
前面我们已经介绍过了clickhouse基础相关的内容,从本文开始,我们介绍一下clickhouse的一些进阶内容。
在介绍进阶内容的时候,我们要提前准备一个clikhouse的cluster集群。这里我们使用虚拟机已经准备好了一个2个节点的cluster集群,示例如下:
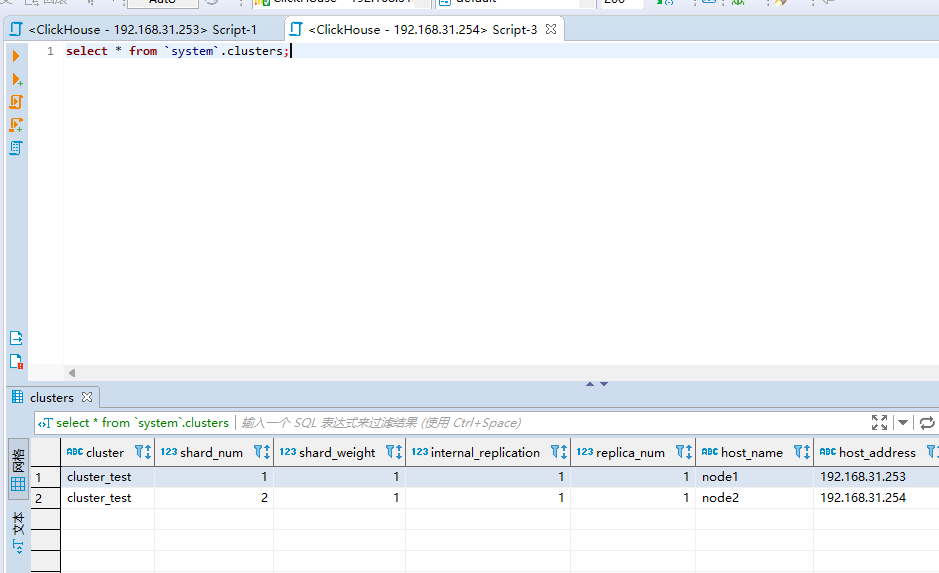
本文主要介绍clickhouse的副本,我们在前面介绍过clickhouse集群是属于分布式的,因此这里的话,整个集群的数据存储有分片和副本的概念。
副本就是某一个分片的备份存储,他与主分片是一样的,对整个集群提供写入与查询能力,一个分片可以用多个副本,不同的副本(包括主分片)都存储在集群不同的节点上,不会存在于集群相同的节点上。
目前在clickhouse里面只有mergetree系列的表引擎才支持副本,同时在创建副本的时候需要在引擎前面加上:Replicated 前缀,组成一种变种的表引擎,实例如下:
create table xxx() engine = ReplicatedMergeTree('${zk_path}','${replica_name}')这里创建变种引擎的话,需要填写2个参数,分别是:
zkpath:指定当前表副本元数据信息的zkpath,这个path自定义即可。 replica_name:指定当前表副本元数据信息的副本名称,也自定义即可。
下面我们来演示一下,示例为:创建一张users的表,然后做成是两个副本。下面开始:
