
上文《ClickHouse基础系列(一)ClickHouse介绍》我们对ClickHouse做了大致的介绍,本文的话我们来演示下ClickHouse的集群部署。
ClickHouse是c++编写的,所以一般集群的话我们使用rpm安装包进行安装。下面介绍下集群的部署。
1)准备服务器
这里我们准备3台服务器,做一个3个节点的clickhouse集群。这里我已经准备好了,实例如下:
| 序号 | 节点 | ip |
| 1 | node1 | 172.19.0.6 |
| 2 | node2 | 172.19.0.8 |
| 3 | node3 | 172.19.0.10 |
备注:
1、在实际的生产环境中,这些服务器的配置尽量要求高一点,例如:16H,64G,TB级别硬盘,当然还是要根据实际情况来对服务器进行规划。
2)部署zookeeper
clickhouse集群之间的状态同步是使用zookeeper来同步的,所以这里我们需要准备一个zookeeper集群。详情可参考:《zookeeper集群部署教程》。一定要记得在这一步把ssh免密码登录给配置了。
3)下载安装包
前面介绍我们clickhouse是使用c++语言编写的,所以这里我们需要去官网下载rpm安装包,这里的下载地址是:clickhouse官网下载。这里由于clickhouse的发版非常频繁,所以我们这里演示下载的安装包是:
clickhouse-client-24.1.5.6.x86_64.rpm clickhouse-common-static-24.1.5.6.x86_64.rpm clickhouse-server-24.1.5.6.x86_64.rpm
这里下载完成之后,我们把他上传到node1,node2,node3服务器上:

4)执行安装
这里我们到node1,node2,node3服务器上分别执行下rpm的安装。执行命令如下:
#在node1,node2,node3服务器上分别执行 rpm -ivh clickhouse-common-static-24.1.5.6.x86_64.rpm rpm -ivh clickhouse-server-24.1.5.6.x86_64.rpm rpm -ivh clickhouse-client-24.1.5.6.x86_64.rpm
下载不同的版本,则修改为不通的rpm包就可以了。
