
在常见的数据分析中,我们经常会使用到join相关的数据关联性操作,所以对于传统型的mysql来说,我们只需要编写相关的join的sql语句即可,例如下面我们列举一个学校和学生的数据关系的场景:
学校的数据如下:
{"school_id":1,"school_name":"北京一中","school_address":"北京一中地址"}
{"school_id":2,"school_name":"北京二中","school_address":"北京二中地址"}
{"school_id":3,"school_name":"北京三中","school_address":"北京三中地址"}学生的数据如下:
{"student_id":1,"student_name":"张三","school_id":"1"}
{"student_id":2,"student_name":"李四","school_id":"2"}
{"student_id":3,"student_name":"王五","school_id":"3"}
{"student_id":4,"student_name":"赵六","school_id":"4"}
{"student_id":5,"student_name":"田七","school_id":"2"}
{"student_id":6,"student_name":"王八","school_id":"1"}像上面的数据,如果是使用mysql的话,我们只需要执行下面的sql语句就可以了:
select * from students_info join school_info on students_info.school_id = school_info.school_id
这样子我们就可以得到想要的结果了。但是在hadoop里面,我们使用mapreduce怎么来实现呢?其实在mapreduce中,我们也可以实现这里的mapreduce的效果,但是实现的时候有两种方式,第一种方式是在map端进行join,第二种方式是在reduce端进行join。这篇文字我们首先演示下再map端实现join。下面直接开始演示:
一、添加maven依赖
这里的话,我们还是在这个MRDemo这个项目里面进行编写代码,但是由于这里的输入文件是json的格式,因此我们需要引入外部依赖,最终我们的pom依赖文件如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.mr.demo</groupId> <artifactId>MRDemo</artifactId> <version>1.0</version> <packaging>jar</packaging> <name>MRDemo</name> <url>http://example.com</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <java.version>1.8</java.version> </properties> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.3.5</version> <scope>provided</scope> </dependency> <!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-mapreduce-client-core --> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-mapreduce-client-core</artifactId> <version>3.3.5</version> <scope>provided</scope> </dependency> <!