1)首先在node1的clickhouse里面创建一张users表指定表引擎为MergeTree引擎。
create database test;
create table test.users(
id int,
name String,
age int
)engine = ReplicatedMergeTree('/replicate/test/users/','node1')
order by id;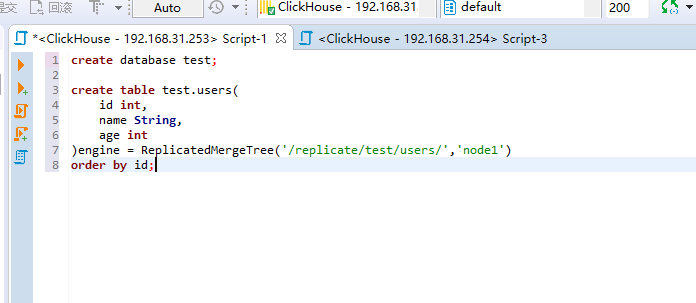
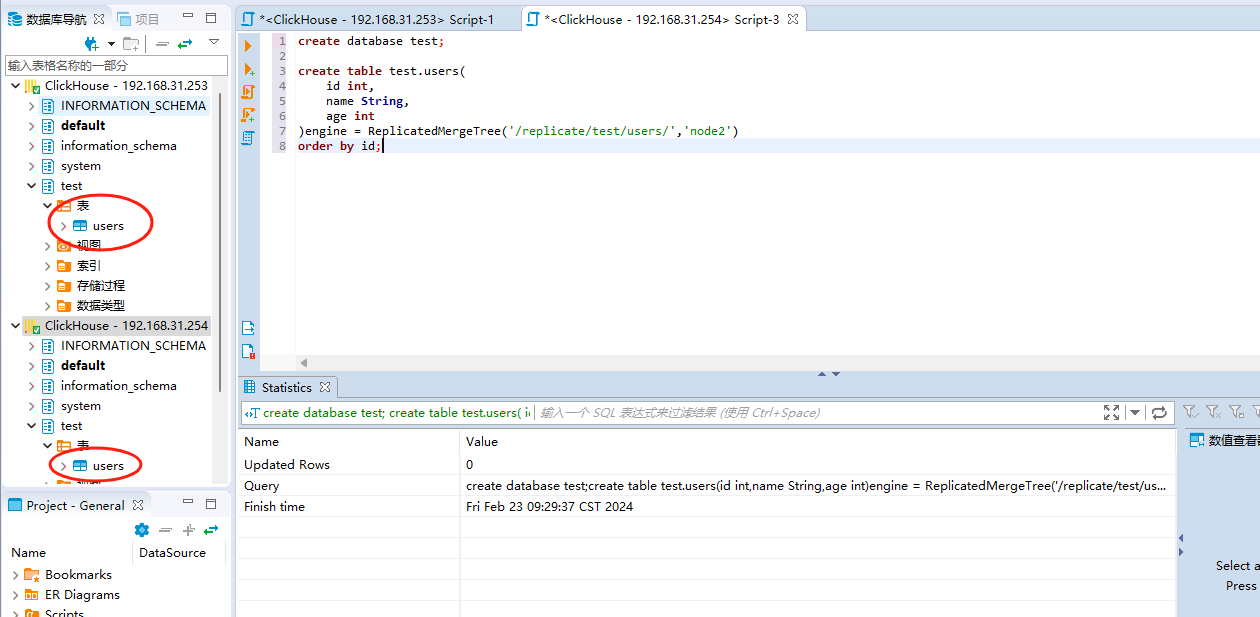
2)接着在node2上的clickhouse里面创建一张users表指定表引擎为MergeTree引擎。
create database test;
create table test.users(
id int,
name String,
age int
)engine = ReplicatedMergeTree('/replicate/test/users/','node2')
order by id;创建完成之后,在node2上也看到有users表信息了:
3)在node1上向users表插入一条数据
insert into test.users values(1,'张三',15);
此时我们可以在node1上查询出来张三的数据:
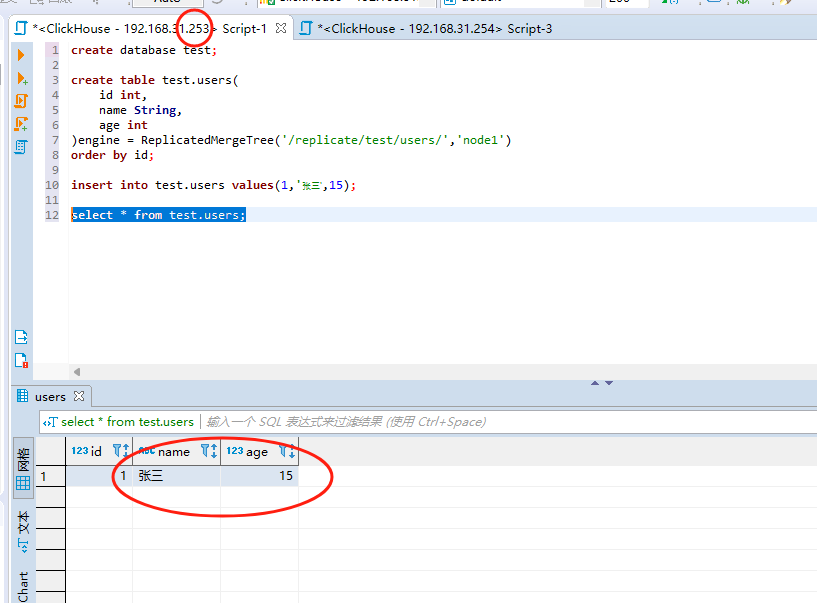