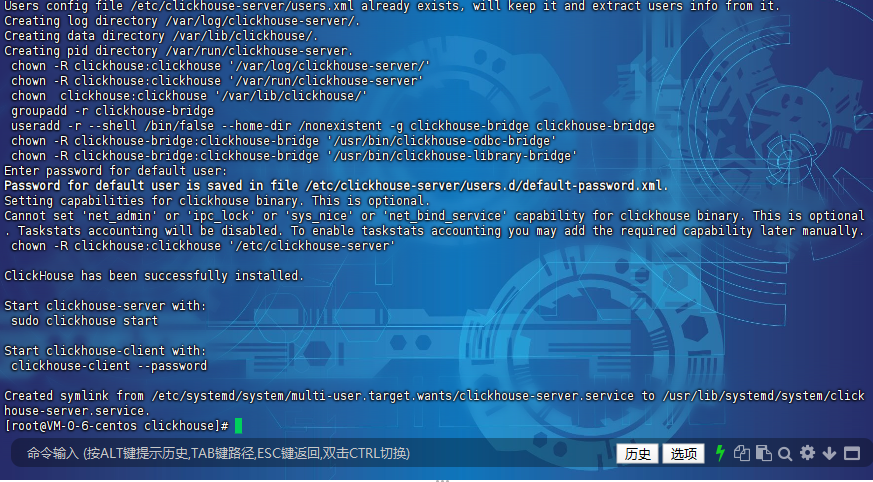
整个过程需要输入一个用户,这里3个都保持一致就可以了,我这里输入的是root,然后这里有提示密码存放的文件:/etc/clickhouse-server/users.d/default-password.xml
5)修改配置
既然是集群,我们就要把这3个节点配置为集群。所以这里需要做如下的配置。
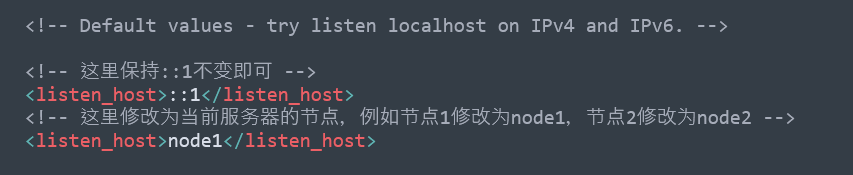
首先修改每一个节点上的/etc/clickHouse-server/config.xml文件,把host修改为当前的host,实例如下:
<!-- 这里保持::1不变即可 --> <listen_host>::1</listen_host> <!-- 这里修改为当前服务器的节点,例如节点1修改为node1,节点2修改为node2 --> <listen_host>node1</listen_host>
接着我们在每一个节点服务器的如下位置:/etc/clickhouse-server/config.d 创建一个名称为:metrika.xml的文件,这个文件我们主要是配置集群存储数据的分片信息,我们把如下的数据写入metrika.xml文件即可:
<yandex> <remote_servers> <ClickHouse_cluster_3shards_1replicas> <shard> <internal_replication>true</internal_replication> <replica> <host>node1</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node2</host> <port>9000</port> </replica> </shard> <shard> <internal_replication>true</internal_replication> <replica> <host>node3</host> <port>9000</port> </replica> </shard> </ClickHouse_cluster_3shards_1replicas> </remote_servers> <zookeeper> <node