
对机器学习模型的评估是一件非常重要的工作——如果不能量化一个模型的预测效果,我们就如同瞎子摸象,无法对模型进行改进。
机器学习本身就需要大量的训练数据,显然,用相同的数据对模型进行测试是一个方法论上的错误:一个只会重复刚刚看到的样本标签的模型将获得完美的分数,但无法预测任何有用的东西——没有见到过的新数据。这种情况称为过拟合。
为了避免这种情况,在执行(监督)机器学习时,通常的做法是将部分可用数据作为测试集,使用测试集来对模型进行评估。
交叉验证 (CV) 是用于测试机器学习模型有效性的技术之一,如果我们的数据有限,它也可以作为一个评估模型的重采样程序。
以下是用于 CV 的一些常用技术:
1、Train_Test Split approach 训练集-测试集拆分方法
在这种方法中,我们将完整的数据集随机分成训练集和测试集。用训练集训练模型,用测试集来验证。一般按照70:30,或者80:20的比例来划分。
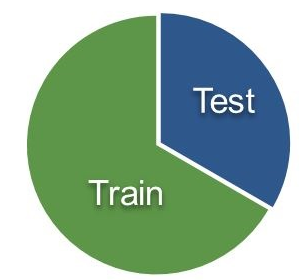
这种方法可能会导致高偏见,因为没有在训练中利用完所有数据。
在sklearn中,train_test_split 可以方便的实现训练集和数据集的数据划分。
代码实现:
from sklearn import datasets from sklearn.model_selection import train_test_split iris = datasets.load_iris() x = iris.data y = iris.target x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
训练模型及使用内置的score方法评估模型:
knn = KNeighborsClassifier() knn.fit(x_train, y_train) predictions = knn.predict(x_test) score = knn.score(x_test, y_test) print(score)
score方法评估模型的原理,我们之后再聊;
2、k-fold cross-validation K折交叉验证
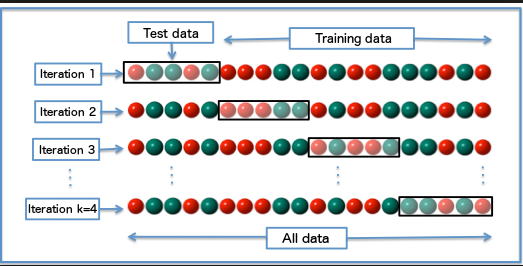
1、将整个数据随机分成 K 折(K 的值不能太小或太高,理想情况下我们根据数据大小选择 5 到 10)。K 值越高,模型偏差越小(但大方差可能导致过度拟合),而 K 值越低,就越接近我们上面提到的训练集-测试集拆分方法。
2、然后使用从1到K-1折的数据来训练模型,并使用剩余的第K折验证模型,记下分数/错误。
3、重复这个过程,直到每一折都做过测试集。然后取你记录的分数的平均值。这就是此模型的性能指标。
同样我们可以用sklearn内置的方法来计算,cross_val_score 可以返回每一次计算的分数。
代码实现:
from sklearn.model_selection import cross_val_score
import numpy as np
cv_r2_scores_knn = cross_val_score(knn, x, y, cv=5, scoring='r2')
print(cv_r2_scores_knn) # [0.95 1. 0.9 0.95 1. ]
print("Mean 5-Fold R Squared: {}".format(np.mean(cv_r2_scores_knn)))当然也可以用手工的方式,计算每一次迭代的分数,最后组合成数组返回。
当然,还有其他一些交叉验证的方法,留待以后再介绍。








还没有评论,来说两句吧...