-- https://mvnrepository.com/artifact/com.alibaba/fastjson --> <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.83</version> </dependency> <!-- https://mvnrepository.com/artifact/commons-io/commons-io --> <dependency> <groupId>commons-io</groupId> <artifactId>commons-io</artifactId> <version>2.12.0</version> </dependency> </dependencies> <build> <plugins> <plugin> <artifactId>maven-assembly-plugin</artifactId> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
这里的话,由于在hadoop环境里面没有fastjson这个框架,因此我们在程序打包的时候,需要把这里的fastjson给打入到依赖包里面,因此我们修改了这里的plugin,使用了assembly命令。同时我们不需要打包hadoop相关的依赖,因此添加了provider描述。
二、创建两个数据源文件
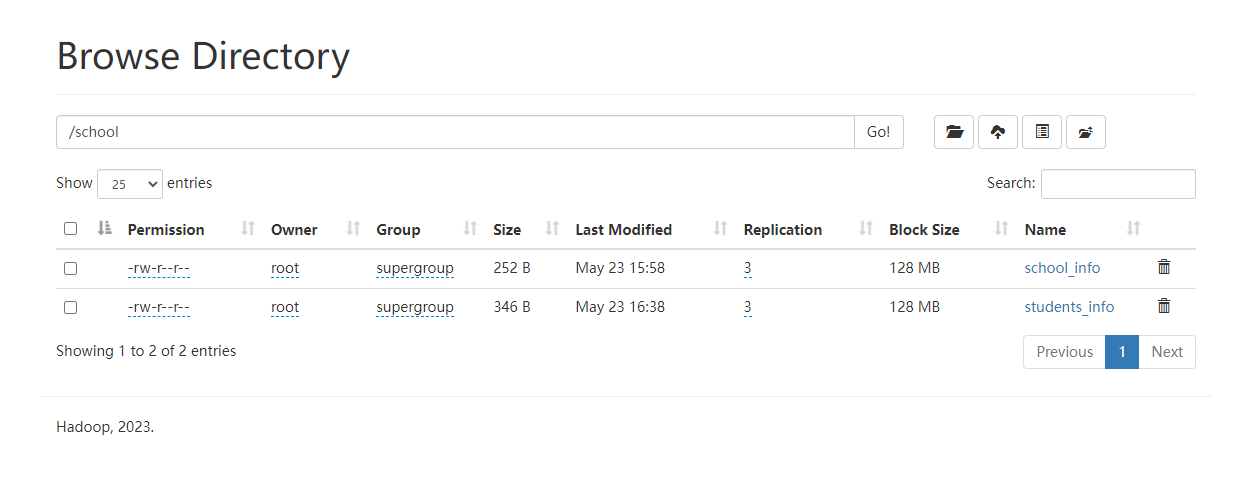
这里的话我们把school_info和students_info做成两个文本文件,然后上传到hdfs上,如下图:
三、我们创建一个MapJoinMapper实现map端join
这里的话我们还是一样的,既然是mapreduce,那么我们首先创建一个map,所以这里我们创建的类是:MapJoinMapper,这个类的主要作用有:
1、在初始化阶段读取小表(也就是读取school_info表) 2、在map阶段读取student表,然后使用if-else进行判断join
这里我们的MapJoinMapper代码示例如下:
package com.mr.demo.map;
import java.io.IOException;
import java.nio.charset.Charset;
import java.util.HashMap;
import java.util.List;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import com.alibaba.fastjson.JSON;
import com.mr.demo.model.SchoolPoJo;
import com.mr.demo.model.StudentPoJo;
/**
* 这里的话,相当于我们需要在map端进行join,这种情况比较适合一些关联表中有小表的情况
* map任务会在本地对自己读取到的达标数据进行join并输出最终的结果,可以很大程度的提交join的并发度,加快处理速度
*
* @author Administrator
*
*/
public class MapJoinMapper extends Mapper<Object, Text, Text, NullWritable> {
private HashMap<Integer, SchoolPoJo> tmpMap = new HashMap<Integer, SchoolPoJo>();
@Override
protected void cleanup(Mapper<Object, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
String stu = value.toString();
StudentPoJo student = JSON.parseObject(stu,StudentPoJo.class);