index="1"> <host>node3</host> <port>2181</port> </node> <node index="2"> <host>node4</host> <port>2181</port> </node> <node index="3"> <host>node5</host> <port>2181</port> </node> </zookeeper> <macros> <shard>01</shard> <replica>node1</replica> </macros> <networks> <ip>::/0</ip> </networks> <ClickHouse_compression> <case> <min_part_size>10000000000</min_part_size> <min_part_size_ratio>0.01</min_part_size_ratio> <method>lz4</method> </case> </ClickHouse_compression> </yandex>
这里我们把配置的参数说明一下:
| 序号 | 指标 | 说明 |
| 1 | remote_servers | ClickHouse集群配置标签,固定写法。 |
| 2 | ClickHouse_cluster_3shards_1replicas | 配置ClickHouse的集群名称,可自由定义名称,注意集群名称中不能包含点号。这里代表集群中有3个分片,每个分片有1个副本。 分片是指包含部分数据的服务器,要读取所有的数据,必须访问所有的分片。 副本是指存储分片备份数据的服务器,要读取所有的数据,访问任意副本上的数据即可。 |
| 3 | shard | 分片,一个ClickHouse集群可以分多个分片,每个分片可以存储数据,这里分片可以理解为ClickHouse机器中的每个节点,1个分片只能对应1服务节点。这里可以配置一个或者任意多个分片,在每个分片中可以配置一个或任意多个副本,不同分片可配置不同数量的副本。如果只是配置一个分片,这种情况下查询操作应该称为远程查询,而不是分布式查询。 |
| 4 | replica | 每个分片的副本,默认每个分片配置了一个副本。也可以配置多个,副本的数量上限是由ClickHouse节点的数量决定的。如果配置了副本,读取操作可以从每个分片里选择一个可用的副本。如果副本不可用,会依次选择下个副本进行连接。该机制利于系统的可用性。 |
