
在之前的安装文档《TiDB基础教程系列(二)使用docker方式快速部署TiDB伪集群》里面我们看到启动了2个spark的容器,分别为一主一从,如下图:

所以这里我们相当于有一个现成的spark环境可以使用,在观望的Tidb架构里面也有spark的组成部分,如下图

所以本文我们认识下使用docker部署的TiDB伪集群的spark。
做过大数据的同学应该了解,spark有一个webui,这里我们看master,可以看到开放了端口8080:

我们使用浏览器访问一下:
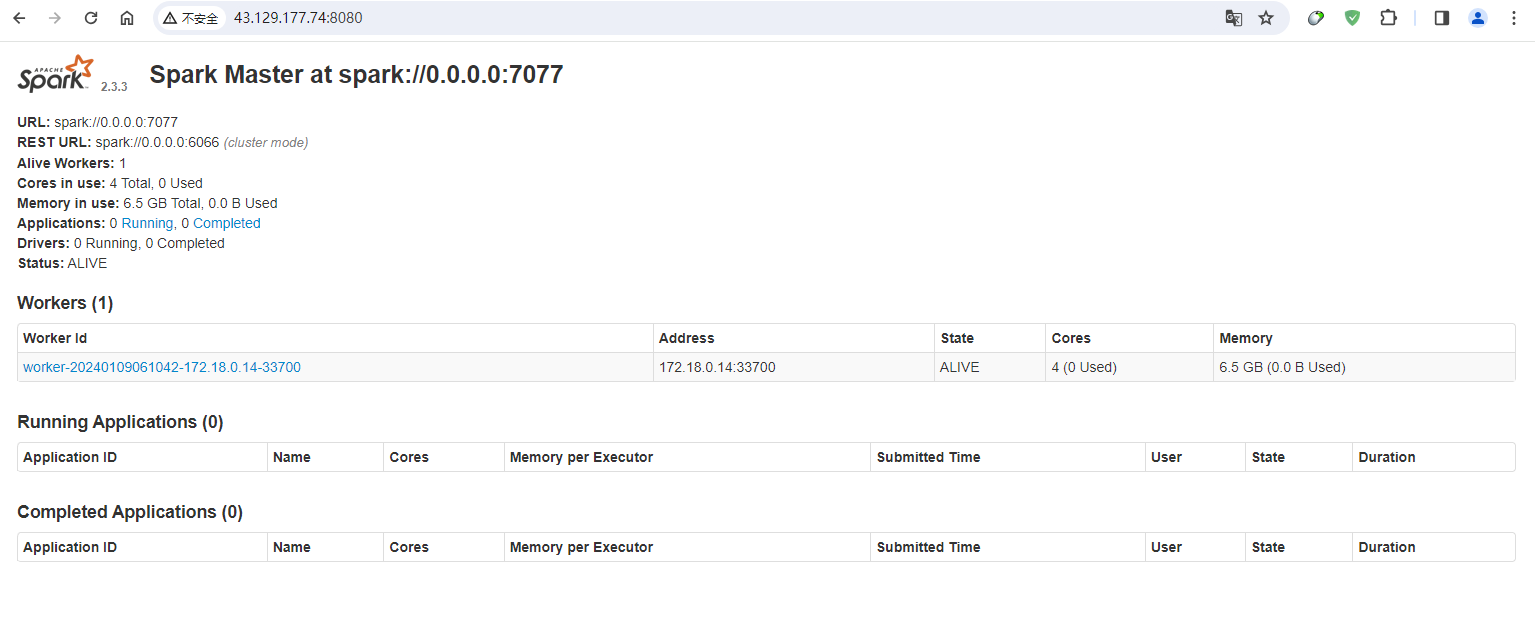
可以看到成功的访问到了spark。








还没有评论,来说两句吧...