
上文《TiDB基础教程系列(四)认识TiDB伪集群的spark》我们已经可以访问到spark环境了,本文的话我们演示下使用spark sql查询TiDB的案例。下面直接开始:
前置工作
首先我们做前置工作,使用navicat访问Tidb,然后创建一个库表,向里面插入一些数据,示例如下:
create database test2;
use test2;
CREATE TABLE `chatgpt_users` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`mobile` char(11) NOT NULL COMMENT '手机号码',
`password` char(64) NOT NULL COMMENT '密码',
`avatar` varchar(100) NOT NULL COMMENT '头像',
`salt` char(12) NOT NULL COMMENT '密码盐',
`total_tokens` bigint(20) NOT NULL DEFAULT '0' COMMENT '累计消耗 tokens',
`tokens` bigint(20) NOT NULL DEFAULT '0' COMMENT '当月消耗 tokens',
`calls` int(11) NOT NULL DEFAULT '0' COMMENT '剩余调用次数',
`img_calls` int(11) NOT NULL DEFAULT '0' COMMENT '剩余绘图次数',
`expired_time` int(11) NOT NULL COMMENT '用户过期时间',
`status` tinyint(1) NOT NULL COMMENT '当前状态',
`chat_config_json` text NOT NULL COMMENT '聊天配置json',
`chat_roles_json` text NOT NULL COMMENT '聊天角色 json',
`chat_models_json` text NOT NULL COMMENT 'AI模型 json',
`last_login_at` int(11) NOT NULL COMMENT '最后登录时间',
`vip` tinyint(1) NOT NULL DEFAULT '0' COMMENT '是否会员',
`last_login_ip` char(16) NOT NULL COMMENT '最后登录 IP',
`created_at` datetime NOT NULL,
`updated_at` datetime NOT NULL,
PRIMARY KEY (`id`)
);
INSERT INTO `chatgpt_users`(`id`, `mobile`, `password`, `avatar`, `salt`, `total_tokens`, `tokens`, `calls`, `img_calls`, `expired_time`, `status`, `chat_config_json`, `chat_roles_json`, `chat_models_json`, `last_login_at`, `vip`, `last_login_ip`, `created_at`, `updated_at`) VALUES (4, '18575670125', 'ccc3fb7ab61b8b5d096a4a166ae21d121fc38c71bbd1be6173d9ab973214a63b', 'http://img.r9it.com/chatgpt-plus/1693981355719469.png', 'ueedue5l', 44850, 1013, 5650, 58, 1756456236, 1, '{\"api_keys\":{\"Azure\":\"\",\"ChatGLM\":\"\",\"OpenAI\":\"\"}}', '[\"elon_musk\",\"girl_friend\",\"lu_xun\",\"red_book\",\"psychiatrist\",\"translator\",\"weekly_report\",\"artist\",\"dou_yin\",\"english_trainer\",\"gpt\",\"kong_zi\",\"programmer\",\"seller\",\"steve_jobs\",\"teacher\"]', '[\"completions_pro\",\"eb-instant\",\"general\",\"generalv2\",\"chatglm_pro\",\"chatglm_lite\",\"chatglm_std\",\"gpt-3.5-turbo-16k\",\"gpt-4\"]', 1699603918, 1, '::1', '2023-06-12 16:47:17', '2023-11-10 16:27:31');
INSERT INTO `chatgpt_users`(`id`, `mobile`, `password`, `avatar`, `salt`, `total_tokens`, `tokens`, `calls`, `img_calls`, `expired_time`, `status`, `chat_config_json`, `chat_roles_json`, `chat_models_json`, `last_login_at`, `vip`, `last_login_ip`, `created_at`, `updated_at`) VALUES (91, '18575670126', '5e4050b8dd403f593260395d9edeb9f273dbe92d15dfdd929c4a182e95da10c4', '/images/avatar/user.png', '6fj0otl8', 0, 0, 10, 0, 0, 1, '{\"api_keys\":{\"Azure\":\"\",\"ChatGLM\":\"\",\"OpenAI\":\"\"}}', '[\"gpt\"]', '[\"completions_pro\",\"eb-instant\",\"general\",\"generalv2\",\"chatglm_pro\",\"chatglm_lite\",\"chatglm_std\",\"gpt-3.5-turbo-16k\"]', 1697184324, 0, '::1', '2023-10-13 16:01:56', '2023-11-09 18:07:27');执行完成之后,我们可以查看具体的数据:
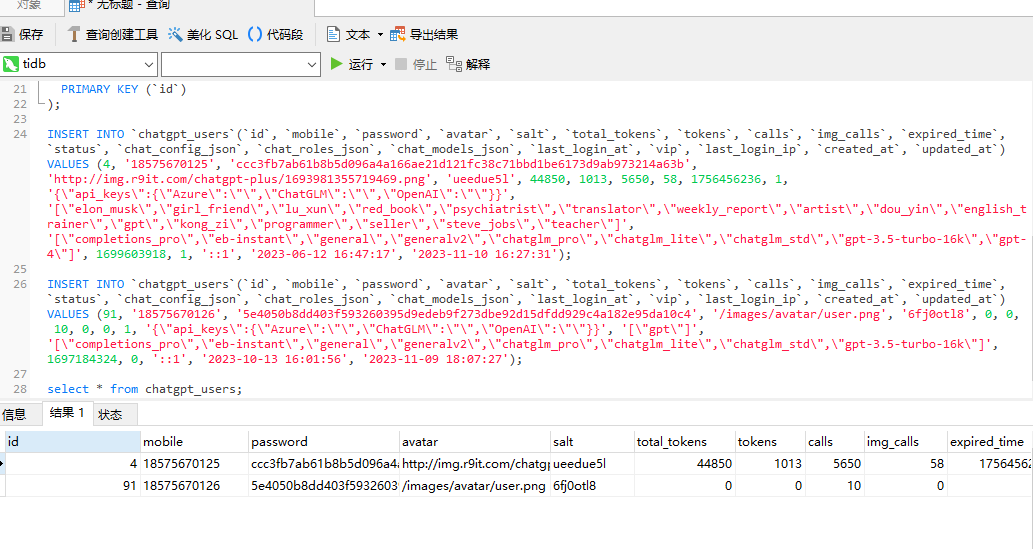
到此我们的前置准备工作就完成了。
使用spark sql查询TiDB数据
接着我们使用spark sql来查询下TiDB的数据。
1)首先进入到服务器中,查看spark master的名称:
docker ps

2)进入到spark的master容器内
docker exec -it tidb-docker-compose_tispark-master_1 bash

3)执行spark命令,进入到命令行:
/opt/spark/bin/spark-shell
执行后,等待命令行出现即可,示例图如下:
4)查询Tidb数据:
#导入TiDB依赖
import org.apache.spark.sql.TiContext
#创建Tidb的context
val ti = new TiContext(spark) 或者可以写成:val ti = new TiContext(spark, List("172.19.32.14:32768")) 也就是在后面添加pd的ip+端口
#选择数据库
ti.tidbMapDatabase("test2")
#查询数据:
spark.sql("select count(*) from chatgpt_users").show这样子就可以查询出来数据了。








还没有评论,来说两句吧...