| 5 | internal_replication | 默认为false,写数据操作会将数据写入所有的副本,设置为true,写操作只会选择一个正常的副本写入数据,数据的同步在后台自动进行。 |
| 6 | zookeeper | 配置的zookeeper集群,注意:与之前版本不同,之前版本是“zookeeper-servers”。 |
| 7 | macros | 区分每台ClickHouse节点的宏配置,macros中标签代表当前节点的分片号,标签代表当前节点的副本号,这两个名称可以随意取,后期在创建副本表时可以动态读取这两个宏变量。注意:每台ClickHouse节点需要配置不同名称。 |
| 8 | networks | 这里配置ip为“::/0”代表任意IP可以访问,包含IPv4和IPv6。 |
| 9 | ClickHouse_compression | MergeTree引擎表的数据压缩设置,min_part_size:代表数据部分最小大小。min_part_size_ratio:数据部分大小与表大小的比率。method:数据压缩格式。 |
然后我们把这个文件拷贝到node2节点的/etc/clickhouse-server/config.d目录下,再把文件拷贝到node3节点的/etc/clickhouse-server/config.d目录下,示例图如下:
#拷贝到node2节点 sz -r metrika.xml node2:/etc/clickhouse-server/config.d/ #拷贝到node3节点 sz -r metrika.xml node3:/etc/clickhouse-server/config.d/

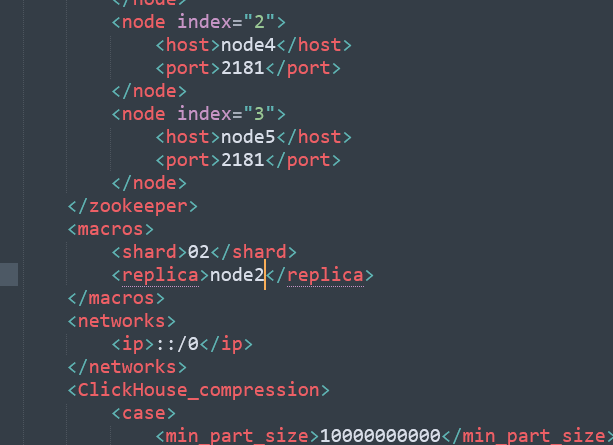
接着我们需要修改node2节点上的/etc/clickhouse-server/config.d/metrika.xml,把macros部分修改为node2的信息,示例如下:
接着我们需要修改node3节点上的/etc/clickhouse-server/config.d/metrika.xml,把macros部分修改为node3的信息,示例如下:
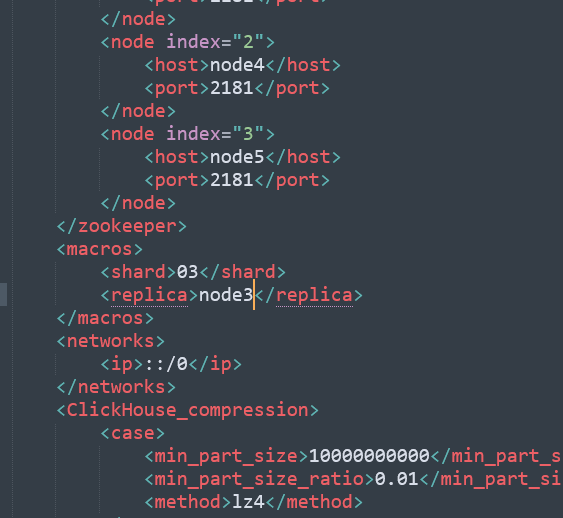