此时我们再去node2上也可以查询出来users表的数据,示例图如下:
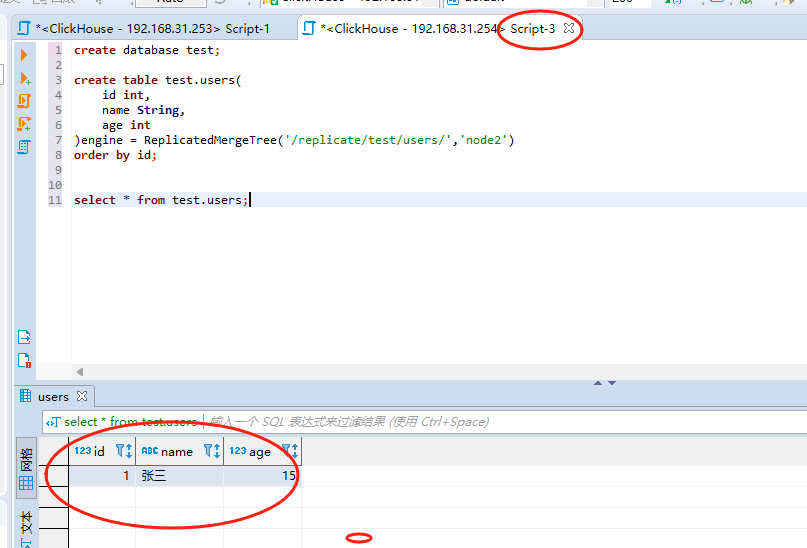
备注:
1、clickhouse如果想要使用副本的话,如果副本是N,那么N个节点上都要创建对应的表,并且指定Replicated信息。(仅限普通方式创建副本) 2、如果只在其中一个节点上创建了这种副本信息,那么在其他节点上是查询不出来数据的。当然他更不会同步数据,例如我们在node1上创建了test.users表,但是在node2上是查询不到对应的表的,更查询不到这里面的数据,示例图如下:(仅限普通方式创建副本)
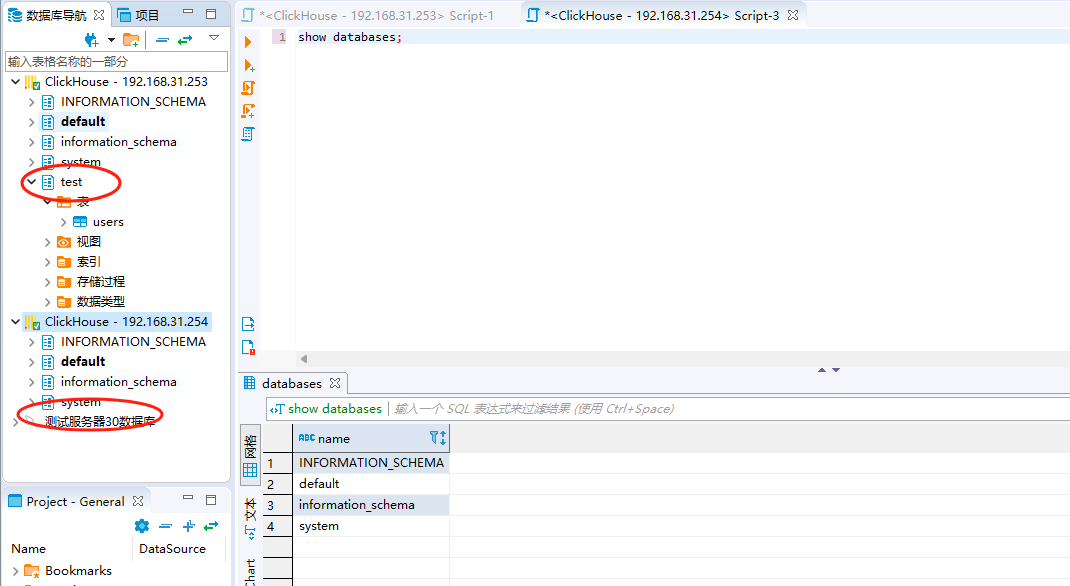
3、在不同节点上创建的副本名称必须要不相同,这样子会在clickhouse相同的目录下创建相关的文件夹保存对应的自身副本信息,供其他节点同步,我们来看看zookeeper存储的元数据信息:

这里在我们指定的zookeeper目录下有很多元数据文件,所有分片相关的元数据信息都在此目录下,例如我们想看副本有哪些节点,可以查看这里的replicas目录,示例如下:

如果要查看主副本信息,可以查看leader_election节目录,示例如下;

如果要查看其他信息,都可以挨个遍历下这里的目录。
4、这里创建的副本的方式是其中一种方式,在下一篇介绍分片的时候,我们可以不用在每个节点挨个去创建副本。
以上就是clickhouse关于副本相关的介绍。








还没有评论,来说两句吧...