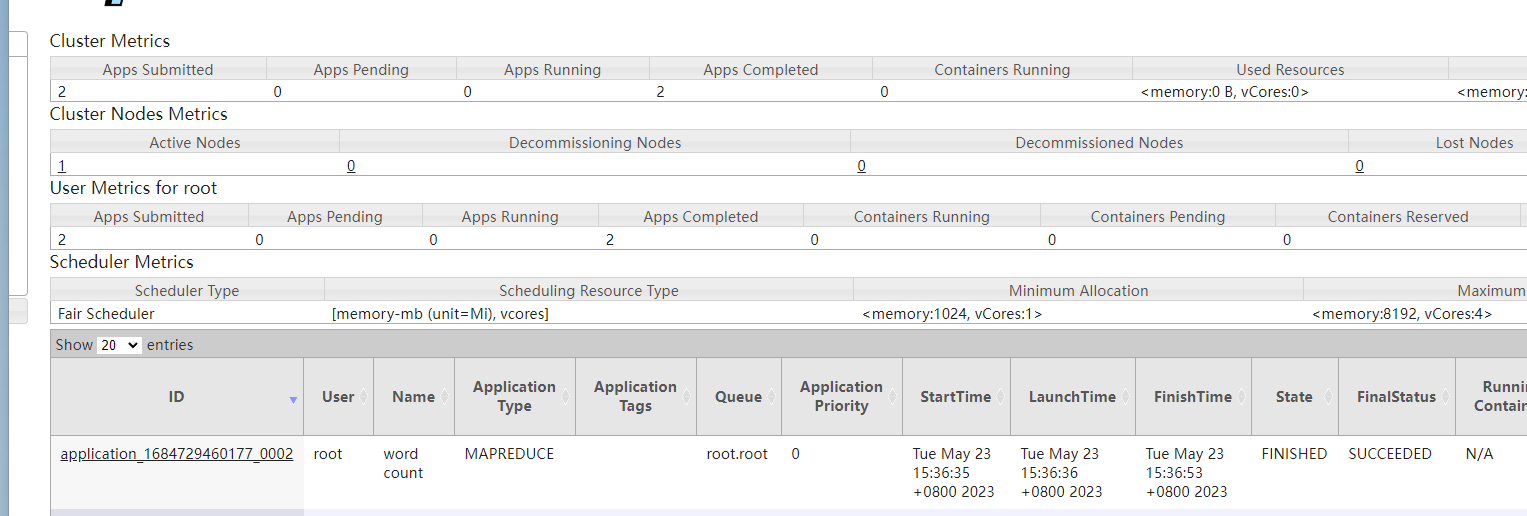
可以看到没有任何问题。
以上我们就实现了一个简单的计数程序了。
备注:
1、虽然现在hadoop的mapreduce已经很少有团队在使用了,但是对于这块的基础部分,我们还是要多熟悉一下,毕竟不知道将来会不会在某些情况下使用呢?
最后按照惯例,附上本案例的源码,登录后即可下载








还没有评论,来说两句吧...