配置完成之后,我们还需要对/etc/clickhouse-server/config.d/metrika.xml文件进行授权,目前各个节点的权限是root,我们需要修改为clickhouse用户权限,所以:
#在node1,node2,node3服务器上分别执行 chown -R clickhouse.clickhouse /etc/clickhouse-server/config.d/metrika.xml
最后我们重启clickhouse
#在node1,node2,node3服务器上分别执行 service clickhouse-server restart
执行完毕之后就启动完成了:

6)测试访问
这里我们在任意台服务器上执行client客户端连接上clickhouse:
#执行连接clickhouse客户端 clickhouse-client
输入之后这里需要输入密码,如下图:
这里的密码是我们在前面安装的时候自动写入文件的密码:/etc/clickhouse-server/users.d/default-password.xml,我们查看这个文件就可以了:
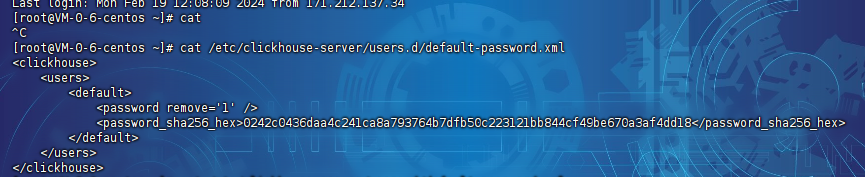
这里的密码是密文的,那么明文怎么看呢?其实这里的sha256加密方式是不可逆的,所以我们重置下密码,这里我们使用123456生成遗传sha256的密码,结果是:
8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92
我们把这个密码放到/etc/clickhouse-server/users.d/default-password.xml文件中,把password给替换掉,实例如下:
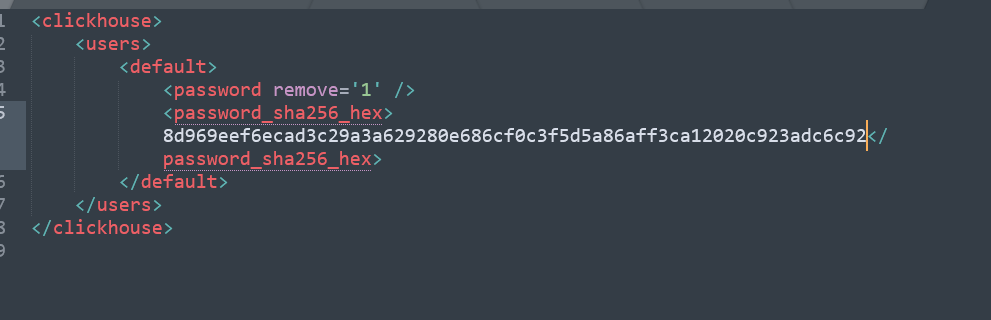
接着再重启clickhouse进行登录即可:
#重启clickhouse service clickhouse-server restart #连接 clickhouse-client
此时出现提示的话,输入:123456就可以进入到clickhouse了,示例图如下:
接着我们执行下sql语句,查看有哪些库:
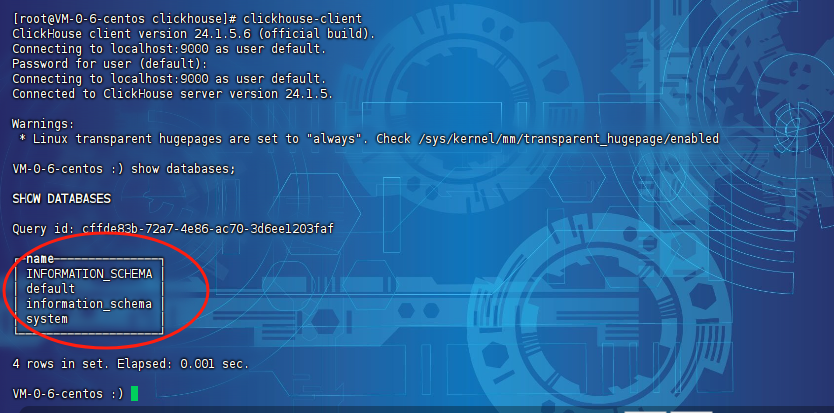
