
今天在内网看到一篇关于算法评测的文章,觉得很有借鉴意义。以下是一些笔记:
此篇文章介绍了语音识别(ASR)的评测方法、对比评测模型与实践。
既然要做评测,首先,便要确定一些指标。
语音识别评价指标:
1. 字正确率(Word Correct Rate,WCR)
2. 句正确率(Sentence Correct Rate,SCR)
这两个指标的出现也是很自然的。接下来的问题就是,如何量化这两个指标。
第一个是字正确率:
字错误率: WER = (S + D + I) / N 字正确率: WCR = 1 - WER 识别结果文本数字: M = Mc + S + I 正确文本字数: N = Mc + S + D 正确识别字数:Mc 删除错误字数:D 插入错误字数:I 替换错误字数:S
其次是句正确率:
句子中如果有一个词识别错误,那么整个句子被认为识别错误。 句错误率: SER = SE / N 句正确率: SCR = 1- SER 识别错误句子数:SE 句子总数:N
接下来,就要设计用于评测的测试数据。按照不同的维度,我们可以从非常多的角度去思考。
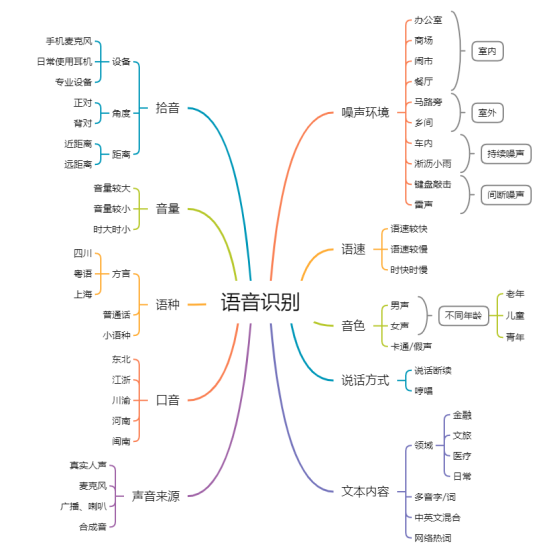
这个环节的难点在于:我们如何去构造这么多种类的测试集?
人工去录制不同的声音当然是基础。文章中另外介绍了几个关于语音处理的自动化工具:
1、pydub(https://github.com/jiaaro/pydub)
一个Python音频处理库
2、ffmpeg(https://www.ffmpeg.org/)
一个完整的跨平台解决方案,用于录制、转换和流式传输音频和视频。ffmpeg 是一个非常快速的视频和音频转换器,它可以从实时音频/视频源中抓取数据。它还可以在任意采样率之间进行转换,并使用高质量的多相滤波器动态调整视频大小。
这些自动化工具可以用在以下场景:
1、调节速度
2、调节音量
3、混合噪音等等
具体的可以参考工具的官方文档。
最后就是在以上数据的基础上建立ASR评测模型。本文采取了加权平均的方式:评测指标 * 排名换算的分数 加权。
那么测试的整体流程就是:
测试准备 测试方案 建立评测模型 评测对象 数据准备 音频录制 音频切分 文本标注 测试进行 自动化脚本 首帧响应时长 字正确率 句正确率 测试完成 数据汇总统计 数据分析
其他注意点:
句末标点会不同程度的影响字正确率,且后续实际业务使用场景中,标点对NLP识别可能会有影响。因此测评中统计了四个指标:
S1:未除去句末标点,句正确率得分 S2:未除去句末标点,字正确率得分 S3:除去句末标点后,句正确率得分 S4:除去句末标点后,字正确率得分
归一化问题,比如WIFI -> wifi,6 -> 六,这些词都属于同义词,但在以上的识别中会被当做不同的词而导致不准确的正确率。
模型优化,目前模型是用加权平均的方式,适用于对象的综合比较,但不容易体现对象的致命缺陷。








还没有评论,来说两句吧...