SchoolPoJo poJo = tmpMap.get(student.getSchool_id());
if(null != poJo) {
student.setSchool_name(poJo.getSchool_name());
student.setSchool_address(poJo.getSchool_address());
}
context.write(new Text(JSON.toJSONString(student)), NullWritable.get());
}
@Override
public void run(Mapper<Object, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
super.run(context);
}
@Override
protected void setup(Mapper<Object, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
// 首先我们获取job的configuration
Configuration configuration = context.getConfiguration();
// 然后我们从configuration里面获取设置的tempfile
String tempFile = configuration.get("tmpfile");
// 然后我们读取tempfile
FileSystem fileSystem = FileSystem.get(configuration);
FSDataInputStream fileInputStream = fileSystem.open(new Path(tempFile));
List<String> lines = IOUtils.readLines(fileInputStream, Charset.forName("UTF-8"));
//然后我们使用fastjson来转移获取到的json字符串
for (String line : lines) {
SchoolPoJo poJo = JSON.parseObject(line, SchoolPoJo.class);
tmpMap.put(poJo.getSchool_id(), poJo);
}
fileInputStream.close();
}
}备注:
1、这里我们使用map端join,不做其他的任务,因此我们不需要再编写reduce了,直接使用map进行输入,然后map进行输出。
四、编写job
还是一样的,我们需要编写一个job来编排整个mapreduce任务,完整的代码示例如下:
package com.mr.demo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.mr.demo.map.MapJoinMapper;
/**
*
* @author Administrator
*
*/
public class MapJoinJobs {
public static void main(String[] args) throws Exception {
// 在运行mapreduce的时候,我们一般都是直接执行hadoop
// -jar的时候会把这个动态的参数传递进来,因此我们还是尽量保持一致,但是这里的话,我们主要是在本地运行测试,因此这里做下判断,在本地运行的时候稍微简化一点。
if (null == args || args.length == 0) {
args = new String[] {
// 这里的输入文件可以是一个文件夹,也可以是一个具体的文件路径
"/school/students_info",
// 这里的输出需要指定一个文件夹