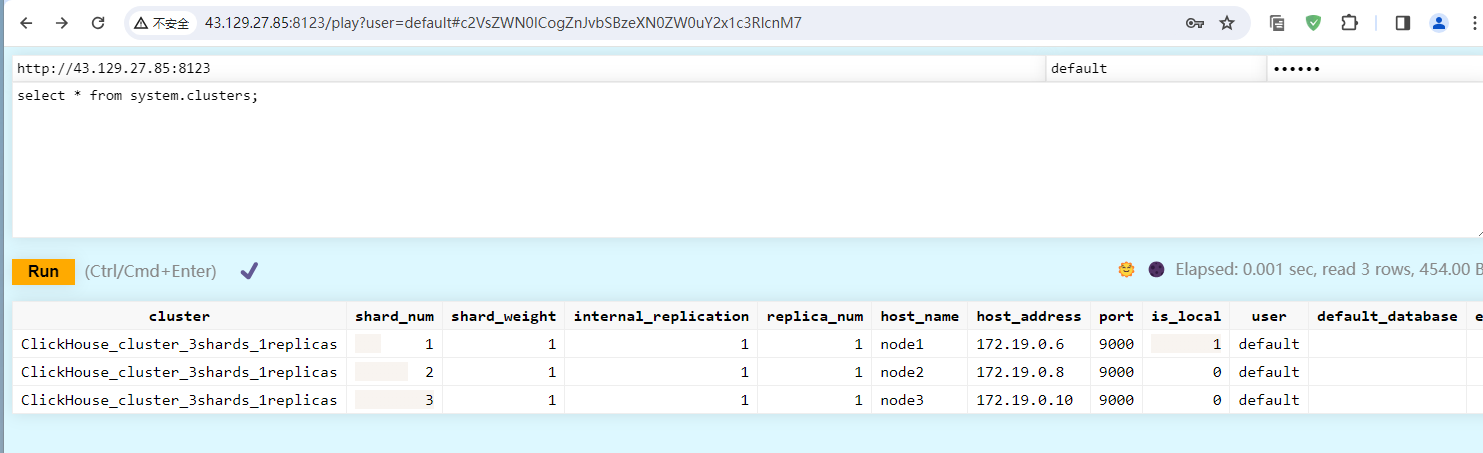
接着我们查询下集群信息:
select * from system.clusters;
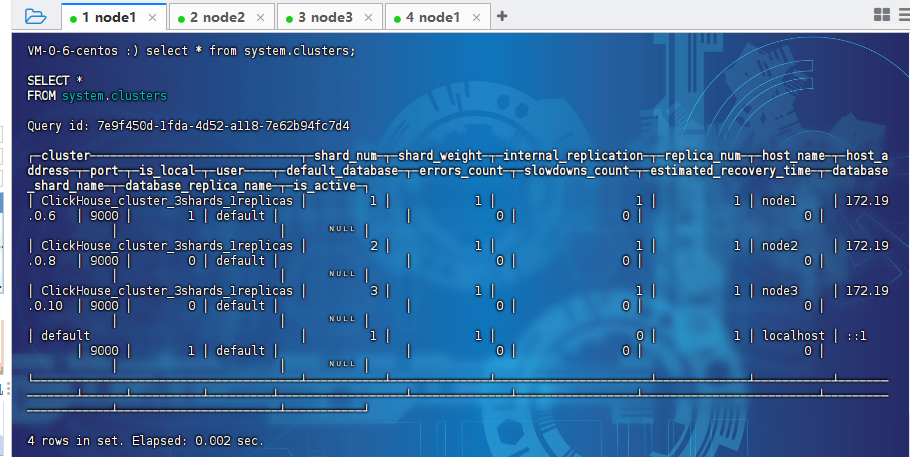
可以看到展示出来了3个节点的信息,但是这里还有一个default的节点,这是我们最开始安装的默认节点。可以暂时不管他。
以上就是我们部署clickhouse集群的完整案例。
备注:
1、这里初始化的密码一般需要重置,如果不想使用123456的话,可以做成自己的密码,在linux服务器上执行如下的命令:
echo -n 密码 | openssl dgst -sha256
他就会生成一串新的密码,

我们把他替换掉原来的加密内容,再重启clickhouse实例就可以用新密码进行登录了。
2、这里使用的是rpm的方式安装,所以安装完成之后,涉及到的关联目录有:
1、/etc/clickhouse-server/ (主要是服务端的配置文件目录) 2、/var/lib/clickhouse/ (主要是服务端的数据存储目录,一般我们要修改下,可以通过/etc/clickhouse-server/config.xml文件进行修改,也可以做软连接) 3、/var/log/clickhouse-server/ (存放日志的地方,可以通过/etc/clickhouse-server/config.xml文件进行修改,也可以做软连接)
以上3个目录是比较重要的,在实际的生产环境中需要根据自身情况进行调整。
3、当然我们还可以通过dashboard访问这里的clickhouse,访问地址是:http://${ip}:8123/play就可以访问了,示例如下:
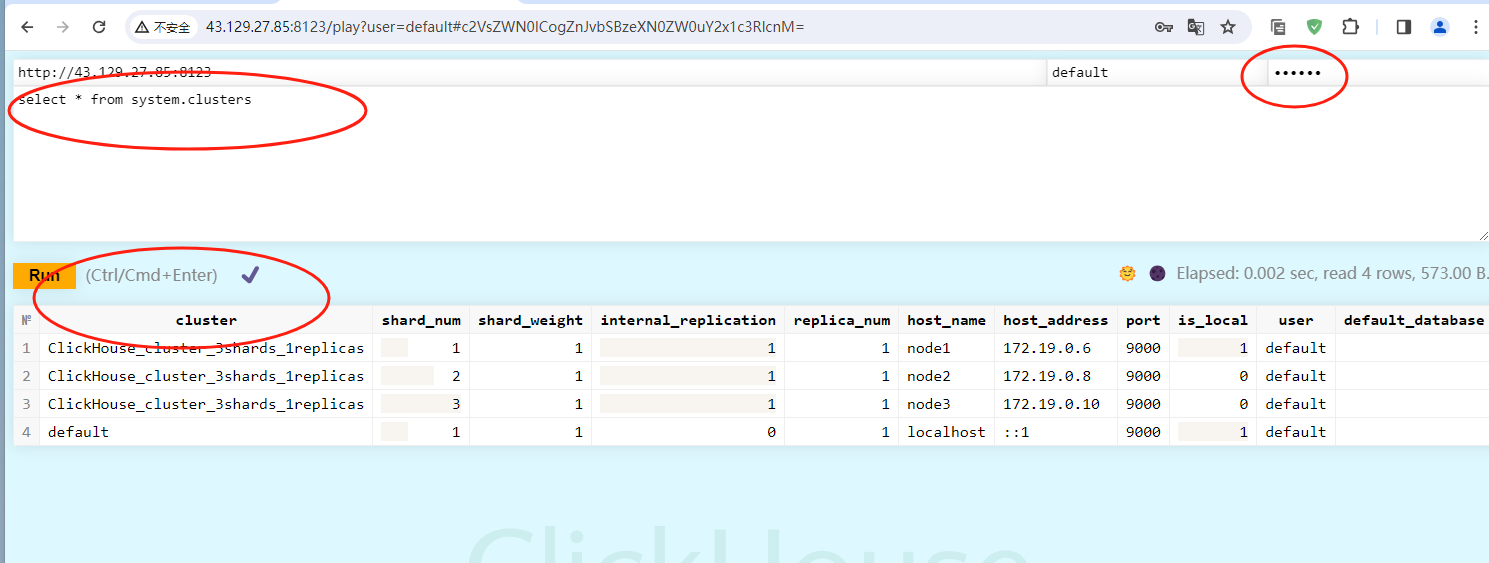
路径一定要添加上/play,不然访问不到这个界面。
4、如果想要移除掉名称为default的cluster的话,可以修改/etc/clickHouse-server/config.xml文件,找到<remote_servers>标签,把default去掉,示例图如下:
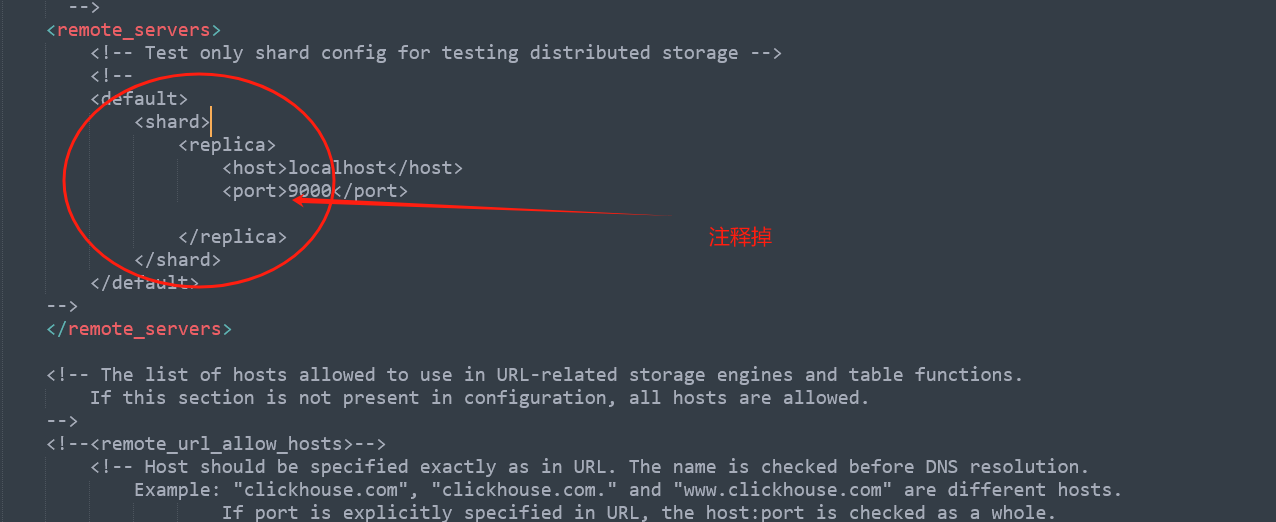
把所有节点的这一部分给去掉后,执行各个节点的重启,然后再查询就没有了:








还没有评论,来说两句吧...