"/schooltarget",
//这里放置临时文件
"/school/school_info"
};
}
// 首先都要创建下这里的configuration,这里我们由于是演示的项目,因此没有特别需要配置configuration的地方,如果没有单独配置,那么所有的配置就直接拿取整个hadoop集群的配置。
Configuration configuration = new Configuration();
//这里设置临时的文件,让他分发到各个节点去
configuration.set("tmpfile", args[2]);
// 首先我们看看target目录是否存在,存在的话把他给手动删除一下
deleteOutPut(args[1], configuration);
// 然后我们在这里编写mapreduce,来计数
Job job = Job.getInstance(configuration, "MapJoin task");
//设置运行的类,一般都是本类
job.setJarByClass(MapJoinJobs.class);
//设置mapper类
job.setMapperClass(MapJoinMapper.class);
//这里我们不需要主要演示的事在map端进行join,在reduce中没有其他的操作,因此这里我们不需要reduce
//指定输出的内容key
job.setOutputKeyClass(Text.class);
//指定输出的内容value
job.setOutputValueClass(NullWritable.class);
//添加需要读取的数据源目录
FileInputFormat.addInputPath(job, new Path(args[0]));
//添加需要输出的数据目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
/**
* 去服务器上删除掉输出目录,避免输出目录已经存在而报错
*
* @param args
* @throws IOException
*/
private static void deleteOutPut(String path, Configuration configuration) throws IOException {
FileSystem fileSystem = FileSystem.get(configuration);
if (fileSystem.exists(new Path(path))) {
fileSystem.delete(new Path(path), true);
}
}
}五、打包
这里我们把整个maven项目进行打包,使用的命令如下:
mvn assembly:assembly
打完包之后,这里就会多出一个带有-with-dependencies后缀的jar包,这里我们可以看到他的大小比较大了,因为包含了fastjson的包,如下图:
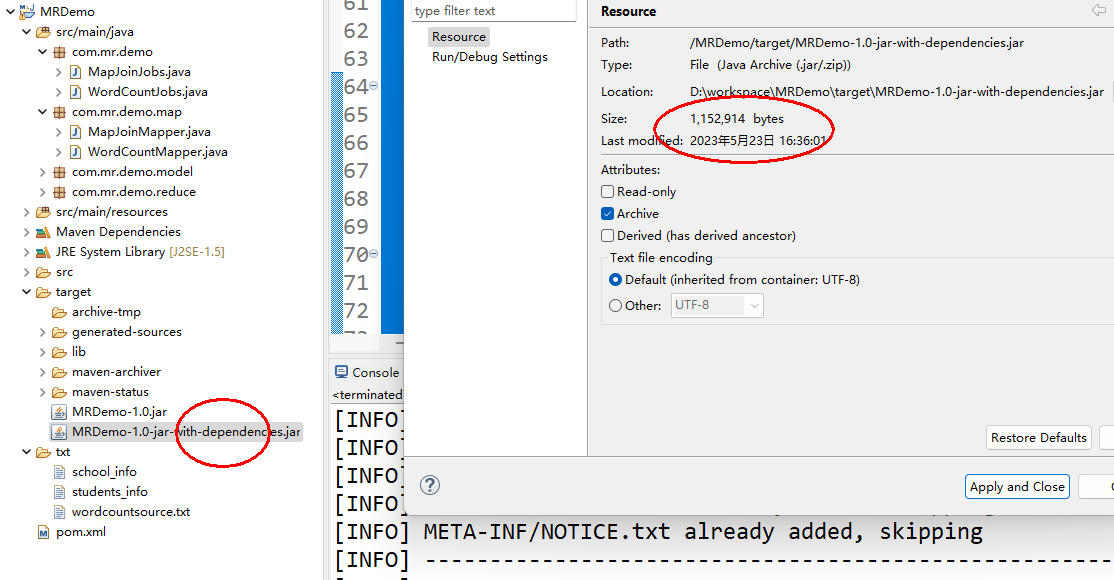
然后我们把这个带有dependences后缀的包上传到服务器上。
六、执行测试
当我们把jar包上传到服务器之后,就可以执行如下的命令:
hadoop jar MRDemo-1.0-jar-with-dependencies.jar com.mr.demo.MapJoinJobs
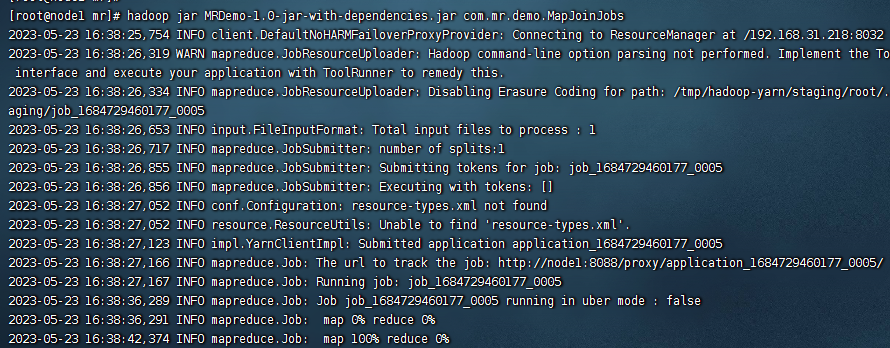
然后等待他执行完毕
然后我们去hdfs上查找对应的结果:
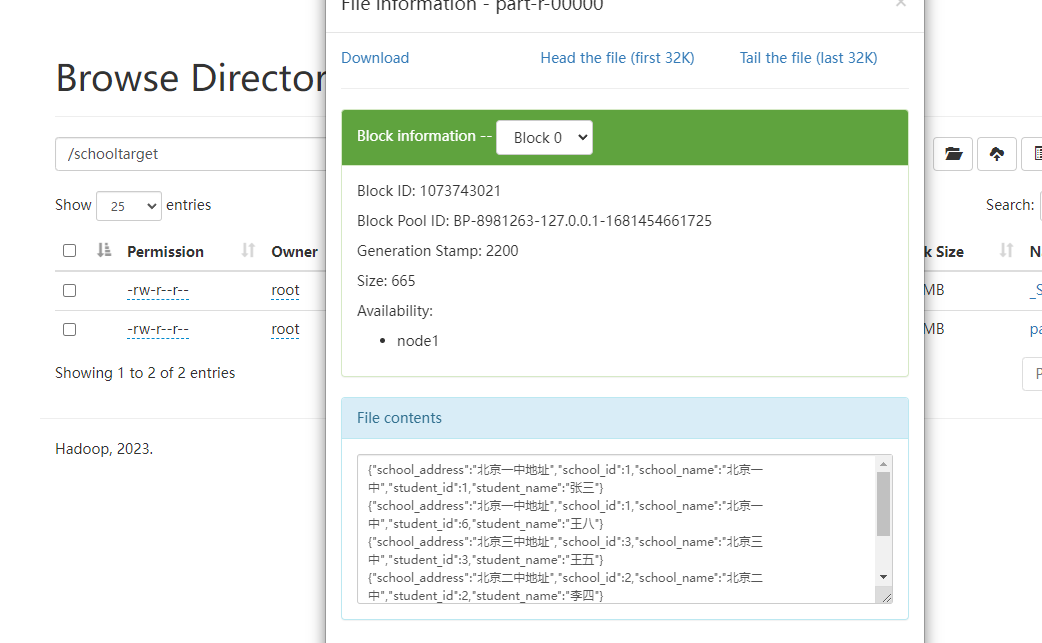
可以看到执行完全没有问题,同时得到了想要的join结果。然后我们再看看yarn的结果:
最后按照惯例,附上本案例的源码,登录后即可下载








还没有评论,来说两句吧...